1 混淆矩阵

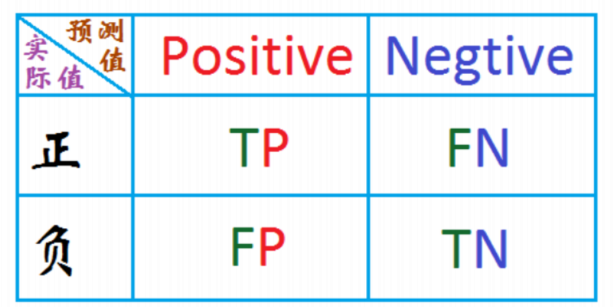


2 实例

3 代码实验
from sklearn.metrics import accuracy_score # 准确率 y_pred = [0, 2, 1, 3] y_true = [0, 1, 2, 3] print(accuracy_score(y_true, y_pred))
0.5

from sklearn.metrics import precision_score # 精确率 y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1] #宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。 #微平均(Micro-averaging),是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标。 print(precision_score(y_true, y_pred, average='macro')) print(precision_score(y_true, y_pred, average='micro'))
0.2222222222222222 0.3333333333333333
from sklearn.metrics import recall_score # 召回率 y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1] print(recall_score(y_true, y_pred, average='macro')) # 0.3333333333333333 print(recall_score(y_true, y_pred, average='micro')) # 0.3333333333333333
0.3333333333333333 0.3333333333333333
from sklearn.metrics import f1_score # 调和平均值 y_true = [0, 1, 2, 0, 1, 2] y_pred = [0, 2, 1, 0, 0, 1] print(f1_score(y_true, y_pred, average='macro')) print(f1_score(y_true, y_pred, average='micro'))
0.26666666666666666 0.3333333333333333
4 实例小结

5 扩展点

6 特征工程总结


7 相关问题解答

