leader分享的总结 我这里记录一下 时不时来看一下 免得哪天离职了 看不到了
为什么使用缓存
(1)减少网络带宽消耗
无论对于网站运营者或者用户,带宽都代表着金钱,所以要避免过多的带宽消耗。当Web缓存被使用时,只会产生极小的网络流量,可以有效的降低运营成本。
(2)降低服务器压力
给网络资源设定有效期之后,用户可以重复使用本地的缓存,减少对源服务器的请求,间接降低服务器的压力。同时,搜索引擎的爬虫机器人也能根据过期机制降低爬取的频率,也能有效降低服务器的压力。
(3)减少网络延迟,加快页面打开速度
除了能够减少带宽,对于最终用户,缓存的使用能够明显加快页面打开速度,达到更好的体验。
浏览器HTTP请求流程
基本的网络请求就是三个步骤:请求,处理,响应。后端缓存主要集中于“处理”步骤,而前端缓存则可以在“请求”和“响应”中进行。
在“请求”步骤中,浏览器也可以通过存储结果的方式直接使用资源,直接省去了发送请求;而“响应”步骤需要浏览器和服务器共同配合,通过减少响应内容来缩短传输时间。
第一次请求:
再次请求:

缓存分类
浏览器缓存按位置分为 memory cache, disk cache, Service Worker 等,按失效策略分 Cache-Control, ETag 等即强缓存和协商缓存。
它们的优先级是:(由上到下寻找,找到即返回;找不到则继续)
1.Service Worker
2.Memory Cache
3.Disk Cache
4.网络请求
Memory cache
memory cache 是内存中的缓存 (与之相对 disk cache 就是硬盘上的缓存)。
几乎所有的网络请求资源都会被浏览器自动加入到 memory cache 中。但是也正因为数量很大但是浏览器占用的内存不能无限扩大这样两个因素,memory cache 注定只能是个“短期存储”。
常规情况下,浏览器的 TAB 关闭后该次浏览的 memory cache 便失效。而如果极端情况下 (例如一个页面的缓存就占用了超级多的内存),那可能在 TAB 没关闭之前,排在前面的缓存就已经失效了。
可以显式指定的预加载资源,也会被放入 memory cache 中,例如 <link rel="preload">。
memory cache 机制保证了一个页面中如果有两个相同的请求 (例如两个 src 相同的 <img>,两个 href 相同的 <link>) 都实际只会被请求最多一次,避免浪费。
不过在匹配缓存时,除了匹配完全相同的 URL 之外,还会比对他们的类型,CORS 中的域名规则等。因此一个作为脚本 (script) 类型被缓存的资源是不能用在图片 (image) 类型的请求中的,即便他们 src 相等。
在从 memory cache 获取缓存内容时,浏览器会忽视例如 max-age=0, no-cache 等头部配置。例如页面上存在几个相同 src 的图片,即便它们可能被设置为不缓存,但依然会从 memory cache 中读取。这是因为 memory cache 只是短期使用,大部分情况生命周期只有一次浏览而已。而 max-age=0 在语义上普遍被解读为“不要在下次浏览时使用”,所以和 memory cache 并不冲突。
但如果是真不想让一个资源进入缓存,就连短期也不行,那就需要使用 no-store。存在这个头部配置的话,即便是 memory cache 也不会存储,自然也不会从中读取了。
Disk cache
disk cache 也叫 HTTP cache,顾名思义是存储在硬盘上的缓存,因此它是持久存储的,是实际存在于文件系统中的。而且它允许相同的资源在跨会话,甚至跨站点的情况下使用,例如两个站点都使用了同一张图片。
disk cache 会严格根据 HTTP 头信息中的各类字段来判定哪些资源可以缓存,哪些资源不可以缓存;哪些资源是仍然可用的,哪些资源是过时需要重新请求的。当命中缓存之后,浏览器会从硬盘中读取资源,虽然比起从内存中读取慢了一些,但比起网络请求还是快了不少的。绝大部分的缓存都来自 disk cache。
Service Worker
上述的缓存策略以及缓存/读取/失效的动作都是由浏览器内部判断并进行的,我们只能设置响应头的某些字段来告诉浏览器,而不能自己操作。但 Service Worker 的出现,给予了我们另外一种更加灵活,更加直接的操作方式。
Service Worker 能够操作的缓存是有别于浏览器内部的 memory cache 或者 disk cache 的。除了位置不同之外,这个缓存是永久性的,即关闭 TAB 或者浏览器,下次打开依然还在(而 memory cache 不是)。
有两种情况会导致这个缓存中的资源被清除:手动调用 API cache.delete(resource) 或者容量超过限制,被浏览器全部清空。
如果 Service Worker 没能命中缓存,一般情况会使用 fetch() 方法继续获取资源。这时候,浏览器就去 memory cache 或者 disk cache 进行下一次找缓存的工作了。注意:经过 Service Worker 的 fetch() 方法获取的资源,即便它并没有命中 Service Worker 缓存,甚至实际走了网络请求,也会标注为 from ServiceWorker。
请求网络
如果一个请求在上述 3 个位置都没有找到缓存,那么浏览器会正式发送网络请求去获取内容。为了提升之后请求的缓存命中率,自然要把这个资源添加到缓存中去。具体来说:
1.根据 Service Worker 中的 handler 决定是否存入 Cache Storage (额外的缓存位置)。
2.根据 HTTP 头部的相关字段(Cache-control, Pragma 等)决定是否存入 disk cache
3.memory cache 保存一份资源 的引用,以备下次使用。
强缓存
强制缓存的含义是,当客户端请求后,会先访问缓存数据库看缓存是否存在。如果存在则直接返回;不存在则请求真的服务器,响应后再写入缓存数据库。
强制缓存直接减少请求数,是提升最大的缓存策略。 它的优化覆盖了文章开头提到过的请求数据的全部三个步骤。如果考虑使用缓存来优化网页性能的话,强制缓存应该是首先被考虑的。
可以造成强制缓存的字段是 Cache-control 和 Expires。
Expires
这是 HTTP 1.0 的字段,表示缓存到期时间,是一个绝对的时间 (当前时间+缓存时间),如
Expires: Fri, 14 Feb 2020 17:54:43 GMT
在响应消息头中,设置这个字段之后就可以告诉浏览器,在未过期之前不需要再次请求。
但是,这个字段设置时有两个缺点:
- 由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源。此外,即使不考虑自行修改,时差或者误差等因素也可能造成客户端与服务端的时间不一致,致使缓存失效。
- 写法太复杂了。表示时间的字符串多个空格,少个字母,都会导致非法属性从而设置失效。
Cache-control
已知Expires的缺点之后,在HTTP/1.1中,增加了一个字段Cache-control,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求。
这两者的区别就是前者是绝对时间,而后者是相对时间。如下:
Cache-control: max-age=2592000
下面列举一些 Cache-control 字段常用的值:(完整的列表可以查看 MDN)
- max-age:即最大有效时间,在上面的例子中我们可以看到。
- must-revalidate:如果超过了 max-age 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。
- no-cache:虽然字面意思是“不要缓存”,但实际上还是要求客户端缓存内容的,只是是否使用这个内容由后续的对比来决定。
- no-store: 真正意义上的“不要缓存”。所有内容都不走缓存,包括强制和对比。
- public:所有的内容都可以被缓存 (包括客户端和代理服务器, 如 CDN)
- private:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值
这些值可以混合使用,例如 Cache-control:public, max-age=2592000
总结一下,自从 HTTP/1.1 开始,Expires 逐渐被 Cache-control 取代。Cache-control 是一个相对时间,即使客户端时间发生改变,相对时间也不会随之改变,这样可以保持服务器和客户端的时间一致性。而且 Cache-control 的可配置性比较强大。
Cache-control 的优先级高于 Expires,为了兼容 HTTP/1.0 和 HTTP/1.1,实际项目中两个字段我们都会设置。
协商/对比缓存
当强制缓存失效(超过规定时间)时,就需要使用对比缓存,由服务器决定缓存内容是否失效。
流程上说,浏览器先请求缓存数据库,返回一个缓存标识。之后浏览器拿这个标识和服务器通讯。如果缓存未失效,则返回 HTTP 状态码 304 表示继续使用,于是客户端继续使用缓存;如果失效,则返回新的数据和缓存规则,浏览器响应数据后,再把规则写入到缓存数据库。
对比缓存在请求数上和没有缓存是一致的,但如果是 304 的话,返回的仅仅是一个状态码而已,并没有实际的文件内容,因此 在响应体体积上的节省是它的优化点。
它的优化覆盖了文章开头提到过的请求数据的三个步骤中的最后一个:“响应”。通过减少响应体体积,来缩短网络传输时间。所以和强制缓存相比提升幅度较小,但总比没有缓存好。
对比缓存是可以和强制缓存一起使用的,作为在强制缓存失效后的一种后备方案。
Last-Modified & If-Modified-Since
服务器通过 Last-Modified 字段告知客户端,资源最后一次被修改的时间,例如:
Last-Modified: Fri, 14 Feb 2020 17:54:43 GMT
浏览器将这个值和内容一起记录在缓存数据库中。
下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的 Last-Modified 的值写入到请求头的 If-Modified-Since 字段
服务器会将 If-Modified-Since 的值与 Last-Modified 字段进行对比。如果相等,则表示未修改,响应 304;反之,则表示修改了,响应 200 状态码,并返回数据。
但是他还是有一定缺陷的:
- 如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
- 如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
Etag & If-None-Match
为了解决上述问题,出现了一组新的字段 Etag 和 If-None-Match。
Etag 存储的是文件的特殊标识(一般都是 hash 生成的),服务器存储着文件的 Etag 字段。之后的流程和 Last-Modified 一致,只是 Last-Modified 字段和它所表示的更新时间改变成了 Etag 字段和它所表示的文件 hash,把 If-Modified-Since 变成了 If-None-Match。服务器同样进行比较,命中返回 304, 不命中返回新资源和 200。
Etag 的优先级高于 Last-Modified。
缓存设置
浏览器缓存
了解了缓存的原理,我们可能更加关心如何在实际项目中使用它们,才能更好的让用户缩短加载时间,节约流量等。这里有几个常用的模式,供参考:
模式1:不常变化的资源
Cache-control: max-age=31536000
通常在处理这类资源资源时(字体、图片等),给它们的 Cache-Control 配置一个很大的 max-age=31536000 (1年),这样浏览器之后请求相同的 URL 会命中强制缓存。
而为了解决更新的问题,就需要在文件名(或者路径)中添加 hash, 版本号等动态字符,之后更改动态字符,达到更改引用 URL 的目的,从而让之前的强制缓存失效 (其实并未立即失效,只是不再使用了而已)。
在线提供的类库 (如 vue.min.js, axois.min.js 等) 均采用这个模式。如果配置中还增加 public 的话,CDN 也可以缓存起来,效果不错。
模式2:可变化的资源
Cache-control: max-age=2592000
JS代码等资源可设置缓存时间为1个月。
模式3:经常变化的资源
Cache-control: no-cache
这里的资源不单单指静态资源,也可能是网页资源(index.html)。这类资源的特点是:URL 不能变化,但内容可以变化。我们可以设置 Cache-Control: no-cache 来迫使浏览器每次请求都必须找服务器验证资源是否有效。
阿里云CDN缓存
源站请求头设置
OSS源站默认HEADER会带上 content-encoding: gzip,Last-Modified 等。
OSS支持HTTP协议规定的5个请求头:Cache-Control、Expires、Content-Encoding、Content-Disposition、Content-Type。如果上传Object时设置了这些请求头,则该Object被下载时,相应的请求头值会被自动设置成上传时的值。
CDN缓存
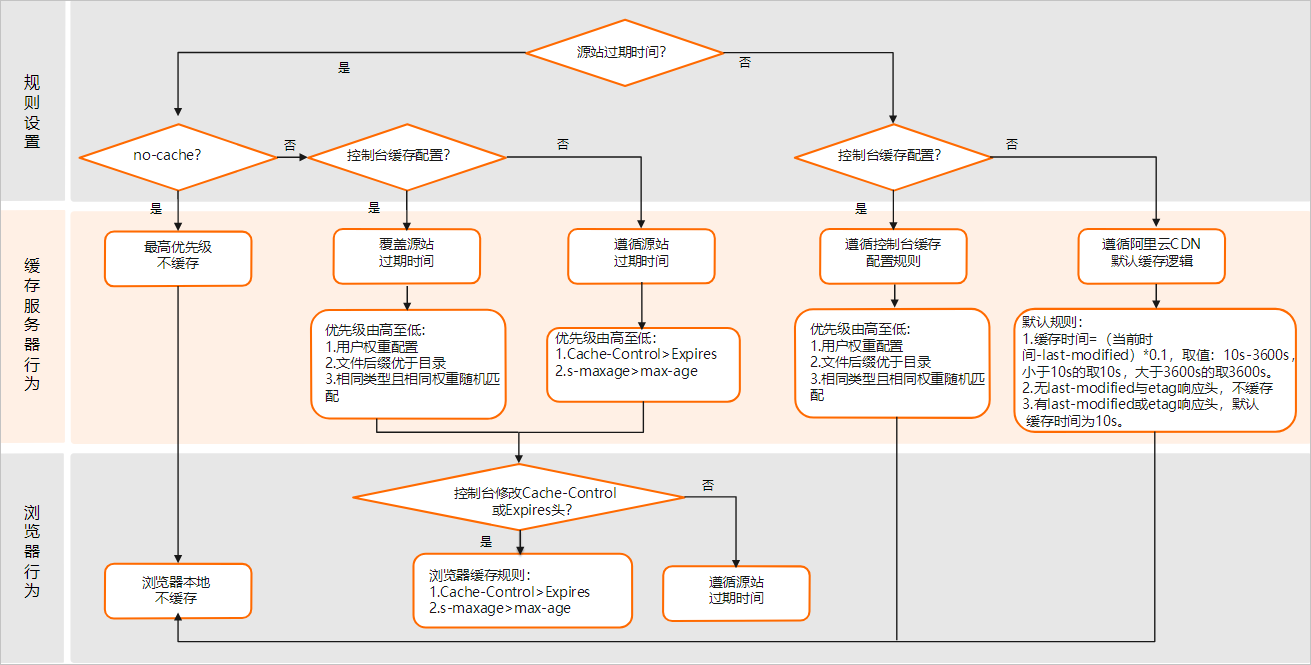
CDN节点上资源的缓存策略如图所示说明:
- Cache的默认缓存策略用于配置文件过期时间,在此配置的优先级高于源站配置。如果源站未配置Cache,则支持按完整目录或文件后缀名两种方式设置。
- CDN节点上缓存的资源,可能由于热度较低而被提前从节点删除。
- 在源站响应给CDN节点的内容里面携带了etag信息,并且客户端请求也有携带if-match信息的情况下,如果if-match值=etag值,CDN节点会将缓存的内容直接响应给客户端;如果if-match值≠etag值,CDN节点将会先回源获取最新的内容,然后将最新的内容响应给客户端,同时在CDN节点上用最新的内容替代原先旧的内容。即客户端请求中的if-match信息与缓存文件中的etag信息的校验优先级高于CDN上配置的缓存规则。
配置阿里云CDN缓存过期时间参见文档:https://help.aliyun.com/document_detail/27136.html
浏览器缓存设置
HTTP响应头(Cache-Control)的设置会影响该加速域名下所有资源,当您通过客户端(例如浏览器)访问资源时,会影响请求响应,但不会影响缓存服务器。
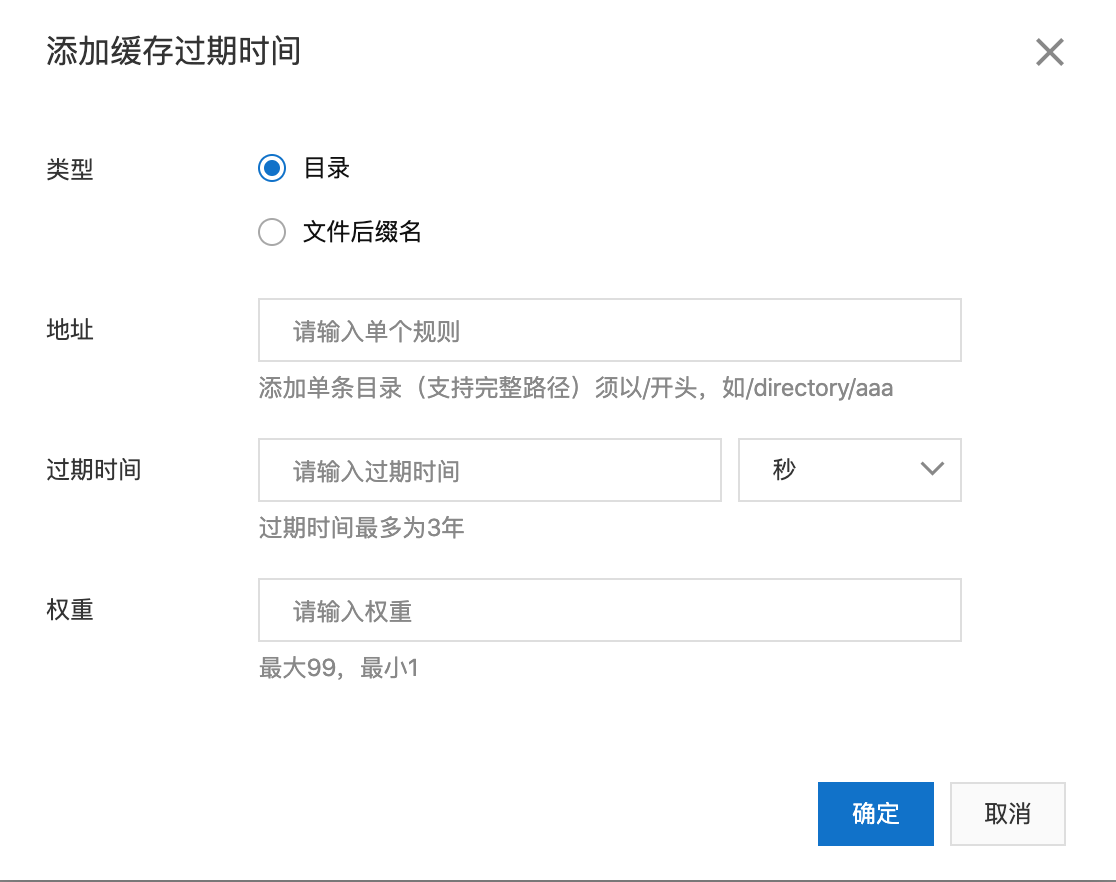
配置HTTP头参见文档:https://help.aliyun.com/document_detail/27137.html