本文主要来梳理下Oracle中的常用的系统函数,掌握这些函数的使用,对于我们编写SQL语句或PL/SQL代码时很有帮助,所以这也是必须掌握的知识点。
本文主要包括以下函数介绍:
1.字符串函数
2. 数值函数
3. 日期函数
4. 转换函数
5. NULL 函数
6. 聚合函数
7. 系统函数
8. 其他函数
一、字符串函数
1、length
语法:length(p_string)
解释:返回字符串的字符长度,如果p_string为NULL或为空,则返回NULL。
示例:
SELECT length('ab 中国') col1, length(' ') Col2, length('') Col3, length(NULL) Col4 FROM dual;

2、lengthb
语法:lengthb(p_string)
解释:返回字符串的字节长度,如果 p_string 为NULL或为空,则返回NULL。
示例:
SELECT lengthb('ab 中国') col1, lengthb(' ') Col2, lengthb('') Col3, lengthb(NULL) Col4 FROM dual;

说明:Col1中包含两个中文“中国”,一个中文占两个字节,所以一共是7个字节。
3、ascii
语法:ascii(p_character)
参数:p_character: 要检索ASCII码的字符,如果包含多个字符,只返回第一个字符的ASCII码,忽略之后的所有字符。
解释:返回指定字符对应的ASCII码。该函数与chr函数功能是相反的。
示例:
SELECT ascii('李') col1, ascii('A') col2, ascii('a') col3, ascii('0') col4, ascii(' ') col5, ascii('abc') col6 FROM dual;

4、chr
语法:chr(p_number [using nchar_cs])
参数:p_number: 用于检索的 ASCII 码数字代码。
using nchar_cs: 如果指定该参数,将返回国家字符集相对应的字符。
解释:返回指定ASCII码对应的字符。该函数与ascii函数功能是相反的。
示例:
SELECT chr(49390) col1, chr(65) col1, chr(97) col3, chr(48) col4, chr(32) col5, chr(49390 using nchar_cs) col6 FROM dual;

5、cancat
语法:cancat(p_value1, p_value2)
参数:
p_value1: 要连接的第一个值(可以是非字符类型);
p_value2: 要连接的第二个值(可以是非字符类型);
解释:用于连接两个值,这个值可以是数字、日期、或其他类型。cancat之所以可以传递非字符类型,应该是在函数内部进行了类型转换(个人分析)。
示例:
SELECT concat('he', 'llo') col1, concat('数字:', 12.5) col2, concat('日期:', sysdate) col3, concat('NULL:', NULL) col4 FROM dual;
通常情况下,我们连接字符串习惯用"||"连接符,而不是使用cancat函数,因为cancat函数同时只能连接两个字符串,而"||"连接符可以同时连接多个,例如:
SELECT (123 || 12.5 || sysdate || '很晚了') col1, concat('该睡觉了', '吗?') col2 FROM dual;

6、upper
语法:upper(p_string)
解释:将指定的字符串中的所有字母都转为大写。
示例:
SELECT upper('Hello woRld') col1, upper('中国') col2, upper(NULL) col3 FROM dual;

7、lower
语法:lower(p_string)
解释:将指定的字符串中的所有字母都转为小写。
示例:
SELECT lower('hEllo ABEAM') col1, lower('中国') col2, lower(NULL) col3 FROM dual;

8、initcap
语法:initcap(p_string)
参数:p_string: 需要转换的单词字符串。
解释:返回指定单词字符串转换后的字符串,通过(空格、制表符、回车符、换页符、垂直制表符、换行符)分隔每个单词,将首字母转为大写,其他字母全部转为小写。
示例:
SELECT initcap('hello World') col1, initcap('_ello 2orld') col2, initcap('HELLO WORLD') col3, initcap('中国') col4, initcap(NULL) col5 FROM dual;

注意:如果第一个字符不是字母,将继续寻找下一个为字母的字符进行转换,直到遇到第一个为字母的字符。
9、 substr
语法:substr(p_string, p_start_position [, p_length])
参数:
p_string: 源字符串;
p_start_position: 提取子字符串的起始位置(包含该位置的子串);
p_length: 可选的。提取子字符串的长度,如果省略该参数,将从 p_start_position 指定的位置提取到源字符串的结尾。
解释:从源字符串中提取子字符串。
示例:
SELECT substr('hello', 2) col, substr('hello', 2, 2) col2, substr('hello', 7) col3, substr('hello', 0) col4, substr('hello', -1) col5, substr('hello', -3, 3) col6, substr('hello', 1, -1) col7 FROM dual;

注意:
①p_start_position为负数时,将从字符串末尾向开始计算起始位置,并向后开始取指定长度;
② p_length为负数时,将返回NULL。
③oracle字符串索引从1开始。
10、substrb
语法:substrb(p_string, p_start_position [, p_length])
参数:与 substr 函数相同。
解释:从源字符串中提取子字符串,注意:substrb 是按字节位置和长度进行提取的,而不是字符。
示例:
SELECT substr('a爱b中c国1', 3, 3) col1, substrb('a爱b中c国1', 3, 3) col1 FROM dual;

注意:当遇到位置或长度位于中文字节中(不完全包括)时,将以空格字符填充。
11、replace
语法:replace(p_string, p_substring, p_new_substring)
参数:
p_string: 需要替换的源字符串;
p_substring: 被替换的子字符串;
p_new_substring: 替换的子字符串。
解释:在源字符串中,根据指定的子字符串,替换为另一个子字符串,返回被替换后的字符串。
示例:
SELECT replace('hello world', 'world', 'abeam') col1, replace('hello world', 'l', 'X') col2,replace('hello', '你', '我') col3, replace('', 'a', 'b') col4, replace(NULL, 'a', 'b') col5 FROM dual;

说明:如果源字符串中存在多个被替换的字符串,将全部替换掉;如果为找到匹配的字符串,则返回源字符串;如果源字符串为NULL或为空,则返回NULL。
12、lpad
语法:lpad(p_string, p_padded_length [, p_pad_string])
参数:
p_string: 指定需要填充或截断的字符串;
p_padded_length: 指定被填充或截断的长度,如果小于原字符串长度则进行截断;
p_pad_string: 可选的。指定填充的字符串,默认为空格。
解释:填充或截断指定的字符串到指定长度。填充从左侧,截断则从右侧。
示例:
SELECT lpad('hello', 2) col1, lpad('hello', 7) col2, lpad('hello', 7, '#') col3, lpad('hello', 7, '###') col4 FROM dual;

注意:
①. 当指定的 p_padded_length 不足字符串长度时,会进行截断到指定长度;
②. 当指定的 p_pad_string 字符追加到原字符后,超过指定长度时,也将会截断到指定长度。
③. 所以 lpad 函数还可以用于截断字符串的场景。
13、rpad
语法:lpad(p_string, p_padded_length [, p_pad_string])
参数:与lpad函数相同。
解释:填充或截断指定的字符串到指定长度。填充从右侧,截断也从右侧。
示例:
SELECT rpad('hello', 2) col1, rpad('hello', 7) col2, rpad('hello', 7, '#') col3, rpad('hello', 7, '###') col4 FROM dual;

14、instr
语法:instr(p_string, p_substring [, p_start_position [, p_occurrence]])
参数:
p_string: 要搜索的字符串;
p_substring: 在 p_string 中搜索的子字符串;
p_start_position: 可选的。指定搜索的起始位置(包含该位置),默认为1;如果为负数,则从字符串末尾开始搜索,任然从头部计算位置。
p_occurrence: 可选的。表示搜索 p_substring 出现的第几次,默认为1。
解释:返回字符串中子字符串的字符位置,未搜索到子字符串返回0。注意,字符串起始位置为1。
示例:
SELECT instr('hello', 'e') col1, instr('hel_lo', 'l', 4, 1) col2, instr('hello', 'l', -1) col3, instr('hello', 'a') col4 FROM dual;

15、instrb
语法:instrb(p_string, p_substring [, p_start_position [, p_occurrence]])
参数:与 instr 函数相同。
解释:返回字符串中子字符串的位于的字节位置,未搜索到子字符串返回0。注意,字节起始位置为1。
示例:
SELECT instr('你好,abeam', 'b') col1, instrb('你好,abeam', 'b') col2 FROM dual;
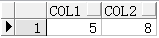
注意:因为在ZHS16GBK字符集中,一个英文占一个字节,而一个中文占两个字节,所以b的字节位置为8。
16、ltrim
语法:ltrim(p_string [, p_trim_string])
参数:
p_string: 指定需要移除的原字符串;
p_trim_string: 可选的。需要移除的子串,可以为多个字符,当为多个字符时,将逐一匹配,直到任意一个字符都不匹配时结束。未指定该参数时,默认为空格。
解释:从字符串左侧移除指定的子串,未指定子串时,默认移除前导空格。
示例:
SELECT ltrim(' Abeam') col1, ltrim('000123', '0') col2, ltrim('101100abc', '10') col3, ltrim('2563b9', '12345') col4 FROM dual;

注意:会将子串中的每个字符进行匹配,直到所有字符都不匹配时结束。
17、rtrim
语法:rtrim(p_string [, p_trim_string])
参数:与 ltrim 函数相同。
解释:从字符串右侧移除指定的子串,未指定子串时,默认移除尾随空格。
示例:
SELECT rtrim(' Abeam ') col1, rtrim('000123000', '0') col2, rtrim('101100abc101100', '10') col3, rtrim('2563b9625', '12345') col4 FROM dual;

18、 trim
语法:trim([[ LEADING | TRAILING | BOTH ] p_trim_character FROM] p_string)
参数:
LEADING: 表示将从左侧移除子串;
TRAILING: 表示将从右侧移除子串;
BOTH: 表示从两侧移除子串;
p_trim_character: 需要移除的子串,可以为多个字符,当为多个字符时,将逐一匹配,直到任意一个字符都不匹配时结束。未指定该参数时,默认为空格。
解释:从字符串的左侧、右侧或者两侧移除指定的子串,未指定子串时,默认移除两侧空格。
示例:
SELECT trim(' Abeam ') col1, trim(leading '0' from '00Abeam00') col2, trim(trailing '0' from '00Abeam00') col3, trim(both '0' from '00Abeam00') col4 FROM dual;

注意:与ltrim和rtrim相比,trim中的子串只能指定一个字符,否则会报错:

二、数值函数
1、 ceil
解释:返回大于或等于指定数字的最小整数。
示例:
SELECT ceil(12.456) col1, ceil(12) col2, ceil(-12.5) col3 FROM dual;

2、 floot
解释:返回小于或等于指定数字的最大整数。
示例:
SELECT floor(12.456) col1, floor(12) col2, floor(-12.5) col3 FROM dual;

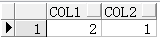
3、 mod
解释:返回一个数除以另一个数的余数。
示例:
SELECT mod(5, 3) col1, mod(9, 4) col2 FROM dual;
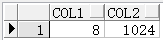
4、 power
解释:返回一个数的N次方根。
示例:
SELECT power(2, 3) col1, power(2, 10) col2 FROM dual;
5、round
解释:四舍五入到指定的小数位,未指定小数位时默认取整数。
示例:
SELECT round(25.4) col1, round(25.5) col2, round(22.345, 2) col3, round(140, -2) col4, round(150, -2) col5 FROM dual;

注意:指定小数位为负数时,将对整数位进行四舍五入。
6、 trunc
语法:trunc(number [, decimal_places])
参数:number: 要截断的数字;
decimal_places: 可选的。要截断的小数位数,该值必须是整数。如果省略此参数,则TRUNC函数会将数字截断为0个小数位。
解释:将一个数字截取到指定的小数位,未指定小数位时默认取整数。
示例1:
SELECT trunc(25.4) col1, trunc(25.5) col2, trunc(22.345, 2) col3, trunc(140, -2) col4, trunc(150, -2) col5 FROM dual;

注意:指定小数位为负数时,将对整数位进行进行截取。
示例2:
另外,trunc() 函数还可以用于截取日期,例如:
SELECT sysdate, trunc(SYSDATE, 'yyyy') col1 FROM dual;

7、sign
解释:判断一个数字为正数还是负数,当大于0返回1,小于0返回-1,等于0则返回0。
示例:
SELECT sign(1) col1, sign(-1) col2, sign(0) col3, sign(0.1) col4, sign(-0.1) col5 FROM dual;

8、exp
解释:返回一个数字 e 的 n 次方根,e=2.7182818。
示例:
SELECT exp(2) col1, exp(3) col2 FROM dual;

三、日期函数
1、sysdate
解释:获取系统的当前时间。
示例:
SELECT sysdate col1, '马上快跨年了' col2 FROM dual;

2、systimestamp
解释:获取系统的当前时间(毫秒)/时间戳。
示例:
SELECT systimestamp col1, '恩,还有一个小时' col2 FROM dual;

3、 add_months
解释:对指定的日期增加或减去月份,为负数时则为减。
示例:
SELECT ename, hiredate, add_months(hiredate, 12) col2, add_months(hiredate, -12) col3 FROM emp;

4、last_day
解释:返回指定日期当月的最后一天的日期。
示例:
SELECT ename, hiredate, last_day(hiredate) col1 FROM emp;

5、months_between
解释:返回两个日期相隔的月份。
示例:
SELECT months_between(date'2019-12-31', date'2019-12-1') col1, months_between(date'2019-12-31', date'2019-11-30') col2, months_between(date'2019-12-31', date'2019-11-25') col3, months_between(date'2019-12-31', date'2020-12-31') col4, months_between(date'2019-12-31', date'2019-12-31') col5 FROM dual;

6、next_day
解释:返回指定日期之后的指定星期X的日期。
示例:
SELECT next_day(date'2019-12-15', '星期一') col1, next_day(date'2019-12-15', '星期三') col2, next_day(date'2019-12-15', '星期六') col3, next_day(date'2019-12-15', '星期日') col4 FROM dual;


四、转换函数
1、 to_char
语法:to_char(p_value [,p_format])
参数:
p_value: 指定需要转换的值;
p_format: 可选的。指定转换的格式,如下:
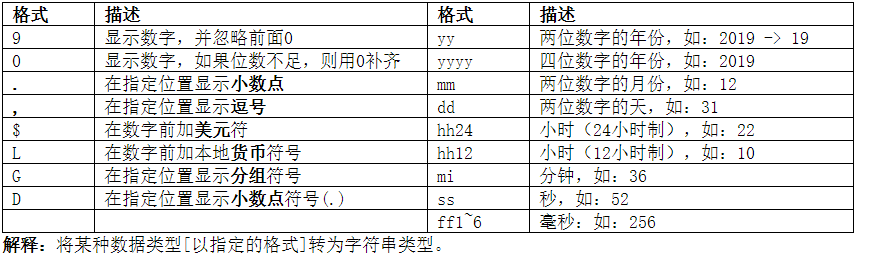
示例1:
SELECT sal, to_char(sal) col1, ltrim(to_char(sal, 'L99G999D99')) col2, hiredate, to_char(hiredate, 'yyyy-mm-dd hh24:mi:ss') col3, to_char(hiredate, 'yyyy') col4, to_char(hiredate, 'mm') col5, to_char(hiredate, 'dd') col6 FROM emp;

示例2:
SELECT systimestamp, to_char(systimestamp, 'yyyy-mm-dd hh24:mi:ss ff3') col1, to_char(systimestamp, 'ff2') col2 FROM dual;

2、 to_date
语法:to_date(p_value, p_format)
参数:
p_value: 指定需要转换的值;
p_format: 指定转换格式,如下:

示例:
SELECT to_date('2019-12-29', 'yyyy-mm-dd') Col1, to_date('2019-12-29 22:15:36', 'yyyy-mm-dd hh24:mi:ss') Col2, to_date('2019-12-29 10:15:36', 'yyyy-mm-dd hh12:mi:ss') Col3 FROM dual;

注意:
①当小时格式指定为12小时制时,字符串中的小时部分必须在1~12之间;
②to_date 函数不支持带有毫秒的日期字符串转换。
3、 to_timestamp
语法:(p_string [, format_mask] ['nlsparam'])
参数:
p_string: 将转换为时间戳的字符串。
format_mask: 可选的。这是将 p_string 转换为时间戳的格式。
解释:将字符串转换为时间戳。
示例:
SELECT to_timestamp('2019-12-29 10:15:36.12345', 'yyyy-mm-dd hh24:mi:ss.ff') Col1, to_timestamp('2019-12-29 10:15:36 999', 'yyyy-mm-dd hh24:mi:ss ff3') Col2 FROM dual;

4、to_number
解释:将指定的字符串转为数字。
示例:
SELECT to_number('356') col1, to_number('-356') col2, to_number('35.6') col3, to_number('0.6') col4, to_number(NULL) col5 FROM dual;

注意:当转换失败时将报错。
5、decode
语法:decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值)
解释:该函数类似于编程中 switch 语句的功能。根据指定的值,检索匹配的项,并返回该项对应的值。未匹配到对应的项时,则返回缺省值,不指定缺省值默认为 NULL。
示例:
SELECT ename, deptno, decode(deptno, 10, '10号部门', 20, '20号部门', 30, '30号部门') col1, decode(ename, 'SMITH', '史密斯', '未知') col2, decode(NULL, 10, '10') col3 FROM emp;

未匹配到项时,则返回缺省值。
五、NULL函数
1、nvl
语法:nvl(exp1, exp2)
解释:判断第一个表达式是否为 NULL,当 exp1 不为 NULL 时,返回 exp1;当 exp1 为 NULL 时返回 exp2;exp2 可以为 NULL,否则必须与 exp1 的数据类型一致(或者可以隐式)。
示例:
SELECT ename, comm, nvl(comm, 101) col1, nvl(comm, '101') col2, nvl(comm, NULL) col3 FROM emp;

2、nvl2
语法:nvl2(exp1, exp2, exp3)
解释:判断第一个表达式是否为 NULL,当 exp1 不为 NULL 时,返回 exp2(与 nvl 区别1);当 exp1 表达式为 NULL 时,返回 exp3;exp1, exp2, exp3 的数据类型不需要一致(与 nvl 区别2)。
示例:
SELECT ename, comm, nvl2(comm, 101, 201) col1, nvl2(comm, comm, 101) col2, nvl2(comm, '非空', sysdate) col3 FROM emp;

可见,其实 nvl2 可以完全取代 nvl,例如:nvl2(comm, comm, 101)
3、coalesce
语法:coalesce(exp1, exp2, exp3 […, expn])
解释:从左往右返回第一个为非 NULL 的值。注意:所有指定的值必须为同一个数据类型,就算支持隐式转换都不可以。
示例:
SELECT coalesce(NULL, 0, 1, 2) col1, coalesce(1, NULL, 0, 2) col2 FROM dual;

其实 coalesce 也可以取代 nvl,例如:
SELECT ename, comm, coalesce(comm, 101) col1, coalesce(comm, NULL) col2 FROM emp;

区别在于,nvl 支持类型的隐式转换,而 coalesce 不支持。
4、nullif
语法:nullif(exp1, exp2)
解释:判断两个表达式的值是否相等,相等则返回 NULL,否则返回 exp1。
示例:
SELECT nullif('ab', 'ab') col1, nullif('ab', NULL) col2, nullif('ab', 'aB') col3 FROM dual;

注意:nullif 中的 exp1 不能显示指定为 NULL(如:nullif(NULL, 'abc')),exp2 可以为 NULL。但是在判断字段时(字段中可以包含有 NULL 的值)可以,例如:
SELECT comm, nullif(comm, NULL) col1 FROM emp;

六、聚合函数
1、count
解释:返回统计的数量,可以指定 DISTINCT 和 ALL 参数,默认为 ALL 选项。
示例:
SELECT count(deptno) col1, count(all deptno) col2, count(distinct deptno) col2 FROM emp;

2、max
解释:返回值列表中的最大值,可以指定 DISTINCT 和 ALL 参数,默认为 ALL 选项。
示例:
SELECT max(sal) col1, max(all sal) col2, max(distinct sal) col3 FROM emp;

提示:distinct 和 all 参数在 max 中并没有实际的意义。
3、min
解释:返回值列表中的最小值,可以指定 DISTINCT 和 ALL 参数,默认为 ALL 选项。
示例:
SELECT min(sal) col1, min(all sal) col2, min(distinct sal) col3 FROM emp;

提示:distinct 和 all 参数在 min中并没有实际的意义。
4、sum
解释:对值列表中的所有值进行求和,可以指定 DISTINCT 和 ALL 参数,默认为 ALL 选项。
示例:
SELECT sum(sal) col1, sum(all sal) col2, sum(distinct sal) col3 FROM emp;

5、avg
解释:返回值列表中的平均值,可以指定 DISTINCT 和 ALL 参数,默认为 ALL 选项。
示例:
SELECT avg(sal) col1, avg(all sal) col2, avg(distinct sal) col3 FROM emp;

七、系统函数
1、uid
解释:返回当前用户的唯一整数。
示例:
SELECT uid FROM dual;

在 sys 或 system 用户下可以也可查看到:
select user_id, username from dba_users;
2、user
解释:返回当前用户的用户名。
示例:
SELECT user FROM dual;

3、sys_context
语法:sys_context(p_namespace, p_parameter)
参数:
p_parameter:

还有些其他参数,这里就不在列举了。
解释:sys_context 是一个 Oracle 数据库的综合函数,用于获取数据库相关信息,比如:数据库字符集、实例名等。
示例:
SELECT
sys_context('userenv', 'terminal') col1,
sys_context('userenv', 'language') col1,
sys_context('userenv', 'db_name') col3,
sys_context('userenv', 'nls_date_format') col4,
sys_context('userenv', 'sessionid') col5,
sys_context('userenv', 'session_userid') col6,
sys_context('userenv', 'session_user') col7,
sys_context('userenv', 'current_schema') col8,
sys_context('userenv', 'host') col9,
sys_context('userenv', 'ip_address') col10 FROM dual;

八、其他函数
1、greatest
语法:greatest(expr_1, expr_2, ...expr_n)
解释:返回一组表达式中的最大值,以第一个表达式的数据类型为标准。当其他表达式与第一个表达式的类型,隐式转换失败时则报错。
示例:
SELECT greatest(2, 5, 3) colo1, greatest(2, '5', 3) col2, greatest('b', 'B', 'a') col3, greatest('b', 'cB', 'a') col4, greatest(date'2019-12-05', date'2019-12-06', date'2019-11-06') col5, greatest('中', '华', '人') col6, greatest(NULL, 'a', 'b') col7 FROM dual;

说明:
①greatest(2, '5', 3) 将会对 "5" 隐式转为数字类型,转换失败时则报错;
②greatest('b', 'cB', 'a') 将抽取首字母进行比较。
③greatest(NULL, 'a', 'b') 当第一个表达式为 NULL 时,始终返回 NULL。
注意:在比较字符的过程中,是先将字符转为 ascii 码,再取 ascii 码最大的字符。为验证这一点,我们查看以上字符的 ascii 码:
SELECT ascii('a') "a", ascii('b') "b", ascii('c') "c", ascii('B') B, ascii('中') 中, ascii('华') 华, ascii('人') 人 FROM dual;

2、least
语法:least(expr_1, expr_2, ...expr_n)
解释:与greatest函数相同,但least函数是返回一组表达式中的最小值。
示例:
SELECT least(2, 5, 3) colo1, least(2, '5', 3) col2, least('b', 'B', 'a') col3, least('b', 'cB', 'a') col4, least(date'2019-12-05', date'2019-12-06', date'2019-11-06') col5, least('中', '华', '人') col6, least(NULL, 'a', 'b') col7 FROM dual;

3、dump
dump() 函数可以获取一个值的相关信息,比如:数据类型代码、字节长度和表达式的内部表示形式等。
语法:dump(expression [, return_format] [, start_position] [, length])
参数:
expression:要分析的表达式;
return_format:可选的。决定了返回值的格式,该参数可以是以下任何值:
①8:八进制符号
②10:十进制符号(默认值)
③16:十六进制符号
④17:单个字符
⑤1008:带字符集名称的八进制符号
⑥1010:带字符集名称的十进制符号
⑦1016:带字符集名称的十六进制符号
⑧1017:带字符集名称的单个字符
start_position:可选的,要返回的内部表示的起始位置;
length:可选的,要返回的内部表示的长度。
示例:
SELECT dump('abc') col3, dump(123) col2, dump(sysdate) col3 FROM dual;

Typ 表示该值的数据类型;Len 表示占用的字节长度;": xx,xx" 表示内部存储的字节数值。