oracle中 connect by prior 递归算法
如果表中存在层次数据,则可以使用层次化查询子句查询出表中行记录之间的层次关系
基本语法:
[ START WITH CONDITION1 ]
CONNECT BY [ NOCYCLE ] CONDITION2
[ NOCYCLE ]参数暂时不解释
例:
select empno, ename, job, mgr, hiredate, sal, comm, deptno, level as lv
from emp
start with empno = 7839
connect by (prior empno) = mgr;
表中存在层次数据
数据之间的层次关系即父子关系,通过表中列与列间的关系来描述,如EMP表中的EMPNO和MGR。EMPNO表示雇员编号,MGR表示领导该雇员的人的编号,在表的每一行中都有一个表示父节点的MGR(除根节点外),通过每个节点的父节点,就可以确定整个树结构。
CONNECT BY [ NOCYCLE ] CONDITION2 层次子句作用
CONDITION2 [PRIOR expr = expr] : 指定层次结构中父节点与子节点之之间的关系。
CONDITION2 中的 一元运算符 PRIORY 必须放置在连接关系的两列中某一个的前面。在连接关系中,除了可以使用列名外,还允许使用列表达式。
1.START WITH
start with 子句为可选项,用来标识哪行作为查找树型结构的第一行(即根节点,可指定多个根节点)。若该子句被省略,则表示所有满足查询条件的行作为根节点。
2.关于PRIOR
PRIOR置于运算符前后的位置,决定着查询时的检索顺序。
2.1 从根节点自顶向下
--sql 1
select empno, mgr, level as lv
from scott.emp a
start with mgr is null
connect by (prior empno) = mgr
order by level;
--result 1
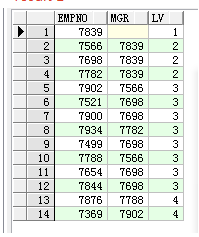
--分析
层次查询执行逻辑:
a.确定上一行(相对于步骤b中的当前行),若start with 子句存在,则以该语句确定的行为上一行,若不存在则将所有的数据行视为上一行。
b.从上一行出发,扫描除该行之外所有数据行。
c.匹配条件 (prior empno) = mgr
注意 一元运算符 prior,意思是之前的,指上一行
当前行定义:步骤b中扫描得到的所有行中的某一行
匹配条件含义:当前行字段 mgr 的值等于上一行字段 empno中的值,若满足则取出该行,并将
level + 1,
匹配完所有行记录后,将满足条件的行作为上一行,执行步骤 b,c。直到所有行匹配结束.
2.1 从根节点自底向上
--sql 2
select empno, mgr, level as lv
from scott.emp a
start with empno = 7876
connect by (prior mgr ) = empno
order by level;
--result 2
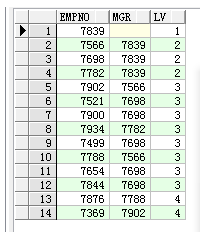
--分析
层次查询执行逻辑:
a.确定上一行(相对于步骤b中的当前行),若start with 子句存在,则以该语句确定的行为上一行,若不存在则将所有的数据行视为上一行。
b.从上一行出发,扫描除该行之外所有数据行。
c.匹配条件 (prior mgr ) = empno
注意 一元运算符 prior,意思是之前的,指上一行
当前行定义:步骤b中扫描得到的所有行中的某一行
匹配条件含义:当前行字段 empno 的值等于上一行字段 mgr 中的值,若满足则取出该行,并将
level + 1,
匹配完所有行记录后,将满足条件的行作为上一行,执行步骤 b,c。直到所有行匹配结束.
若不理解上一行当前行看此例子
select child_id, parent_id, level as lv
from table_name
start with child_id = 10
connect by (prior child_id) = parent_id;
step1.将下面一行作为上一行
step2..从上一行出发,扫描除该行之外所有数据行
step3.匹配条件 (prior child_id) = parent_id,
取出除上一行之外的数据行如
比较当前行的 parent_id 与上一行的 child_id,若相等则取出该行作为上一行的子行。
当上一行的子行全部取出后,将子行再作为上一行,重复步骤1,2
结果示意图如下
自顶向下,自下向上口诀:
start with child_id = 10 connect by (prior child_id) = parent_id
prior 和 子列在一起,表示寻找它的子孙,即自顶向下,和父列在一起,表示开始寻找她的爸爸,即自下向上。
---------------------
原文作者:July0_N