1.介绍
爬虫采集了大量的文本数据,如何进行去重?可以使用文本计算MD5,然后与已经抓取下来的MD5集合进行比较,但这种做法有个问题,文本稍有不同MD5值都会大相径庭,
无法处理文本相似问题。另一种方式是本文要介绍的SimHash,这是谷歌提出的一种局部敏感哈希算法,在吴军老师的《数学之美》里也有介绍,这种算法可以将文本降维成一个
数字,极大地减少了去重操作的计算量。SimHash算法主要分为以下几个步骤:
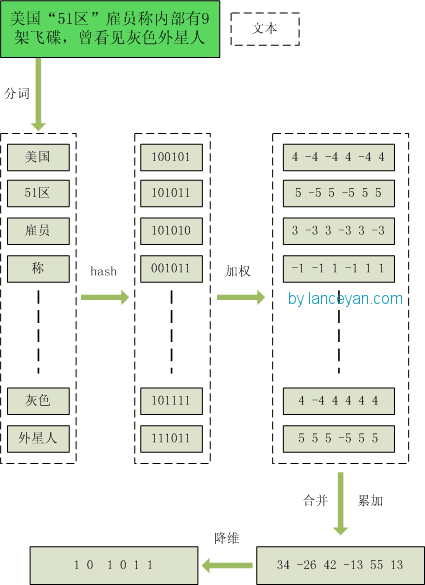
1.分词,并为每个词加上权重,代表这个词在这句话中的重要程度(可以考虑使用TF-IDF算法)
2.哈希,分好每个词映射为哈希值
3.加权,按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4.合并,把上面各个单词算出来的序列值累加,变成只有一个序列串
5.降维,如果序列串每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
2.SimHash的比较
根据上面的步骤可以计算出每个文本的一个SimHash值,两个SimHash的相似度就是通过比较不同二者数位的个数,这叫做海明距离,比如10101 和 00110 ,海明距离
为3。
3.比较效率的提高
加入我们已经有了一个simhash库,现在有一个query过来需要查询是否库里存在与这个query海明距离为1到3的文本,如何查询?
方式1. 将这个query的海明距离为1到3的结果实时计算出来,然后依次在库里查找,缺点:海明距离为1到3的结果可能有上万个,逐个查询效率肯定很低。
方式2.将库里每个simhash海明距离为1到3的结果事先离线计算出来,这样每个查询只需要O(1)的复杂度。缺点:需要的存储空间非常大。
待续。。。。