来源:https://mp.weixin.qq.com/s/ECe_bn9HzFzXTlfEnAaLBg
4 Flink upsert-kafka连接器
4.1 Upsert Kafka connector简介
Upsert Kafka Connector允许用户以upsert的方式从Kafka主题读取数据或将数据写入Kafka主题。
当作为数据源时,upsert-kafka Connector会生产一个changelog流,其中每条数据记录都表示一个更新或删除事件。更准确地说,如果不存在对应的key,则视为INSERT操作。如果已经存在了相对应的key,则该key对应的value值为最后一次更新的值。
用表来类比,changelog 流中的数据记录被解释为 UPSERT,也称为 INSERT/UPDATE,因为任何具有相同 key 的现有行都被覆盖。另外,value 为空的消息将会被视作为 DELETE 消息。
当作为数据汇时,upsert-kafka Connector会消费一个changelog流。它将INSERT / UPDATE_AFTER数据作为正常的Kafka消息值写入(即INSERT和UPDATE操作,都会进行正常写入,如果是更新,则同一个key会存储多条数据,但在读取该表数据时,只保留最后一次更新的值),并将 DELETE 数据以 value 为空的 Kafka 消息写入(key被打上墓碑标记,表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中
4.2 依赖
为了使用Upsert Kafka连接器,需要添加下面的依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.12</artifactId> <version>1.12.0</version> </dependency>
如果使用SQL Client,需要下载flink-sql-connector-kafka_2.11-1.12.0.jar,并将其放置在Flink安装目录的lib文件夹下。
4.3 使用方式
使用样例
-- 创建一张kafka表,用户存储sink的数据 CREATE TABLE pageviews_per_region ( user_region STRING, pv BIGINT, uv BIGINT, PRIMARY KEY (user_region) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'pageviews_per_region', 'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092', 'key.format' = 'avro', 'value.format' = 'avro' );
尖叫提示:
要使用 upsert-kafka connector,必须在创建表时使用PRIMARY KEY定义主键,并为键(key.format)和值(value.format)指定序列化反序列化格式。
upsert-kafka connector参数
- connector
必选。指定要使用的连接器,Upsert Kafka 连接器使用:'upsert-kafka'。
- topic
必选。用于读取和写入的 Kafka topic 名称。
- properties.bootstrap.servers
必选。以逗号分隔的 Kafka brokers 列表。
- key.format
必选。用于对 Kafka 消息中 key 部分序列化和反序列化的格式。key 字段由 PRIMARY KEY语法指定。支持的格式包括 'csv'、'json'、'avro'。
- value.format
必选。用于对 Kafka 消息中 value 部分序列化和反序列化的格式。支持的格式包括 'csv'、'json'、'avro'。
- *properties. **
可选。该选项可以传递任意的 Kafka 参数。选项的后缀名必须匹配定义在 Kafka 参数文档中的参数名。Flink 会自动移除 选项名中的 "properties." 前缀,并将转换后的键名以及值传入 KafkaClient。例如,你可以通过 'properties.allow.auto.create.topics' = 'false'来禁止自动创建 topic。但是,某些选项,例如'key.deserializer' 和 'value.deserializer' 是不允许通过该方式传递参数,因为 Flink 会重写这些参数的值。
- value.fields-include
可选,默认为ALL。控制key字段是否出现在 value 中。当取ALL时,表示消息的 value 部分将包含 schema 中所有的字段,包括定义为主键的字段。当取EXCEPT_KEY时,表示记录的 value 部分包含 schema 的所有字段,定义为主键的字段除外。
- key.fields-prefix
可选。为了避免与value字段命名冲突,为key字段添加一个自定义前缀。默认前缀为空。一旦指定了key字段的前缀,必须在DDL中指明前缀的名称,但是在构建key的序列化数据类型时,将移除该前缀。见下面的示例。在需要注意的是:使用该配置属性,value.fields-include的值必须为EXCEPT_KEY。
-- 创建一张upsert表,当指定了qwe前缀,涉及的key必须指定qwe前缀 CREATE TABLE result_total_pvuv_min_prefix ( qwedo_date STRING, -- 统计日期,必须包含qwe前缀 qwedo_min STRING, -- 统计分钟,必须包含qwe前缀 pv BIGINT, -- 点击量 uv BIGINT, -- 一天内同个访客多次访问仅计算一个UV currenttime TIMESTAMP, -- 当前时间 PRIMARY KEY (qwedo_date, qwedo_min) NOT ENFORCED -- 必须包含qwe前缀 ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'result_total_pvuv_min_prefix', 'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092', 'key.json.ignore-parse-errors' = 'true', 'value.json.fail-on-missing-field' = 'false', 'key.format' = 'json', 'value.format' = 'json', 'key.fields-prefix'='qwe', -- 指定前缀qwe 'value.fields-include' = 'EXCEPT_KEY' -- key不出现kafka消息的value中 ); -- 向该表中写入数据 INSERT INTO result_total_pvuv_min_prefix SELECT do_date, -- 时间分区 cast(DATE_FORMAT (access_time,'HH:mm') AS STRING) AS do_min,-- 分钟级别的时间 pv, uv, CURRENT_TIMESTAMP AS currenttime -- 当前时间 from view_total_pvuv_min;
尖叫提示:
如果指定了key字段前缀,但在DDL中并没有添加该前缀字符串,那么在向该表写入数时,会抛出下面异常:
[ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: All fields in 'key.fields' must be prefixed with 'qwe' when option 'key.fields-prefix' is set but field 'do_date' is not prefixed.
- sink.parallelism
可选。定义 upsert-kafka sink 算子的并行度。默认情况下,由框架确定并行度,与上游链接算子的并行度保持一致。
4.4 其他注意事项
Key和Value的序列化格式
关于Key、value的序列化可以参考Kafka connector。值得注意的是,必须指定Key和Value的序列化格式,其中Key是通过PRIMARY KEY指定的。
Primary Key约束
Upsert Kafka 工作在 upsert 模式(FLIP-149)下。当我们创建表时,需要在 DDL 中定义主键。具有相同key的数据,会存在相同的分区中。在 changlog source 上定义主键意味着在物化后的 changelog 上主键具有唯一性。定义的主键将决定哪些字段出现在 Kafka 消息的 key 中。
一致性保障
默认情况下,如果启用 checkpoint,Upsert Kafka sink 会保证至少一次将数据插入 Kafka topic。
这意味着,Flink 可以将具有相同 key 的重复记录写入 Kafka topic。但由于该连接器以 upsert 的模式工作,该连接器作为 source 读入时,可以确保具有相同主键值下仅最后一条消息会生效。因此,upsert-kafka 连接器可以像 HBase sink 一样实现幂等写入。
分区水位线
Flink 支持根据 Upsert Kafka 的 每个分区的数据特性发送相应的 watermark。当使用这个特性的时候,watermark 是在 Kafka consumer 内部生成的。合并每个分区生成的 watermark 的方式和 streaming shuffle 的方式是一致的(单个分区的输入取最大值,多个分区的输入取最小值)。数据源产生的 watermark 是取决于该 consumer 负责的所有分区中当前最小的 watermark。如果该 consumer 负责的部分分区是空闲的,那么整体的 watermark 并不会前进。在这种情况下,可以通过设置合适的 table.exec.source.idle-timeout 来缓解这个问题。
数据类型
Upsert Kafka 用字节bytes存储消息的 key 和 value,因此没有 schema 或数据类型。消息按格式进行序列化和反序列化,例如:csv、json、avro。不同的序列化格式所提供的数据类型有所不同,因此需要根据使用的序列化格式进行确定表字段的数据类型是否与该序列化类型提供的数据类型兼容。
4.5 使用案例
本文以实时地统计网页PV和UV的总量为例,介绍upsert-kafka基本使用方式:
- Kafka 数据源
用户的ippv信息,一个用户在一天内可以有很多次pv
CREATE TABLE source_ods_fact_user_ippv ( user_id STRING, -- 用户ID client_ip STRING, -- 客户端IP client_info STRING, -- 设备机型信息 pagecode STRING, -- 页面代码 access_time TIMESTAMP, -- 请求时间 dt STRING, -- 时间分区天 WATERMARK FOR access_time AS access_time - INTERVAL '5' SECOND -- 定义watermark ) WITH ( 'connector' = 'kafka', -- 使用 kafka connector 'topic' = 'user_ippv', -- kafka主题 'scan.startup.mode' = 'earliest-offset', -- 偏移量 'properties.group.id' = 'group1', -- 消费者组 'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092', 'format' = 'json', -- 数据源格式为json 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true' );
- Kafka Sink表
统计每分钟的PV、UV,并将结果存储在Kafka中
CREATE TABLE result_total_pvuv_min ( do_date STRING, -- 统计日期 do_min STRING, -- 统计分钟 pv BIGINT, -- 点击量 uv BIGINT, -- 一天内同个访客多次访问仅计算一个UV currenttime TIMESTAMP, -- 当前时间 PRIMARY KEY (do_date, do_min) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'result_total_pvuv_min', 'properties.bootstrap.servers' = 'kms-2:9092,kms-3:9092,kms-4:9092', 'key.json.ignore-parse-errors' = 'true', 'value.json.fail-on-missing-field' = 'false', 'key.format' = 'json', 'value.format' = 'json', 'value.fields-include' = 'EXCEPT_KEY' -- key不出现kafka消息的value中 );
计算逻辑
-- 创建视图 CREATE VIEW view_total_pvuv_min AS SELECT dt AS do_date, -- 时间分区 count (client_ip) AS pv, -- 客户端的IP count (DISTINCT client_ip) AS uv, -- 客户端去重 max(access_time) AS access_time -- 请求的时间 FROM source_ods_fact_user_ippv GROUP BY dt; -- 写入数据 INSERT INTO result_total_pvuv_min SELECT do_date, -- 时间分区 cast(DATE_FORMAT (access_time,'HH:mm') AS STRING) AS do_min,-- 分钟级别的时间 pv, uv, CURRENT_TIMESTAMP AS currenttime -- 当前时间 from view_total_pvuv_min;
生产用户访问数据到kafka,向kafka中的user_ippv插入数据:
{"user_id":"1","client_ip":"192.168.12.1","client_info":"phone","pagecode":"1001","access_time":"2021-01-08 11:32:24","dt":"2021-01-08"}
{"user_id":"1","client_ip":"192.168.12.1","client_info":"phone","pagecode":"1201","access_time":"2021-01-08 11:32:55","dt":"2021-01-08"}
{"user_id":"2","client_ip":"192.165.12.1","client_info":"pc","pagecode":"1031","access_time":"2021-01-08 11:32:59","dt":"2021-01-08"}
{"user_id":"1","client_ip":"192.168.12.1","client_info":"phone","pagecode":"1101","access_time":"2021-01-08 11:33:24","dt":"2021-01-08"}
{"user_id":"3","client_ip":"192.168.10.3","client_info":"pc","pagecode":"1001","access_time":"2021-01-08 11:33:30","dt":"2021-01-08"}
{"user_id":"1","client_ip":"192.168.12.1","client_info":"phone","pagecode":"1001","access_time":"2021-01-08 11:34:24","dt":"2021-01-08"}
查询结果表:
select * from result_total_pvuv_min;

可以看出:每分钟的pv、uv只显示一条数据,即代表着截止到当前时间点的pv和uv
查看Kafka中result_total_pvuv_min主题的数据,如下:
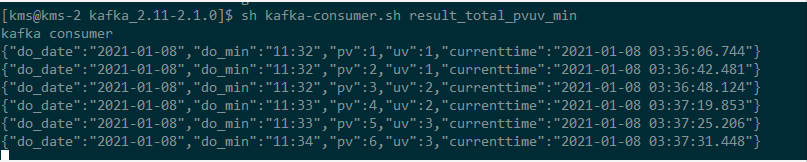
可以看出:针对每一条访问数据,触发计算了一次PV、UV,每一条数据都是截止到当前时间的累计PV和UV。
尖叫提示:
默认情况下,如果在启用了检查点的情况下执行查询,Upsert Kafka接收器会将具有至少一次保证的数据提取到Kafka主题中。
这意味着,Flink可能会将具有相同键的重复记录写入Kafka主题。但是,由于连接器在upsert模式下工作,因此作为源读回时,同一键上的最后一条记录将生效。因此,upsert-kafka连接器就像HBase接收器一样实现幂等写入。