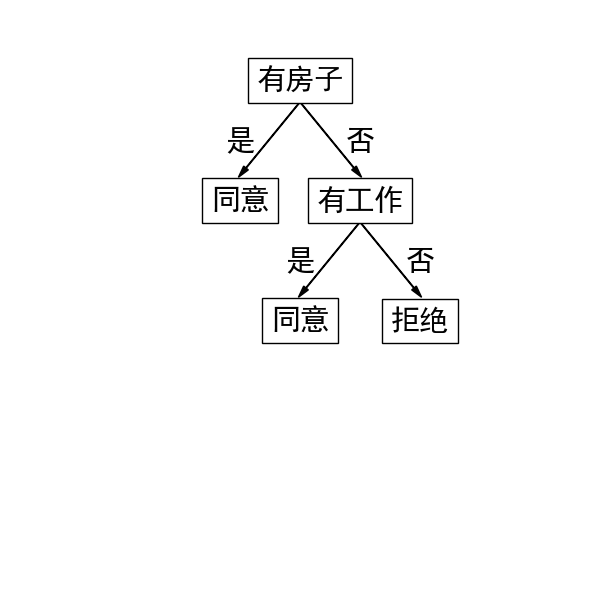
决策树的生成,采用ID3算法(也包含了C4.5算法),使用python实现,更新了tree的保存和图示。
介绍摘自李航《统计学习方法》。
5.2.3 信息增益比
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义。在分类问题困难时,也就是说在训练数据集的经验熵大的时候,信息增益值会偏大。反之,信息增益值会偏小。使用信息增益比(information gain ratio)可以对这一问题进行校正。这是特征选择的另一准则。
定义5.3(信息增益比) 特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D的经验熵H(D)之比:

5.3.2 C4.5的生成算法
C4.5算法与ID3算法相似,C4.5算法对ID3算法进行了改进。C4.5在生成的过程中,用信息增益比来选择特征。
算法5.3(C4.5的生成算法)
输入:训练数据集D,特征集A,阈值ε;
输出:决策树T。
(1)如果D中所有实例属于同一类Ck,则置T为单结点树,并将Ck作为该结点的类,返回T;
(2)如果A=Ø,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(3)否则,按式(5.10)计算A中各特征对D的信息增益比,选择信息增益比最大的特征Ag;
(4)如果Ag的信息增益比小于阈值,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(5)否则,对Ag的每一可能值ai,依Ag=ai将D分割为子集若干非空Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对结点i,以Di为训练集,以A-{Ag}为特征集,递归地调用步(1)~步(5),得到子树Ti,返回Ti。
1 # coding:utf-8 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import pylab 5 6 def createDataSet(): #贷款申请样本数据表 7 dataset = [["青年", "否", "否", "一般", "拒绝"], 8 ["青年", "否", "否", "好", "拒绝"], 9 ["青年", "是", "否", "好", "同意"], 10 ["青年", "是", "是", "一般", "同意"], 11 ["青年", "否", "否", "一般", "拒绝"], 12 ["中年", "否", "否", "一般", "拒绝"], 13 ["中年", "否", "否", "好", "拒绝"], 14 ["中年", "是", "是", "好", "同意"], 15 ["中年", "否", "是", "非常好", "同意"], 16 ["中年", "否", "是", "非常好", "同意"], 17 ["老年", "否", "是", "非常好", "同意"], 18 ["老年", "否", "是", "好", "同意"], 19 ["老年", "是", "否", "好", "同意"], 20 ["老年", "是", "否", "非常好", "同意"], 21 ["老年", "否", "否", "一般", "拒绝"], 22 ] 23 labels = ["年龄", "有工作", "有房子", "信贷情况"] 24 return dataset, labels 25 26 def getList(dataset,index=-1):#返回每层列表 27 alist=[i[index] for i in dataset] 28 aset=list(set(alist)) 29 acount=[alist.count(aset[j]) for j in range(len(aset))] 30 return alist,aset,acount 31 32 def getdH(account): #计算H(D) 33 t=np.sum(account) 34 return np.sum([-float(a)/t*np.log2(float(a)/t) for a in account]) 35 36 def getdaH(acount,ad): #计算H(D,A) 37 t=np.sum(acount) 38 return np.sum([[0 if j==0 else -a*float(j)/t/a*np.log2(float(j)/a) for j in b] for a,b in zip(acount,ad)]) 39 40 def gethaD(acount): #计算Ha(D) 41 t=np.sum(acount) 42 return np.sum([ -float(a)/t*np.log2(float(a)/t) for a in acount]) 43 44 def getaH(dataset,index,c4_5=0): #计算g(D,A),若c4_5=1则采用信息增益比 45 dlist,dset,dcount= getList(dataset,-1) 46 hd=getdH(dcount) 47 alist,aset,acount=getList(dataset,index) 48 ad=[[[dlist[i] for i in range(len(dlist)) if dataset[i][index]==j].count(k) for k in dset] for j in aset] 49 if c4_5: 50 return 0 if gethaD(acount)==0 else (hd-getdaH(acount,ad))/gethaD(acount) 51 else: 52 return hd-getdaH(acount,ad) 53 54 def ID3(dataset,labels,tree=[]):#ID3算法 55 dlist,dset,dcount= getList(dataset,-1) 56 if len(dset)<2 : 57 tree.append([dset[0],0]) 58 return 59 adlist=[[getaH(dataset,i),i] for i in range(len(dataset[0])-1)] 60 t1= max(adlist,key=lambda x: x[0]) 61 tree.append([labels[t1[1]],2]) 62 alist,aset,acount=getList(dataset,t1[1]) 63 for a in aset: 64 tree.append([a,1]) 65 ID3([i for i in dataset if i[t1[1]]==a],labels,tree) 66 return tree 67 68 def showT(tree):#根据Tree列表绘制图像 69 import sys 70 reload(sys) 71 sys.setdefaultencoding('utf-8') 72 pylab .mpl.rcParams['font.sans-serif'] = ['SimHei'] 73 fig1 = plt.figure(1, (6, 6)) 74 ax = fig1.add_axes([0, 0, 1, 1], frameon=False, aspect=1.) 75 x,y=0.5,0.85 76 for i in range(len(tree)): 77 if tree[i][1]==2: 78 fig1.text(x,y, tree[i][0],ha="center",size=21,bbox=dict(boxstyle="square", fc="w", ec="k")) 79 ax.arrow(x,y-0.02, 0.09,-0.11, head_width=0.01, head_length=0.02, fc='k', ec='k') 80 ax.arrow(x,y-0.02, -0.09,-0.11, head_width=0.01, head_length=0.02, fc='k', ec='k') 81 x+=0.05 82 y-=0.1 83 if i>1:tree[i-2][1]-=1 84 elif tree[i][1]==1: 85 fig1.text(x+0.05,y, tree[i][0],ha="center",size=21) 86 x+=0.05 87 y-=0.1 88 else: 89 fig1.text(x,y, tree[i][0],ha="center",size=21,bbox=dict(boxstyle="square", fc="w", ec="k")) 90 x-=0.25 91 y+=0.1 92 j=i-2 93 while tree[j][1]==0: 94 j=j-2 95 x+=0.1 96 y+=0.2 97 tree[j][1]-=1 98 ax.xaxis.set_visible(False) 99 ax.yaxis.set_visible(False) 100 plt.draw() 101 plt.show() 102 103 dataset,labels=createDataSet() 104 tree= ID3(dataset,labels) #[["有房子",2],["否",1],["有工作",2],["否",1],["拒绝",0],["是",1],["同意",0],["是",1],["同意",0]] 105 showT(tree)