端口
首先要理解端口(port)的概念。端口是一种抽象的软件结构,包括一些数据结构和I/O缓冲。
进程通过系统调用与端口建立连接(binding),之后传输层传给该端口的数据都被相应进程所接收,而相应进程发给传输层的数据也通过该端口。端口操作类似于一般的I/O操作,进程获取一个端口,相当于获取本地唯一的I/O文件,所以可以用一般的读写系统调用来操作。
类似于文件描述符,每个端口都拥有整数型标识符端口号,用于区分不同端口。由于TCP/IP传输层的TCP和UDP是完全独立的两个软件模块,因此各自的端口号也相互独立,两者都有多达65536个端口。
在所有的65536个端口中,数值为0~1023的端口也称为熟知端口,IANA把这些端口号指派给了TCP/IP最重要的一些应用进程。当一种新的应用程序出现后,IANA必须为它指派一个熟知端口号。常见的熟知端口包括20、21、22、23、53、80、443等。
TCP和UDP
特点
位于网络层
TCP特点:
使用三次握手建立连接,拥有确认、窗口、重传、拥塞控制等机制,传输完成后会断开连接节约资源
缺点:
速度慢、效率低、占用系统资源高、易被攻击
UDP特点:
快 但不可靠
结构

TCP

UDP
TCP的校验和计算和IP头部的校验和计算方法是一致的,但是覆盖的数据范围不一样。TCP校验和覆盖TCP首部和TCP数据,而IP首部中的校验和只覆盖IP的头部。TCP的校验和是必需的,而UDP的校验和是可选的。TCP和UDP计算校验和时,都要加上一个12字节的伪首部。
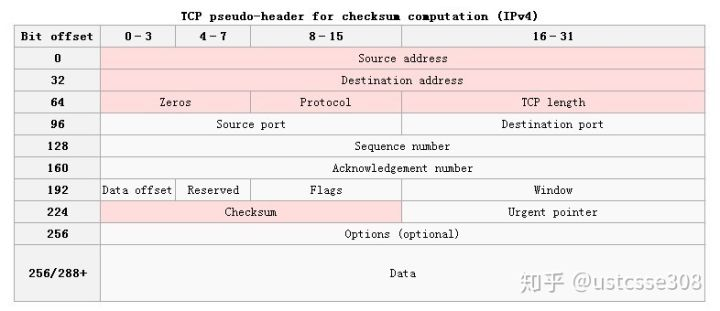
伪首部包含:源IP地址、目的IP地址、保留字节(置0)、传输层协议号(TCP是6)、TCP报文长度(报头+数据)。伪首部是为了增加TCP校验和的检错能力:如检查TCP的源和目的IP地址、传输层协议等。
【协议栈的处理数据报流程肯定是要先经过IP层的处理过滤掉不属于自己的IP数据报后才接着往上层处理的,为何到了上层(TCP、UDP)还需要校验数据报是否属于自己呢?主要是因为Internet中的数据报会在传输过程中经过多跳(hop)才会到达最终的目的地址,在中间的任何一跳都可能会存在软件/硬件的错误,导致本来应该到达X的数据报到达了Y(修改了数据报中的dst address和IP层的checksum),这样的数据报可以顺利的逃过IP层的校验到达上层TCP/UDP。这个时候pseudo header就发挥它的作用了,通过计算数据报的校验码就能发现这是一个错误的数据报。
不过另一方面,既然能修改IP层的数据那么同样可以修改TCP/UDP层的数据,如果把TCP/UDP中的校验码checksum重新计算修改成“正确“的值,这个数据报就可以逃过IP层、TCP层的校验了。pseudo header主要是为了修正中间网络设备的错误路由,因为中间路由设备一般都只会操作IP层不会操作TCP/UDP层,所以也就不会错误的修改TCP/UDP的checksum了。(即使错误路由,IP层的checksum应该也不会恰好对,所以....)】
在RFC 793中规定了TCP头部校验和的计算:
把伪首部、TCP报头、TCP数据分为16位的计算单位,如果总长度为奇数个字节,则在最后增添一个全为0的字节。计算式首先把TCP报头中的校验和字段置为0。然后使用反码相加法累加所有的16位字(进位也要累加)。最后,对计算结果取反,作为TCP的校验和。
攻击
TCP SYN Flooding
SYN flooding之前也讨论过,发生这种攻击的原因是因为TCP三次握手过程中的一个设计。当应用开放了一个TCP端口后,该端口就处于侦听状态,不停地监视发到该端口的Syn报文,一旦接收到Syn报文,就需要为即将建立的TCP连接分配TCB(Transmission Control Block),通常一个TCB至少需要280个字节,在某些操作系统中TCB甚至达到1300个字节;并且进入半开连接(half-opening)状态,也即收到SYN包而还未收到ACK包时的连接状态。操作系统实现的最多可开启的半开连接个数是一定的,譬如512,而受到内存的限制,可能还达不到这个数字。如果半开连接的个数过多,就会消耗掉可用的内存,使得新的正常的连接请求不能被处理。
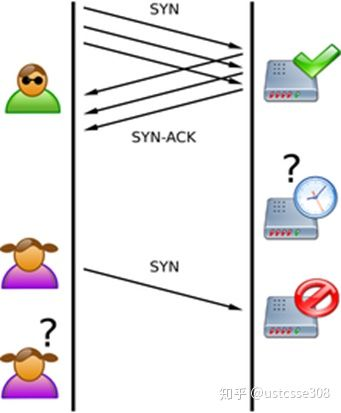
防范:
系统中默认的tcp_syncookies的值是1,如果不做这个改动,syn_flood攻击没有效果。
syn cookie是现在防范TCP Syn Flood的业界标准做法之一,由Daniel J. Bernstein和Eric Schenk于 1996 年九月提出。Eric Schenk随后在 1997 年二月发布了Linux实现。
。
SYN Cache
因为我们常说的四元组主要是源IP、源端口、目的IP和目的端口,那么可以在接收到SYN包时,仅仅分配有限的空间,来维持其后可能需要的信息,而不是分配整个的TCP控制块。这种思路叫做SYNCache,每次来了SYN包,那么就在SYNCache队列中生成一个项,保持一些基本信息;然后在收到ACK时检查SYNCache队列,如果能找到合适的项,那么开始建立TCP连接,然后删除SYNcache中的项。使用TCPCache可以抵御DoS主要是通过保持有限的信息,节约资源;然后通过限制SynCache的大小。
SYN Cookie
SYN Cookie的原理即针对在ACK还未到达之前就需要分配大量资源的问题而提出的解决方案。思路是在ACK到达之前不分配任何资源。直观上来看,这样的问题是什么?如果不为SYN包分配任何资源,那么在收到ACK包的时候,怎么知道它前面发送了SYN包呢?特别是,如果实现的不好,那么防火墙上关于SYN所设置的过滤条件就可能失效。所以,SYN Cookie的关键在于如何在不分配资源的同时,能够识别是否是一个完整的TCP三次握手。
SYN Cookie的工作过程如下:在接收到客户端的TCP SYN数据包时,服务器构造TCP SYN + ACK数据包发送回客户端。根据TCP规范,端点发送的第一个序列号可以是由该端点决定的任何值。在该数据包中的序列号的值不再是随机值,或者是其他方法生成的值,而是,SYN cookie根据以下规则精心构建的初始序列号:
设t是一个缓慢递增的时间戳(通常是time()逻辑上右移6个位置,这给出了64秒的分辨率)令m为服务器可能在SYN队列条目中存储的最大段大小(MSS)值设s是通过服务器IP地址和端口号、客户端IP地址和端口号以及值t计算的加密哈希函数的结果。返回值s必须是24位值。
初始TCP序列号,即SYN cookie,计算如下:
前5位:t mod 32中3位:表示m的编码值最后24位:s
(注意:由于m必须使用3位进行编码,因此当使用SYN cookie时,服务器仅限于使用最多8个值;这时可以使用Mss Indicator,使用8个索引值来代表具体的值。)
当客户端响应服务器的SYN + ACK数据包向服务器发回TCP ACK数据包时,客户端必须(根据TCP规范)在数据包的确认号中使用n + 1,其中n是由服务器发送的初始序列号。然后,服务器从确认号中减去1,得到发送给客户端的SYN cookie。
然后,服务器执行以下操作。
检查值t与当前时间,以查看连接是否已过期。重新计算s以确定它是否确实是一个有效的SYN cookie。从SYN cookie中的3位编码解码值m,然后可以使用它来重建SYN队列条目。