第一部分
第3章 数据链路层
3.1 使用点对点信道的数据链路层
3.1.1 数据链路和帧
3.1.2 三个基本问题
数据据链路层的三个基本问题(3.1.2,P71)
数据链路层要解决的问题中,有三个是最基本的,也是必须要解决的。这三个基本问题是: 封装成帧、透明传输和差错检测。
差错检测(3.1.2,P74-75)
-
比特差错:前已述及,通信的最基本数据单位是比特,即一个二进制位。由于现实的通信链路都不会是理想的,总会存在噪声或其他干扰,这就会造成发送端发送的数据在接收端不能正确接收。这就是说,比特在传输过程中可能会产生差错: 1可能会变成0,而0也可能变成1。这样的差错称为比特差错。
注:理论上讲,传输过程中也可能会出现丢失比特或多出比特的情形,但实际的物理层传输技术使得这些情况几乎不可能发生。因此,网络中讨论差错问题是以接收方可以收到发送方发送的同等数量的比特位为前提的。 -
误码率:在一段时间内,传输错误的比特占所传输比特总数的比率称为误码率BER (Bit Error Rate)。
-
差错检测与差错纠正:保证数据传输的正确性,是计算机网络可靠从而可用的基本要求。因此,在网络传输中必须设法处理比特差错问题。其中对差错进行检测的技术称为差错检测(error detection),而对差错进行纠正的技术称为差错纠正(error correction)。本课程将只讨论差错检测技术。
-
差错检测的定义:差错检测(error detection),是指在发送的码序列(码字)中加入适当的冗余位以使得接收端能够发现传输中是否发生差错的技术。除了用于通信外,差错检测技术也广泛用于信息存储中。
注:这里的码字来自于英文的code word,指的是具有一定位数的二进制位序列。 -
差错检测的一般原理:差错检测的一般原理如下图所示。
发送端将要发送的数据先构造为网络层的数据报(datagram),该数据报可以看成是d个数据位(data bits)的数据D。
发送端和接收端协商一种差错检测方法,即差错检测算法,该算法以数据D为输入数据,计算出一个称为EDC(Error Detection Code, 差错检测码)的结果,发送端将EDC附在数据D的后面,发送到链路上。
由于EDC是用数据D计算出来的,故称为冗余码(redundancy code)。
EDC的数据位数应远小于数据D的位数,以免占用过多的网络带宽,造成吞吐量的显著降低。
发送端将加了EDC的数据发到链路上,而链路通常是可能产生比特差错的,即bit-error prone link。
接收端收到的将是可能出现了比特差错的数据D'和差错检测码EDC'。
注1:数据D和差错检测码都可能出错!
注2:D'的位数将会与D相同,而EDC'的位数将会与EDC相同。
接收端将根据协商的差错检测算法判断D'和EDC'是否是一致的(all bits in D' OK?),如果不一致(N),则报告检测到了错误(detected error)。如果一致(Y),则将数据作为数据报(datagram)交给网络层。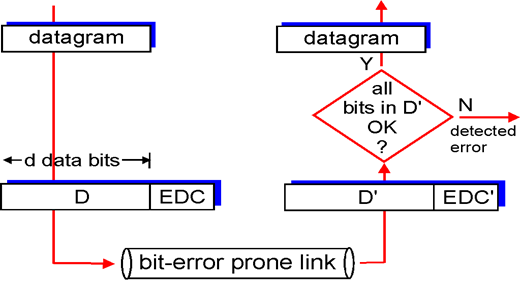
-
常见的差错检测算法:常见的差错检测算法有奇偶校验(parity check)、循环冗余检验(Cyclic Redundancy Check, CRC)和检查和(check sum)算法。我们将在这里介绍奇偶校验和循环冗余检验算法,而检查和算法将在第4章网络层中介绍。
ASCII码表概述
在介绍奇偶校验前,我们先介绍一下ASCII码表。ASCII码表将在本课程后面有深刻的应用,在其他通信和计算机有关的课程以及今后的工作中,都会时不常地用到ASCII码表,因此花些时间深入了解并掌握ASCII码表是很有必要的。
ASCII码表的英文全称是American Standard Code for Information Interchange,中文翻译是美国信息交换标准代码。ASCII码表在计算机和通信发展的历程中起了非常重要的作用,直到今天它依然具有很重要的作用。
ASCII码表的基本思路是将常用的英文符号,包括大小写字母、数字、标点符号等编成一个标准的编码表,这样在通信和存储时,就只需要传输和保存字符的编码而不是形状。通信双方通过编码相同认可传输了相同的字符。
ASCII码表是一个7位(二进制位)的编码表,因而总共可以对128个符号进行编码。
百度百科上以更详尽的方式列出了ASCII码表,参见:百度百科ASCII码表。
由于该表较长,我们在此只截取表头以便解释
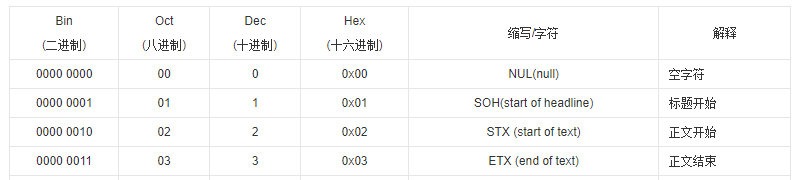
ASCII码表的特点
-
ASCII码表是一个7位的字符编码表,因而其十进制范围是0~127,十六进制范围是0x00~0x7F,二进制范围是0000000~1111111,即7个0到7个1,总的编码数是128。
注1:我们遵循十六进制前加0x的规范;
注2:有些教材或表中将ASCII码描述为8位二进制的,这时最高位总是0。 -
ASCII码表的有形符号是编码在十进制32~126之间的95个符号,十进制0~31(0x00~0x1F)之间的32个符号,为控制字符,最后一个符号,即编码为127(0x7F)的符号也是一个控制字符。
-
控制字符中特别需要记住的是编码为10(0x0A)和13(0x0D)的字符,它们分别是换行符LF(Line Feed)和回车符CR(Carriage Return)。
-
有形符号特别要记住的是第一个和第二个有形符号,它们分别是编码为32(0x20)和33(0x21)的空格和惊叹号。
-
需要记住数字0~9的编码是48~57(0x30~0x39)。
-
需要记住第一个大写字母A的编码是65(0x41),其余大写字母从66(0x42)顺序编码。
-
需要记住小写字母的编码比其对应的大写字母的编码大32(0x20),即小写字母a的编码是97(0x61),其余小写字母从98(0x62)顺序编码。
奇偶校验(parity check)
-
奇偶校验的原理:在数据(即码字)的末尾增加一个冗余的二进制位0或1,使总的数据中1的个数为奇数个或偶数个。
-
奇偶校验示例:奇偶校验常取长度为7的码字,示例如下:
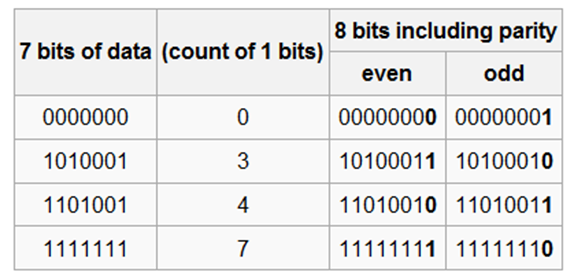
注1:“偶校验”对应的英文是even;“奇校验”对应的英文是odd。
注2:标准ASCII码是7位编码,加上奇或偶校验位后为8位,正好一个字节。 -
奇偶校验的检错能力:奇偶校验能够检测出任何的奇数位错误,但不能检测出任何的偶数位错误。
注1:任何的差错检测算法都存在“漏检”或“误检”的问题,即将发生了比特差错的数据认为是正确的没有差错的数据,但是人们已经找到了像CRC这样“误检”率极低的差错检测算法。
注2:另一方面,任何的差错检测算法,如果检测出数据中有差错,则数据中必有差错,不会出现正确的数据被认为是有差错数据的情况。
循环冗余检验(Cyclic Redundancy Check, CRC)
-
CRC概述:CRC是一种建立在二进制数据的多项式表示及模2运算基础上的差错检测算法,CRC算法基于严谨的数学运算,具有很高的差错检测能力,而且可以很容易地用移位寄存器硬件实现,因而广泛地应用于计算机网络数据链路层的差错检测和计算机外部存储器(硬盘)的数据校验中。
-
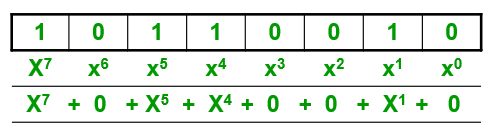
CRC基础—二进制数据的多项式表示:将二进制数据的每个位赋予一个与位的位置对应的
的幂次,从低到高依次为:
。每个幂次项对应的系数即是其对应位的二进制值0或1,而对应位为0值的项即为0。如,二进制数据10110010对应的多项式示意如下:
-
CRC基础—模2算术运算:二进制的模2算术运算指的是加法无进位、减法无借位的二进制算术运算。示例如下:
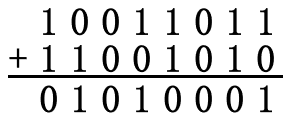
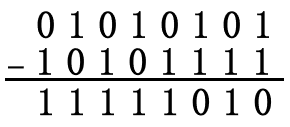
注1:所谓模2,意思是说加法的结果是两数加起来的和除以2的余数,即结果为0或1,且不考虑进位。
注2:二进制的模2运算相当于二进制的异或(XOR)运算。若a、b为1位二进制数据,则a XOR b的运算规则为:当a与b相同,即同为1或0,时,结果为0,当a与b不相同,即一个是0另一个是1时,结果为1。
注3:在模2运算中,加法与减法相同。 -
CRC计算的前提:一个m比特的原始数据,如101001,它可以表示成如下所示的多项式:
;
注意:的最高次幂为m-1。
一个对应生成多项式的二进制位串,如1101,它对应的多项式为:。
设该生成多项式的度为r,则其对应的二进制位数为r+1。
注:多项式的度为多项式的最高次项的指数。 -
CRC检验码生成过程的数学表达:
首先将原始数据左移r位,r为生成多项式的度,得;
其次以模2除法用去除
,则
最后发送的数据为多项式对应的二进制位串。
-
CRC检验码检测过程的数学表达:
假设收到的数据,即二进制位串,对应的多项式为,则用生成多项式
-
CRC算法正确性的数学证明:
前已述及,用,则有:
。
我们将。
由于模2运算中,减法与加法相同,于是我们有:。
可以看出,上式左边就是我们发送的加了CRC校验码的数据。
上式说明
于是,若接收方收到的数据,则我们用
注1:接收方不是去验证也得到一个与发送端计算的相同的余数
注2:尽管上述分析中用到了 -
CRC算法的演示:CRC算法的计算过程可以用下面所示的长除法来演示:
该例子中,原始数据为101001,生成多项式为1101,它对应的度为3;
注意:图中用n而不是r表示生成多项式的度。
计算时,先在原始数据后添加生成多项式度数个0,本例中添加3个0。
注:二进制数据右侧添加r个0,就是左移r位。
然后,我们就用小学中学习的长除法进行除法运算。
特别注意:这里的除法是模2除法,即减法无借位。
最后,得到的余数001就是CRC校验码,也就是说,最终发送的带校验码的数据为101001001。
同学们可以验证一下,用同样的长除法运算过程,以模2运算计算101001001除以生成多项式1101的余数为0。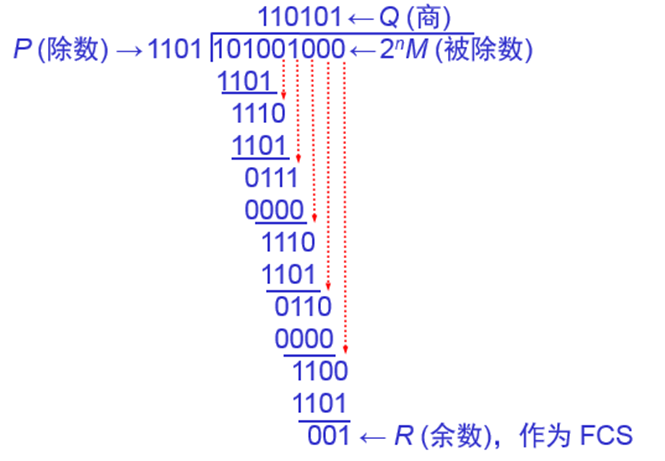
标准的CRC生成多项式:
生成多项式是CRC算法的关键,人们已经找到了一些检错率很高的生成多项式,并将它们制定成了标准。参见教材P75页中的CRC-16、CRC-CCITT和CRC-32。
第二部分
第3章 数据链路层
3.1 使用点对点信道的数据链路层
3.1.1 数据链路和帧
3.1.2 三个基本问题
3.2 点对点协议PPP
3.2.1 PPP协议的特点
3.2.2 PPP协议的帧格式
3.2.3 PPP协议的工作状态
封装成帧
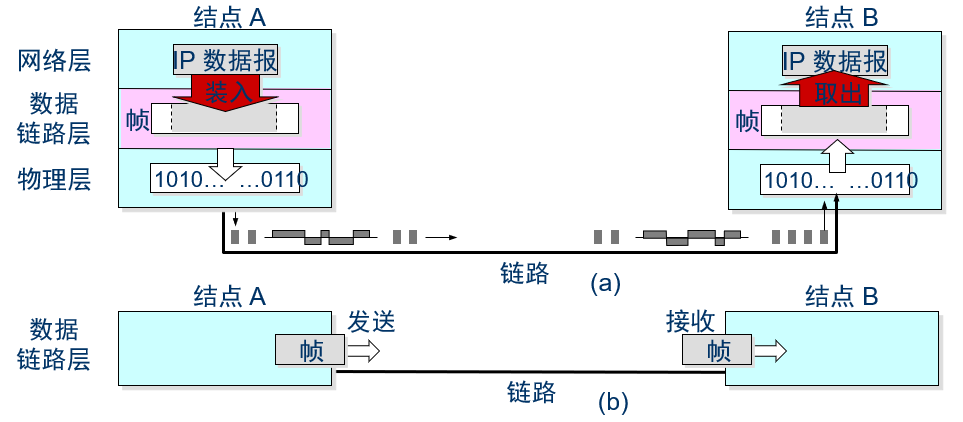
封装成帧的内容参见教材图3-3(P71,3.1.1节),下面给出了该图对应的彩色图。
封装成帧的过程如下图所示。
发送端将网络层的报文,即IP数据报,传递给数据链路层。数据链路层给该数据加上链路层首部和尾部,构成链路层的协议数据单元PDU。链路层的PDU常称为帧(frame)。
帧首部是一个结构化的数据块,我们将针对两个链路层协议,PPP协议和以太网协议,进行具体解释。
帧尾部就是上一节课介绍的差错检测的校验位,统称为FCS(Frame Check Sequence,帧检验序列)。它就是选定差错检测算法计算出来的冗余校验位。如果协议选用了CRC,则尾部也具体地叫做CRC。有时还指出所用的校验字节数。如2字节的CRC常称为CRC-2,4字节的CRC常称为CRC-4。
下图的(a)图说明了实际的帧生成和发送过程,即生成的帧要发到物理层,然后再通过介质传送到接收端。
下图的(b)图表述的是链路层的虚拟通信过程,即就通信两端的链路层通信实体来说,通信好像是在发送和接收站点的链路层实体之间进行,这样就可以简化链路层协议的设计。
3.2 点对点协议PPP
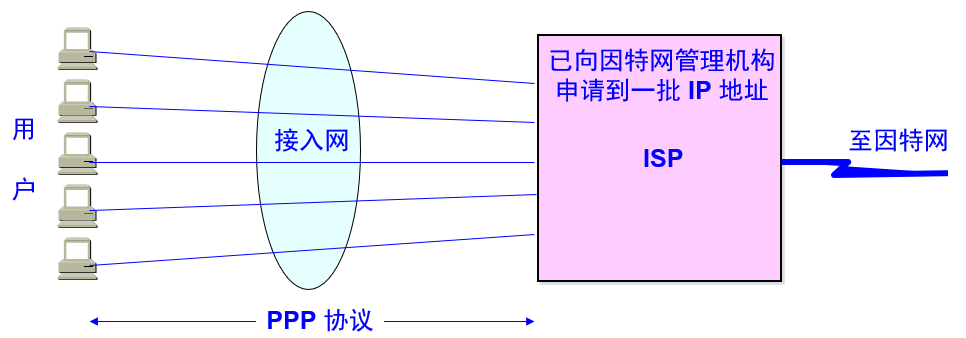
最简单的网络是只包括一个发送端和一个接收端的网络,这样的网络是由一条通信链路连接两个站点构成的,这样的通信常称为点对点(point-to-point)通信,它所对应的链路层协议称为PPP协议(Point-to-Point Protocol)。
点对点通信的常见例子是家庭网络用户通过ISP接入互联网的情况。通常家庭用户通过一条线缆连接到ISP的网络交换机。对于每个家庭用户来说,他与ISP交换机间的通信就是一个点对点的通信。
PPP协议于1994年成为因特网的正式标准(RFC-1661,RFC 1662) 。
PPP协议的最大特点就是简单,它只检测差错而不纠正差错。它不提供可靠传输机制,因而不使用序号,也不进行流量控制。
PPP协议主要包括三个组成部分:
-
一个将IP数据报封装到串行链路的方法。PPP既支持异步链路(无奇偶检验的8比特数据),也支持面向比特的同步链路。IP数据报在PPP帧中就是其数据部分,其长度受最大传送单元MTU的限制。
-
一个用来建立、配置和测试数据链路连接的链路控制协议LCP(Link Control Protocol)。通信的双方可使用LCP协商一些链路层选项。
-
一套网络控制协议NCP(Network Control Protocol),其中的每一个协议支持一个特定的的网络层协议,如IPCP、IPv6CP等。
PPP协议的帧格式
一个协议的核心部分体现在其协议数据单元PDU,对于链路层来说就是帧,的结构上,因而学习一个协议最重要的就是学习它的协议数据单元的结构,即其首部的结构。对于链路层来说,还包括尾部部分。
PPP协议是我们学习的第一个网络协议,读者应该从这样一个简单协议的帧结构的学习中,初步体会计算机网络协议的精髓。
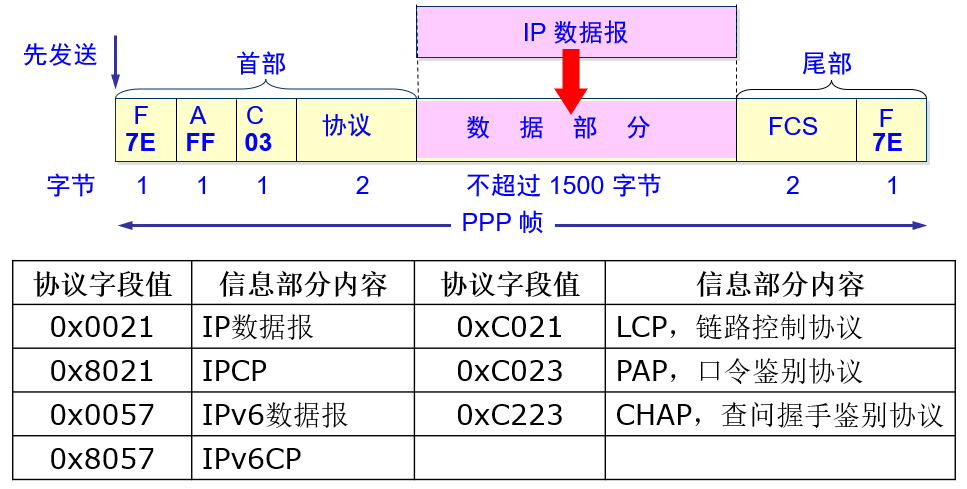
PPP协议的帧结构如下图所示,说明如下:
-
整个帧由三部分组成,即帧首部、帧数据和帧尾部。
-
帧首部通常是一个协议最核心也是最复杂的部分,对PPP协议来说首部包括4个组成部分:
-
帧开始标志字段F(Flag),长度为1字节,内容固定为0x7E,即二进制的01111110;
-
地址字段A(Address),长度为1字节,内容固定为0xFF,即二进制的11111111;
-
控制字段C(Control),长度为1字节,内容固定为0x03,即二进制的00000011。
-
协议字段,长度为2字节,内容见下面的表。该字段对于接收端识别帧中携带的数据非常重要。
特别需要记住的是:IP数据报对应的协议号是0x0021,即接收端看到协议号的值为0x0021时,即认为数据部分是IP数据报,于是就将数据交给网络层的IP模块。 -
PPP帧的数据部分允许0~1500个字节。对于互联网TCP/IP通信来说,数据部分绝大部分时候是IP数据报。
注:链路层帧所可以携带的最大数据量称为链路层的最大传输单元MTU(Maximum Transfer Unit)。MTU是网络通讯中的一个重要指标,今后将会用到。对于PPP协议来说,MTU的值为1500字节。 -
帧尾部包括两个组成部分:
-
帧检验序列FCS:使用2字节的CRC检验,生成多项式为
。
-
帧结束标志字段F(Flag),长度为1字节,内容与帧开始标志字段F相同,固定为0x7E,即二进制的01111110。
注意1:对于PPP帧的结构,还有一种解释认为首部只包含A、C和协议三个字段,而尾部只包含FCS一个字段,而将开始和结束的标志0x7E看成是帧的定界。本课程认为这两种说法都正确。读者可根据自己的领会掌握,只要能将帧结构中的所有字段的格式(次序、占有多少个字节、要求的数值或范围)及所代表的意义正确地表达出来就可以。
注意2:我们强调帧的结构和格式还有一个极其重要的方面就是帧格式具体地体现了协议的两个要素。第一章中曾经介绍过,网络协议包括三个基本要素,即语法、语义和规程。而帧的结构具体地体现了协议的前两个要素,即语法和语义。
对于PPP帧来说,它顺序地由标志、地址、控制、协议、FCS和标志字段组成,且各字段的长度分别为1、1、1、2、0~1500、2、1字节,标志固定为0x7E、地址固定为0xFF、控制固定为0x03等,这些都是协议的语法部分。
而第一个标志0x7E表示帧的开始,最后一个标志0x7E表示帧的结束,第二个字段表示地址、第三个字段表示控制、第四个字段表示了数据所对应的协议号、协议号后面的内容为数据、再后的两字节为差错检测的校验码,这些都是协议的语义部分。
至于协议的第三个要素规程,指的是协议的执行过程。PPP协议中的简单过程包括发送方要按照协议的格式构造帧,根据指定的CRC生成多项式计算CRC校验值,接收方要根据0x7E判断帧的开始和结束,要将帧开始标志后的第3、4个字节作为数据部分的协议号,并将数据交送相应的上层协议模块等,都属于协议的规程部分。其实PPP协议还包括更加复杂的链路建立、关闭、配置协商等过程,这可以通过了解教材图3-12(PPP协议的状态图,P81,3.2.3 PPP协议的工作状态)以及相关的解释来体会。
透明传输—字节填充
为什么需要透明传输?
我们来看PPP帧的传输情况。PPP帧以特别的0x7E作为帧的开始和结束标志,也就是说,接收方通过发现信道上的0x7E,即01111110这个特殊的字节,来判断一个帧的开始,并用同样的字节来判断一个帧的结束。那么,问题来了,如果在传输的数据中,出现了ASCII码表中的第126个字符,即“~”,则因为该字符对应的十六进制是0x7E,接收端就会认为该帧结束了,从而造成协议失败。
透明传输就是来解决这个问题的。
就如同差错检测是发送端根据一定的差错检测算法为数据加上冗余的位,使接收端根据相同的差错检测算法判断是否发生了位错误一样,透明传输也需要从发送端考虑。
发送端使用计算机专业中的“转义字符序列”(对应的英文是escape character sequence)技术来解决透明传输问题。具体地说,就是当数据部分出现0x7E时,在其前面增加一个转义字符0x7D,而数据部分出现0x7D时,也要转义,即在其前也要增加转义字符0x7D。
特别注意:“转义字符序列”是计算机专业中的一个通用方法。如,在C语言中,我们用“ ”表示换行、“ ”表示回车,而由于“”被用作转义标志,它本身作为字符时,也需要转义为“\”。在HTML语言中,“<"和“>”被用作标签的界定字符,而当文字内容中出现“<"和“>”符号时,就需要分别转义为“<”和“>”,而由于“&”被用作了转义标志,则当文字内容中出现“&"符号时,就需要转义为“&”。
需要说明的是,PPP协议在具体制定转义规则时,并不是将0x7E转义为0x7D0x7E和将0x7D转义为0x7D0x7D,而是分别将0x7E和0x7D分别转义为0x7D0x5E和0x7D0x5D。这或许是为了完全地避开0x7E字符吧。这一规则的正确性是没有问题的,接收端只要发现0x7D,就先去除该字符,再将其后的0x5E转为0x7E、0x5D转为0x7D就可以了。
上述透明传输的机制被称为是字节填充(byte stuffing)。它适应于以字节为单位进行传输的异步通信链路中。字节填充的命名也很形象,即通过塞入(stuffing)特别的转义字符实现透明传输。
透明的意思体现在:数据链路层的发送端自动地将发送数据中的0x7E进行转义,而接收端再自动地恢复。这对数据链路层的上层协议来说是透明的,即上层协议该发0x7E的照发,不需要关心和知道数据链路层的填充问题和方法。
透明传输—位填充
有些通信链路是同步的通信链路,这时候发送端将要发送的数据以连续比特流的方式发送数据,接收端通过同步时钟依次接收这些连续的比特流。这样的链路上数据就不是以字节为单位的。
在这样的比特流链路上传输PPP帧时,接收端会根据收到一个位0,再收到6个连续的位1,然后再收到一个位0作为帧的开始和结束,这时同样会存在发送的数据中有01111110组合时,接收端误认为帧结束的问题。
同步链路上对误将数据01111110认为是帧结束问题采用的方法是位填充:即发送端每当数据中出现连续的5个1就在后门插入一个0,而接收端在收到连续的5个1时,后面如果是0就抛弃,而后面如果不是0,则必是1,也就是帧的开始或结束标志了。
位填充的例子可参考教材图3-11(P80)。
第三部分
第3章 数据链路层
3.3 使用广播信道的数据链路层
3.3.1 局域网的数据链路层
3.3.2 CSMA/CD协议
3.3.3 使用集线器的星形拓扑
3.3.4 以太网的信道利用率
3.3.1 局域网的数据链路层
回顾:局域网LAN(Local Area Network),范围大约在1km内。
本节对LAN附加了一个特征:LAN不仅地理范围有限,一个LAN允许的最大站点数目也是有限的。
网络的拓扑结构:网络的拓扑结构指的是网络上各个站点间相互连接关系的抽象结构。
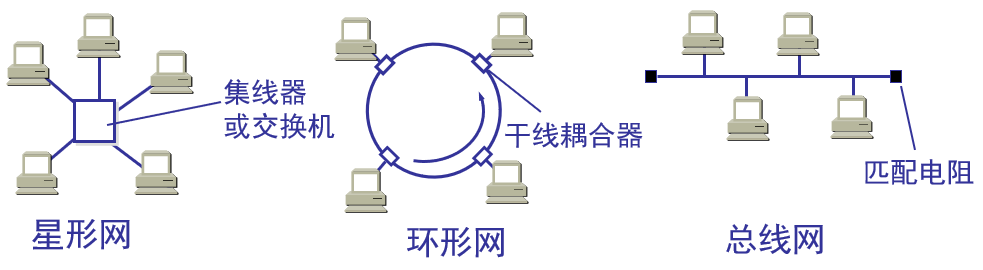
LAN的拓扑分类:星形网、环形网和总线网,如下图所示(参见教材图3-13,P82)。
注:LAN意义上的星形网中的交换机指的是数据链路层上的交换机,常称为二层交换机,不是连接互联网的路由器级的交换机,路由器意义上的交换机常称为三层交换机。
为了理解拓扑的抽象性,下面示出了一些更实际的环形网,即只要连接网络的链路绕成一个圈的,都叫环形网。


下面示出了一些更实际的总线网,即只要连接网络的链路是一条线的,都叫总线网,总线网还包括树形连接的网。
注:图中的Repeater为物理层上扩展网络的设备,称为中继器或转发器,实际是一个具有信号放大功能的设备。

以太网(Ethernet)
以太网是最典型的局域网,实际上目前的局域网几乎100%都是以太网,以太网已经成为了局域网的代名词。
以太网是美国施乐(Xerox)公司的Palo Alto研究中心(简称为PARC)于1975年研制成功的。它以曾经在历史上猜测的传播电磁波的介质—以太(Ether)来命名(后来的科学发现表明,电磁波本身就是一种介质,并不需要以太作为其传播的介质)。
1976年7月, Metcalfe(迈特卡尔夫)和Boggs发表了关于以太网的论文,这在计算机网络特别是局域网的发展历史中是具有里程碑意义的论文。1980年9月,DEC公司、英特尔(Intel)公司和施乐公司联合提出了10 Mbps以太网标准的第一个版本DIX V1(DIX是这三个公司名称首字母的缩写)。1982年又修改为第二版标准(实际上也就是最后的版本),即DIX Ethernet V2(简称为DIX V2),成为世界上第一个局域网的标准。
DIX V2以太网是一个拓扑结构为总线型的局域网,其带宽为10Mbps,人们常将这个早期的以太网称为传统以太网。讲授以太网原理也常常以传统以太网讲述。本课程也将遵循这一惯例。
注意:以太网的拓扑结构后来又发展为使用集线器的物理星形、逻辑总线的网络。而现今的以太网全都是交换机(二层交换机)连接的物理和逻辑均为星形的网络了。
为使局域网为更多的企业和组织机构所接受,电气与电子工程师协会IEEE专门制定局域网标准的802委员会,在DIX V2的基础上于1983年制定了第一个IEEE的以太网标准IEEE 802.3。IEEE 802.3局域网对DIX V2标准中的帧格式做了很小的一点更动,但允许基于这两种标准的硬件实现可以在同一个局域网上互操作,即相互兼容。
注:我们将在3.3.5节说明这两种标准在帧格式上的差别以及它们是如何实现相互间兼容的。
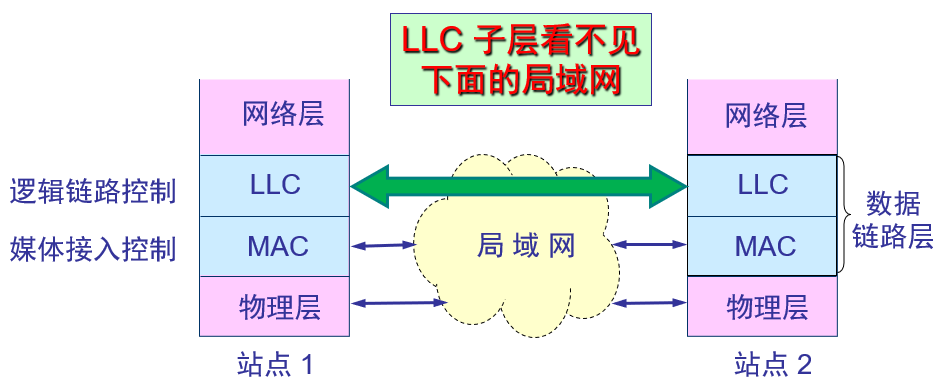
数据链路层的两个子层 — LLC子层和MAC子层
在局域网的早期,除了IEEE 802.3总线型的以太网外,还有IEEE 802.4令牌总线网、IEEE 802.5令牌环网等,为了使数据链路层向网络层提供一致的接口和服务,IEEE将数据链路层又划分为两个子层,即LLC子层(Logical Link Control, 逻辑链路控制子层)和MAC子层(Media Access Control, 媒体控制子层,也称为媒体访问子层)。如下图所示(参见教材图3-14,P84)。
注:从数据链路子层的角度来说,以太网是一个MAC子层的网络。
注:鉴于局域网几乎100%都是以太网,实际中已经没有其他类型的局域网了,数据链路层也就没有必要再设一个LLC子层了,即实际的数据链路层仅包括MAC子层,也就是说仅包括以太网。我们在今后的介绍中也不再介绍LLC子层。
网络适配器 — 网卡
计算机要与外部连接,如显示器、打印机等,就需要有一个接口设备,这样的接口设备要实现的功能就是使计算机和外部设备之间达致相互适应,因而这样的接口设备常称为适配器(adapter)。
计算机要连接网络,也需要一个这样的设备,该设备在专业上常称为网络适配器,即俗称的网卡(NIC,Network Interface Card, 网络接口卡)。
网卡的接口作用示意如下(参见教材图3-15,P85)。
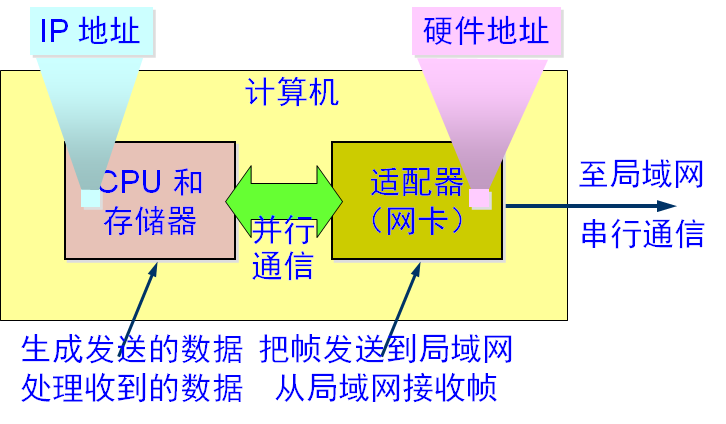
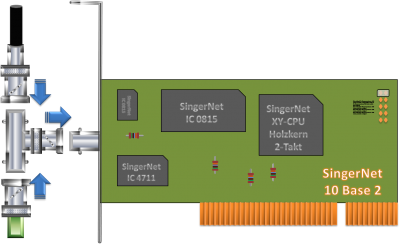
传统的网卡如下面的图所示。左图是一个千兆以太网卡(Gigabit Ethernet NIC),其上有一个以太网插口(Ethernet port),又称为RJ45插口,详如中间的图所示,该插口将插入RJ45插头以连接到以太网交换机(二层交换机)。传统以太网卡以PCI接口插到计算机的主板上。
PCI接口的网卡要插到主板的PCI插槽中使用。下图右侧白色的插槽就是PCI插槽。
现今的网卡都已集成到主板上了,如下图所示。NIC硬件直接集成到了主板上,通过主板上的RJ45插口用网线连接到以太网交换机。
需要说明的是,作为网络适配器,不单纯包括硬件部分的网卡,还包括软件部分的网卡驱动程序。只有安装了相应的驱动程序,网卡才能起到网络适配器的作用。
从网络体系结构的角度,网络适配器(包括硬件和软件部分)实现了最低两层,即物理层和数据链路层的功能。这也是局域网或物理网络所要实现的网络功能。
3.3.2 CSMA/CD协议
以太网长盛不衰的成功得益于其设计者提出的一个非常聪明的协议,即CSMA/CD协议(Carrier Sense Multiple Access with Collision Detection,带冲突检测的载波侦听多路访问协议)。
本节将详细讲述该协议的原理。
前已述及,传统以太网是一个总线式的网络,这可示意如下。为方便描述,将该图称为“图Ethernet”。
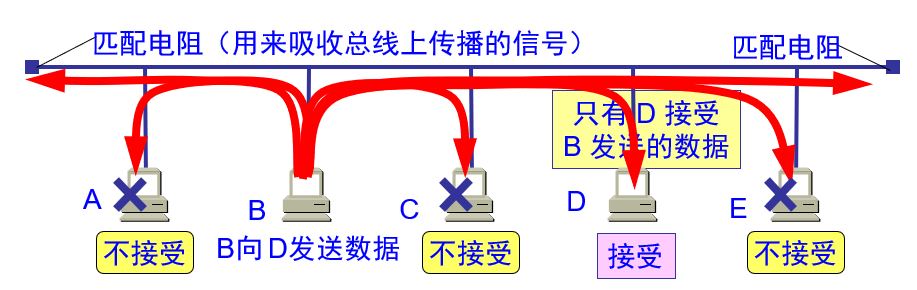
图 Ethernet
图Ethernet中,顶部的横线就是所说的总线。
注:传统以太网的总线在物理上经历了第一代的粗缆和第二代的细缆,分别成为粗缆以太网和细缆以太网。这里的粗缆和细缆分别指的是2.3.1节“导向型传输媒体”中介绍的75Ω和50Ω的同轴电缆。当时曾经介绍,为避免电磁波在同轴电缆的末端产生反射干扰,需要增加适宜的匹配电阻。图Ethernet总线两端的“匹配电阻”就是起这个作用的。由于粗缆以太网线缆太粗,不易弯折,布线难度很大,后来又发展了细缆以太网。由于50Ω的细缆比75Ω的粗缆柔软的多,使得布线容易了很多,也大大加快了以太网的普及。以下如果不做特殊说明,说到总线或传统以太网都指的是细缆以太网。
连网的计算机要连接到这条总线上,图Ethernet示出了A、B、C、D、E5台计算机连接到一条总线上的情形。在表述原理的叙述中,连网的计算机又常称为“主机”、“工作站”、“站点”或“站”。
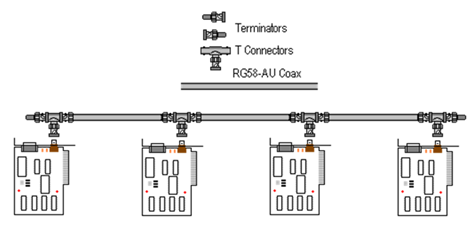
注1:实际的细缆总线网络连接部件为BNC连接器,下图示出了基本的BNC连接器。BNC接头是一种用于同轴电缆的连接器,全称是Bayonet Nut Connector(刺刀螺母连接器,这个名称形象地描述了这种接头外形),又称为British Naval Connector(英国海军连接器,起因于英国海军最早使用这种接头)或Bayonet Neill Conselman(Neill Conselman刺刀,这种接头是由美国贝尔实验室(Bell Labs)的Paul Neill和美国安费诺集团(Amphenol Corporation)的Carl Concelman发明的)。
从图中可以看出,基本的BNC连接器包括一个插座(slot)和一个插头pin,其突出特点是在插座上有一个锁定装置lock,该装置能使插头紧紧地卡在插座中。
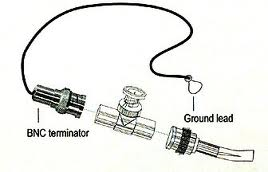
注2:以太网使用的BNC连接器如下图所示,其突出特征是组合了一个T形部件,该部件由水平方向的两个背对背的BNC插头和一个垂直方向的BNC插座构成。(a)中的“BNC terminator”就是终端匹配电阻(参见图(b)),Ground lead为接地铅片。图(a)中间的那个T型的部分(参见图(c))是用于连接计算机的。总线要接入一台计算机就需要将其剪断,剪断的电缆要装上BNC插头(如图(a)的右侧部分和图(d)所示),然后再连上T形头,如图(a)、(c)、(e)、(f)所示。T形头可以直接连到网卡上(图(g)),也可以通过两头带BNC插头的电缆(图(h))连到网卡上(图(i))。
注3:图(i)所示的网卡是同时带有细缆插口和RJ45插口(适应于后来的双绞线/集线器以太网)的双功能网卡。
注4:图(j)和图(k)是较贴近实际的网络连接示意图。

(a) (b)



(c) (d) (e)

(f)
(g) (h) (i)
(j)
(k)
粗缆以太网和细缆以太网分别对应的标准是10Base5和10Base2。这里的10指的是10Mbps的速率,Base指的是使用基带进行传输。而5和2分别表示最大网段长度分别为500米和185米(约为200米),这个长度限制是线缆上的信号衰减所导致的。使用中继器(即信号放大器repeater)可以延长网络范围,但粗缆和细缆以太网最多可以使用4个中继器,即粗缆和细缆以太网的最大覆盖范围分别是2500米和1000米。粗缆和细缆以太网既然以基带信号传输那就需要线路编码,它们均采用了可自同步的曼彻斯特或差分曼彻斯特编码(参见2.2.2节)。
总线式以太网要工作所面临的问题
总线式以太网中,各站点连接到一条总线上,如图Ethernet所示,即各个站点共享同一条总线,那么要实现网络化通信首先要解决如下两个重要问题:
-
接收方识别问题:如图Ethernet所示,如果B站要将数据发送给D站,则应该只有D站接收数据,其他站不应接收数据。但由于总线是共享的,B站发出的信号其他所有站点都将收到,因此需要一种机制使得只有D站接收,其他站不接收。
-
信号干扰即冲突问题:由于信号以基带方式传输,同一时刻如果有不同的站点发送数据信号,包括两个或多个站点同时发送,或一个站点正在发送的过程中其他站点发送出了数据信号,这都会造成总线上的信号干扰,结果是发生了相互干扰的信号,成为不可识别内容的信号,因而导致相关站点的数据发送失败。
第1个问题比较好解决,我们只要为每个站点指定一个地址就可以了。所谓地址,也就是一种编号。然后我们在发送信号的开始加上地址信息,这样收到信号的站点首先接收到的是地址信息。识别出该地址信息后,它就判断该地址与自己的地址(各个站要事先知道自己的地址,实际上地址被事先写到了网卡的ROM中)是否一致,如果一致,则继续接收接下来的数据,如果不一致则忽略接下来的数据。
第2个问题较为复杂,这就是CSMA/CD协议所要解决的问题。
CSMA/CD协议要点
CSMA/CD协议主要解决多站点总线共享或争用总线、争用介质的问题,教材在P86-87页解释了CSMA/CD协议的要点。为帮助学习,我们将该协议要点组织为如下易于记忆和理解的形式:
-
先听后说 — 若站点有数据要发送,则要先检测(即侦听或监听)信道,当侦听到信道空闲时方可发送。
-
边说边听或碰撞检测 — 即一边发送一边侦听,以确定信号发送过程中是否受到了其他站点的干扰,即是否发生了碰撞。
-
强化冲突 — 如果检测到了碰撞,则停止发送正常信号,并发送一个短的强化冲突信号(jam signal)。
-
退避重发 — 若因检测到冲突而停止本次发送,则采用截断二进制指数退避算法(the truncated binary exponential backoff algorithm)退避后重新发送。
先听后说
这一条比较好理解,就不用多解释了。
边说边听或碰撞检测
先解释一个问题,为什么侦听到信道空闲才发送,还会发生碰撞呢?
这里的主要原因是信号,即电磁波,在总线上的传播是需要时间的。以前面的图Ethernet为例,假如某一时刻,A站点有数据要发送,且检测到信道是空闲的,则它就向信道上发送数据信号。如果A发送的信号在到达了B站但还没有到达D站时,D站生成了要发送的数据,而且检测到信道空闲,于是它就向总线上发送数据信号,而它发送的数据信号将会大约在C站的位置处与A站发送的数据信号发生碰撞,使得信道上的信号成为不可识别的干扰信号,导致A站和D站的发送均告失败。
边说边听的方法就可以让站点发现自己发送的信号是否受到了干扰。例如上面的例子中,A、D站的信号在C站处发生了碰撞后,碰撞后的信号一方面会向D站方向传播,另一方面会向A站方向传播,这样边发边听机制会使A、D站都能发现自己发送的信号受到了干扰,即发生了碰撞。尽管A、D站不能阻止干扰的发生,但是可以获知发生了干扰,从而可以及时地停止发送,并采取后续措施。
强化冲突
当着一个站点检测到发送的数据发生了冲突后,为了使总线上的所有站点都检测到信道受到了干扰,该站点就发送一个人为的强化干扰信号(jamming signal)。
协议标准规定,强化干扰信号为32或48比特的信号,对于10Mbps速率的传统以太网来说,花费的发送时间分别是3.2或4.8μs。
退避重发
前已述及,当发送数据的站点检测到冲突后,会立即停止发送,并发送一个强化冲突信号。
然而,站点的数据还是需要发出去的。如果两个或多个检测到冲突的站点在发送完强化冲突信号后,就立即再次发送数据,则势必产生新的冲突。
以太网采用了退避重发的方法解决这个问题。
退避重发的基本思路是:当着站点因检测到冲突而重发数据时,还是先检测信道,如果发现信道空闲,则不是立即发送数据,而是等待一个随机的时间再发送数据。只要使各个站点选择的随机时间尽可能地不一致,则再次发生冲突的可能性就会大大降低。
以太网对这个退避重发过程设计了精巧的算法,该算法取名为截断二进制指数退避算法(truncated binay exponential back-off),算法描述如下:
-
当首次发生碰撞时, 站点从0或1(即
)中随机选择一个值n, 并且等待2nτ的时间再侦听网络, 这里2τ是以太网的争用期,对于粗缆以太网, 2τ =51.2 μs。
注:后来的细缆以太网、集线器以太网以及交换机以太网为了保持兼容均采用了粗缆以太网的51.2 μs的争用期。 -
如果第2次发生碰撞, 则从0 , 1, 2, 3 (
)中随机选择一个值n, 并且等待2nτ的时间再侦听网络。
-
依次类推, 第i次(i≤10)碰撞从
中随机选择n,并且等待2nτ的时间再侦听网络。
-
当i>10时, 选取n的范围固定在
之间。
-
如果碰撞连续发生了16次, 则不再进行侦听和发送尝试, 协议将向高层报告一个传输错误。
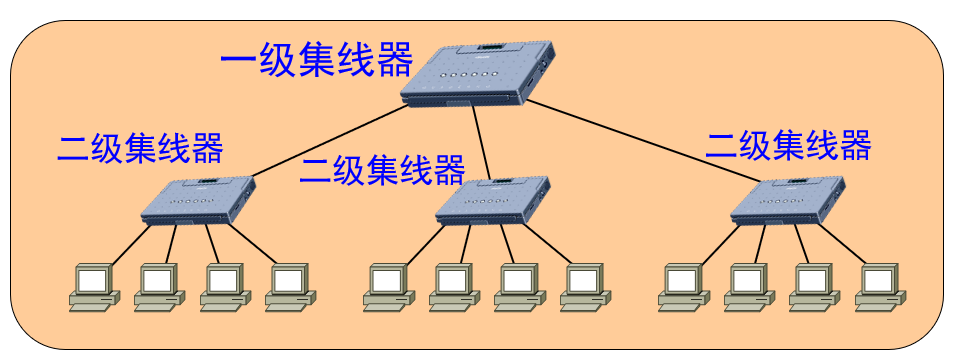
3.3.3 使用集线器的星形拓扑
细缆以太网在布线和网络调整方面依然显得不够灵活,而且造价也有些过高。
后来又发展了更加灵活和造价低廉的基于集线器(hub)的双绞线以太网。
这种以太网有一个处在中心位置的连接设备,称为集线器(hub)。集线器上有若干个RJ45插口,计算机上的网卡也有RJ45插口,它们通过两端带有RJ45插头的双绞线连接起来,从而形成一个物理上星形的网络拓扑。
但是hub是一种共享设备,即同一时刻只能有一对计算机进行通信。可以看成是在hub内部有一条短的总线,连接到hub的各个站点使用CSMA/CD协议竞争这个盒中的总线。因此这种以太网又称为物理星形逻辑总线的网络。
基于集线器的以太网对应的标准为10BaseT,10Base依然表示10Mbps的速率和使用曼彻斯特编码的基带调制,T表示双绞线(Twisted pair)。10BaseT采用5类的无屏蔽双绞线,一条该类型的双绞线缆包括4对8芯的铜线,标准只用到了其中的两对,剩余的两对做备用。
集线器以太网的网线最大允许长度为100米,即一个集线器的网络直径为200米。但允许级联4级的集线器,这样就可以达到1000米的网络直径。