下面这些是我在面试和笔试的时候碰到过的比较常见的问题,有些不难,但是就内容太多了,一时难以想起。
1.公有私有保护成员、公有私有保护继承
公有成员:在类外可以通过对象直接访问。
私有成员:对外隐藏,对子类开放,在类内部使用(在类的成员函数中使用)。
保护成员:对外隐藏,只在类内部使用(在类中的成员函数使用)。
公有继承:基类的公有成员和保护成员作为派生类的成员时,都保持原有的状态,但是基类的私有成员仍然是私有的,不能被子类访问。
私有继承:基类的公有成员和保护成员成为了派生类的私有成员,并且不能被派生类的子类访问。
保护继承:基类的公有成员和保护成员都成为了派生了的保护成员,只能被派生类的成员函数或者友元访问,基类的私有成员仍然是私有的。
2.什么是多态?多态的实现原理是什么?
多态就是在基类的函数前面加上virtual关键字,然后在派生类中重写这个函数(覆盖虚表),运行的时候就会根据实际的对象类型来调用相应的函数,如果是派生类,就调用派生类的函数,如果是基类,就调用基类的函数。
3.数组与链表的异同
数组是将元素在内存中连续存放的,每个元素占用的内存相同,所以可以通过数组下标快速访问数组中的元素,如果在数组中增加一个元素,那么就要移动大量的数据,删除也是一样。如果是需要快速访问,但是很少插入和删除的数据,就应该用数组。
链表中的元素在内存中是不按顺序存放的,是通过元素中的指针练习到一起,每个节点包括两部分,元素数据和指向下一个节点地址的指针。如果要访问链表中的元素,需要从第一个元素开始,一直找到元素的位置,插入和删除对于链表十分简单。如果是需要经常插入和删除的数据,用链表就比较方便。
4.什么是线性表?线性表有哪些种类?
线性表是数据结构的一种,一个线性表是n个具有相同特性的数据元素的优先序列。线性表有以下特点:
(1)集合中必然存在唯一的一个“第一个元素”
(2)集合中必然存在唯一的一个"最后一个元素"
(3)除最后一个与元素之外,每个元素都有唯一的后继
(4)除第一个元素之外,每个元素都有唯一的前驱。
线性表分为顺序存储和连式存储。
顺序存储:顺序表,使用数组实现,一组连续的存储单元,数组的大小有两种方式制定,静态分配和动态扩展。
优点:随机访问特性,查找O(l)时间,存储密度高,逻辑上相邻的元素,物理上也相邻。
缺点:插入和删除需要移动大量的元素。
链式存储:单链表、双链表、循环链表、静态链表。
5.队列与栈的异同
栈和队列都是线性表,都是限制了插入删除点的线性表。
共同点:都是只能在线性表的端点插入和删除。
不同的点:栈的插入和删除都是在线性表的同一个端点,俗称栈顶,不能插入和删除的端点称为栈顶,特性是先进后出。
队列是在线性表的表头插入,表位删除,表头一般称为对头,表位称为队尾,特性是先进后出。
5.获取触摸屏信息的函数(项目)
linux系统中有个input_event()函数可以获取触摸屏的触摸数据,可以获取的事件类型有按键事件、同步事件、相对坐标事件、绝对坐标事件。
6.linux系统文件类型
普通文件(-):ELF文件,文本文件
目录文件(d)
字符设备文件(c):访问字符设备
块设备文件(b):访问块设备
链接文件(l):相当于快捷方式
管道文件(p):用于管道通信
套接字文件(s):用于socket通信
7.TCP/UDP通信
TCP的特点:面向连接,只支持一对一,面向字节流,可靠的传输
UDP的特点:无连接,不可靠传输,支持一对一,一对多,面向报文
TCP为什么是可靠传输:
(1)通过TCP连接传输的数据无差错,不丢失,不重复,且按顺序到达。
(2)TCP报文头里面的序号能使TCP的数据按序到达
(3)报文头里的确认序号能保证不丢包,累计确认及超时重传机制。
(4)TCP拥有流量控制及拥塞控制的机制。
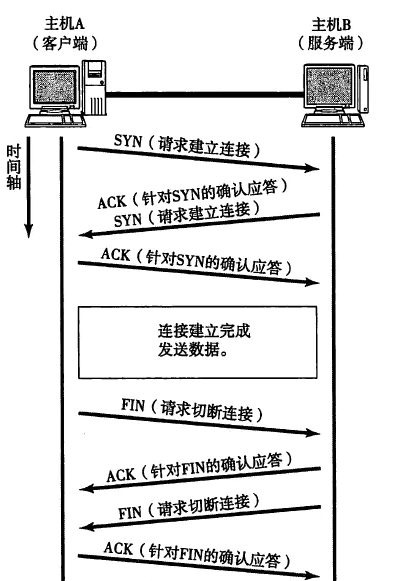
8.TCP的三次握手/四次挥手
三次握手:
(1)SYN请求建立连接:客户端向服务端发送请求报文;即SYN=1,ACK=0,seq=x。建立连接时,客户端发送SYN包(syn=j)到服务端,并进入SYN_SENT状态,等待服务器确认;
(2)ACK针对SYN的确认应答,SYN(请求建立连接):服务器收到SYN包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYNC_RECV状态;
(3)ACK针对SYN的确认应答:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务端进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
这样连接建立完成,发送数据
四次握手:
(1)FIN请求切断连接:TCP发送一个FIN(结束),用来关闭客户到服务端的连接。客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
(2)ACK针对FIN的确认应答:服务端收到这个FIN,他发回一个ACK(确认),确认收到序号为收到序号+1,和SYN一样,一个FIN将占用一个序号。服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
(3)FIN请求切断连接:服务端发送一个FIN(结束)到客户端,服务端关闭客户端的连接。服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
(4)ACK针对FIN的确认应答:客户端发送ACK(确认)报文确认,并将确认的序号+1,这样关闭完成。客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
9.CJSON
10.进程与线程
进程是系统资源分配和调度的基本单位,是操作系统结构的基础。实际上就是在系统中正在运行的一个应用程序,程序一旦开始运行就是进程,进程----分配资源的最小单位。
线程是操作系统进行运算调度的基本单位。系统分配处理器时间资源的基本单元,或者说是进程之类独立执行的一个单元执行流。
1、一个进程可以有多个线程,但至少有一个线程;而一个线程只能在一个进程的地址空间内活动。
2、资源分配给进程,同一个进程的所有线程共享该进程所有资源。
3、CPU分配给线程,即真正在处理器运行的是线程。
4、线程在执行过程中需要协作同步,不同进程的线程间要利用消息通信的办法实现同步。
11.算法复杂度
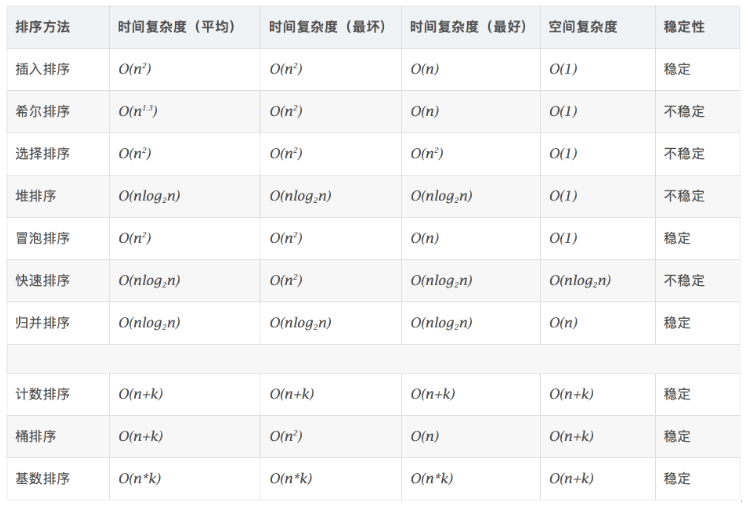
稳定:如果a原本在b的前面,而a=b,排序之后a仍然在b的前面。
不稳定:同上,但是排序后a在b的后面。
时间复杂度:对排序算法的总操作次数,反应出当要排序的数列长度n变化时,操作次数呈现的规律。
空间复杂度:指的是算法在计算机内执行的时候所需的存储空间的度量,也是数据规模为n的函数。
12.什么事内存泄漏?内存泄漏有哪些?怎么避免内存泄漏?
内存泄漏值得就是在程序动态申请的内存在使用完之后,却没有进行释放,导致这片内存没有被系统回收,就会占用着内存,导致程序的内存变大,系统内存不足。
内存泄漏的分类如下:
堆内存泄漏:堆内存指的就是通过new,malloc等函数从堆中申请的堆存,用完之后必须通过delete,free释放掉,如果没有释放,就会导致这片空间没有办法被再次使用。
系统资源泄漏:程序在使用系统分配的资源(套接字、管道、文件描述符等)过后,没有释放,会导致资源浪费,甚至导致系统不稳定。
避免内存泄漏的方法:(1)养成良好的编码规范,申请的空间用完之后记得释放。(2)采用智能指针来管理资源。(3)使用检测工具来检测内存是否泄漏。
13.拷贝构造是什么?为什么要有拷贝构造?拷贝构造分为哪些类型?
对于普通的数据类型来说,他们之间的赋值是很简单的,但是对于有着复杂内部结构的类对象来说,拷贝就很麻烦了。拷贝构造函数是一种特殊的构造函数,函数名必须和类名一致,必须的参数是本类型的一个引用变量。很多时候编译器会默认生产一个“默认的拷贝构造函数”,这个生成的函数很简单,只是对旧对象的数据成员的值进行拷贝,用来给新对象的数据成员进行赋值。
拷贝构造函数分为浅拷贝和深拷贝,浅拷贝值得是在对象复制的时候,只是对对象中的数据成员进行简单的赋值,系统自动生成的拷贝构造函数就是浅拷贝,一般来说,浅拷贝都足够用了,但是当对象中存在动态成员,浅拷贝就会出现问题。这时候就要用到深拷贝了,深拷贝中,对于对象中的动态成员,会重新动态分配空间。当对象成员中有指针的时候,就要用到深拷贝,因为浅拷贝在对象结束的时候,会调用两次析构函数,但是只有一个东西要析构,就会造成指针悬挂(指针指向非法的地址)的现象。类中可以存在多个拷贝构造函数。
14.什么是智能指针?智能指针有哪些?
智能指针是一个类,类中的构造函数传入一个普通指针,析构函数释放传入的指针,这个类是栈上的对象,当程序或者函数结束的时候就会自动释放。
常用的智能指针有:(1)std::suto_ptr 不支持赋值和复制,编译的时候也不会报错(2)unique_ptr 同样不支持赋值和复制,但是编译的时候会报错 (3)shared_ptr 可以随便赋值,当内存的引用计数变成0的时候,会被释放 (4)weak_ptr
15.虚函数
用virtual关键字修饰的成员函数,如果一个类中包含虚函数,那么这个类的对象中就会包含一个虚表指针(存储在对象的最前面)。虚表是用来存储虚函数指针的。虚函数的调用过程:开始从虚表中查找,如果找到就执行,没有找到就去对象代码中找,找到就执行,还是没有找到就报错。
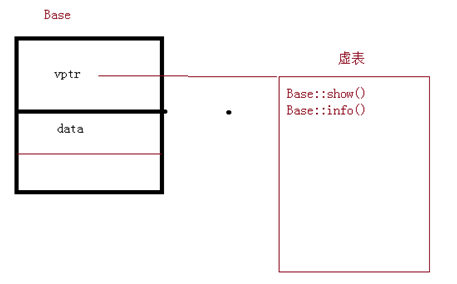
覆盖:如果父类中的虚函数在子类中重新实现(同名同参),虚表中的虚函数就会被子类的虚函数覆盖(只覆盖虚表),如果子类添加新的虚函数,该函数就会添加在虚表的后面。
17.什么是纯虚函数?
定义了但是不实现的虚函数叫做纯虚函数,纯虚函数相当于接口函数,如果一个类中包含了纯虚函数,那么这个类就是抽象类。
18.什么是抽象类?
抽象类不能创建对象(接口),如果基类中的纯虚函数在派生类中没有全部实现,那么派生类还是抽象类。
19.什么是虚析构?
在多态的实现过程中,把子类的指针赋值为父类指针,最后delete父类的指针,这个时候就只会调用父类的析构函数,不会调用子类的自购函数,如果把父类的析构函数设置成虚析构,那么delete就会自动从子类开始析构。
20.static关键字的作用
static修饰的特点:
(1)数据存储在数据段(局部全局)
(2)只分配一次空间,也只初始化一次
(3)修饰的变量或者函数只能在本文件中使用(文件作用域)
static修饰的类型:
(1)修饰成员变量
1.static修饰的成员变量空间不在对象空间中
2.static修饰的成员变量要在类外初始化(只初始化一次)
3.static修饰的成员变量就是为这个类的对象所共用
4.如果成员变量是公有的,就可以通过类名直接调用(先于类对象而存在)
(2)修饰成员函数
1.如果成员函数是公有的,就可以通过类名直接使用(先于类对象而存在)
2.静态成员函数中不能使用非静态的成员
21.const关键字的作用
(1)修饰变量,将这个变量变成常量,取代了C中的宏定义
(2)修指针和常量
(3)修饰函数传入的参数
(4)修饰函数返回值
(5)修饰成员函数和对象,const对象只能访问const成员函数,而非const对象可以访问任意的成员函数。conts对象的成员是不能修改的,但是通过指针维护的对象可以修改。const成员函数不能改变对象的值,不管这个对象是否被const修饰。
22.网络的七层模型、五层模型
OSI参考模型,从上到下是:
应用层:与其他计算机进行通讯的一个应用,解决通信双方数据传输的问题,传输协议有:HTTP FTP TFTP SMTP DNS HTTPS
表示层:定义数据格式以及加密,加密格式有JPEG,ASCII,DECOIC
会话层:定义了如何开始、控制和终止一个会话
传输层:定义传输数据协议的端口号、流控和差错校验,协议有TCP,UDP
网络层:进行逻辑地址寻址,实现不同网络之间的路径选择 协议有ICMP,IGMP,IP(IPV4,IPV6),ARP,RARP
数据链路层:建立逻辑连接,进行硬件地址寻址,用MAC地址访问介质,但是发现错误不能纠正。
物理层:建立、维护和断开连接。
五层模型:
应用层:为应用软件提供服务,屏蔽了网络传输的相关细节。
传输层:向用户提供一个可靠的端到端的服务,屏蔽了下层通信的细节。
网络层:为数据在节点之间传输创建逻辑链路。
数据链路层:在通信的实体之间简历数据链路连接。
物理层:定义物理设备之间如何传输数据。
23.select、pool、epoll的区别与优缺点
I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。select,poll,epoll都是IO多路复用的机制。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select
原理:select 的核心功能是调用tcp文件系统的poll函数,不停的查询,如果没有想要的数据,主动执行一次调度(防止一直占用cpu),直到有一个连接有想要的消息为止。从这里可以看出select的执行方式基本就是不同的调用poll,直到有需要的消息为止。
缺点:1、每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
2、同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
3、select支持的文件描述符数量太小了,默认是1024。
优点:1、select的可移植性更好,在某些Unix系统上不支持poll()。
2、select对于超时值提供了更好的精度:微秒,而poll是毫秒。
poll
原理:poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
缺点:1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义;
2、与select一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
优点:1、poll() 不要求开发者计算最大文件描述符加一的大小。
2、poll() 在应付大数目的文件描述符的时候速度更快,相比于select。
3、它没有最大连接数的限制,原因是它是基于链表来存储的。
epoll
原理:epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时, 返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一 个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射技术,这 样便彻底省掉了这些文件描述符在系统调用时复制的开销。
优点:1、支持一个进程打开大数目的socket描述符
2、IO效率不随FD数目增加而线性下降
3、使用mmap加速内核与用户空间的消息传递
三者的对比与区别:
1、select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
2、select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。

24.SQL数据库有哪些数据类型?有哪些特殊的关键字?
| char(n) | 存放固定长度的字符串,用户指定长度为n。如果没有使用n个长度则会在末尾添加空格。 |
| varchar(n) | 可变长度的字符串,用户指定最大长度n。char的改进版,大多数情况下我们最好使用varchar。 |
| int | 整数类型 |
| smallint | 小整数类型 |
| numeric(p,d) | 定点数,精度由用户指定。这个数有p位数字(包括一个符号位)d位在小数点右边。 |
| real ,double precision | 浮点数和双精度浮点数。 |
| float(n) | 精度至少位n位的浮点数 |
部分关键字:SELECT、INSERT、DELETE、UPDATE
特殊的关键字:primary key、foreign key references、not null
25.sizeof strlen的使用
sizeof可以用来计算数据在内存中占用的存储空间,以字节为单位进行计数。sizoef(int)=4;sizeof(指针)=系统位数=4(32位系统)
strlen用来计算指定字符的长度,但是不包括结束字符“ ”
26.switch的使用
switch中的case只能用来判断int型数据。
27.与或非
逻辑的与或非
&& 与操作,只有当两者都为真的时候,才会返回true,表达式会先去验证前面的一部分,如果前面一部分为真才回去验证后面的一部分,否则直接返回false。
|| 或操作,只要符号前后有一个为真,就会返回true,否则返回false。也是先验证前面的,前面的为false才会验证后面的,否则直接返回true。
!逻辑非,true变成false,false变成true。
按位与或非
&、|、~ 分别是按位与或非
5&6 = 0101 & 0110 = 4 5&&6 -> 计算原则: 非0即真 真&&真=真 5|6 = 0101 | 0110 = 7 5||6 -> 计算原则: 非0即真 真||真=真
28.数组、指针、数组指针、指针数组、函数指针、二级指针
之前做过一个公司的题目,就40道选择题,20几道指针,指来指去,指的我头皮发麻。
数组:
(1)数组只有初始化的时候可以整体赋值,之后只能一个一个单独赋值了。
(2)与普通变量一样,int数组在定义的时候不初始化,如果是全局变量,就全是0,如果是局部变量,就全是随机值。
(3)数组名 当sizeof()作用于数组名的时候,数组名就是整个数组的内存空间,返回值就是整个数组的大小;当数组名没有被sizeof()修饰的时候,数组名就是数组元素的首地址。
int A[3]; A 数组名 A[0] 数组首元素 &A[0] 数组首元素的地址 结论:A=&A[0]
指针
定义:指针指的是内存上的地址,例如:0x400000,指针是一个唯一的地址,能够确定申请到的内存空间在哪里。
指针变量:专门用来存放地址的变量,例如:int *p;
指针定义的步骤:
(1)先写一个* (2)在*后面写一个指针变量名(*p) (3)确定该指针所指向的内容 例如:int a (4)将第三部的变量名去掉 例:int (5)将第二部的结果放在第四部的结果后面 例:int *p,即指向一个int类型数据的指针变量
结果:int *p;//指针变量,变量名:p;数据类型:int *;
int a=100; int *p = &a;//将a的地址取出来给指针p
已知指针变量的值,如果求出该指针指向的内容?
取址符:& 已知变量a,求地址:&a
解引用:* 已知指针p,求变量:*p
&与*是一对逆运算。
指针运算,加减法:
加法:
int a; int *pa = &a; pa+1=? //+1是指向上移动一个单位,-是指向下移动,由于pa指向的是int型数据,pa+1就是向上移动一个单位
//移动4个字节,移动的字节数是根据数据类型来确定的
减法:
int a,c;
int *pa = &a;
int *pb = &c;
pa-pb=?;//结果就是两个指针在内存地址中相差多少个int型的字节
复杂指针:二级指针、数组指针、函数指针。
(1)二级指针:指向指针的指针(一般用二级指针,一般人不会闲得蛋疼去用三级、四级指针)
int a = 100;//在内存中连续申请4个字节的空间,使用变量a间接访问这片空间,将常量区100赋值给a。 int *pa = &a;//在内存中连续申请四个字节的空间,使用变量pa间接访问这片空间,将整型变量a的地址赋值给pa,即pa所指向的内存地址中存储的内容是变量a 的地址。 int **px = &pa;//在内存中连续申请4个字节的空间,使用变量px间接访问这片内存空间,将指针变量pa的地址赋值给px,即px所指向的内存空间存储的内容是指针pa的地址。
(2)数组指针:指向数组的指针。
int a; int A[3]; int *pa = &a; int (*pa)[3] = A[3];//表示这个指针指向一个具有三个int型数据的数组
解引用:
int a=100; int *pa = &a;//*pa得到100, int A[3] = {100,200,300}; int (*p)[3] = &A;
问题一:*p得到什么?得到数组首元素的地址,*p = *(&A) = A = &A[0]
问题二:p[0]/p[1]得到什么?什么也得不到,p[0] = *(p+0) = *p = &A[0],p[1] = *(p+1) = *(&A+1);//此时p+1已经越界访问了,解引用就是访问未知区域了。
问题三:(*p)[1]得到什么?(*p)[1] = (*&A)[1] = A[1] = 200
做指针运算的时候,记住两个公式:(1)&与*是一对逆运算,可以约掉;
(2)a[n]=*(a+n)
(3)函数指针:指向一个函数的指针。
定义函数指针:
int a; int fun(int x,int y) int *pa = &a; int (*p)(int,int) = &fun;//这个指针指向一个返回值为int类型,形式参数有两个int型数据的函数
数据类型:int (*p)(int,int) 变量名:p
在C语言中,函数的名字实际上就是函数的地址,int fun(int x,int y),函数名fun等价于&fun,即 int(*)(int,int)=&fun;
函数指针很少单独使用(定义一个指针,通过指针来调用函数),一般是用于接收函数的地址,及传递一个函数给另一个函数作为参数,形式参数就是一个函数指针。
29. 指针的用法
(1)在函数调用的时候改变某个变量的值。
经典例子:int *p;func(&p);如果这里想要改变p的值,就必须传p的地址,而p本身就是个指针,就有了二级指针的概念,二级指针一般只会出现在函数的形式参数列表中,不会随意定义。
(2)访问匿名内存的时候。
在C语言中,由于立即寻址空间访问硬件以及资源的原理,很多资源只是有着具体的地址,但是却没有变量名(能够用名字访问内存的只有局部变量或者全局变量(函数名是一个地址)),因此我们经常直接引用地址。例如:某GPIO数据寄存器的内存地址是0x12345678,我们会将该地址转化为指针,然后直接解引用该内存地址。
#define GPIO_DATA *((volatile unsigned int*)0x12345678
(3)优化加速函数调用
30.指针与数组的异同
(1)数组名不能给其赋值(指针常量)
(2)sizeof用来测量数组名,得到的是数组的大小,用来测量指针的话,永远是系统位数那么大
(3)在函数传参的过程中,函数的形式参数就是一个指针
(4)数组是不能通过函数返回出去的,语法不会报错,只是没有什么意义,会被释放掉
31.数据占用的内存空间的大小
| 数据类型 | 32位系统 | 64位系统 |
| void | 0 | 0 |
| char | 1 | 1 |
| int | 4 | 4 |
| short int | 2 | 2 |
| float | 4 | 4 |
| double | 8 | 8 |
| long | 4 | 8 |
| long double | 12 | 16 |
| long long | 8 | 8 |
| 指针 | 4 | 8 |
32.大小端存储
大端存储模式:数据的低位保存在内存的高地址中,数据的高位,保存在内存的低地址中。0x78563412
小端存储模式:数据的低位保存在内存的低地址中,数据的高位,保存在内存的高地址中。0x12345678
33.字符串处理函数的底层实现
char *strcpy(char *dest,const *src);//把后面的src字符串的内容拷贝到dest字符串当中,拷贝结束是以遇到"�"才停下。
char *strcat(char *dest,char *src);//将src字符串的内容合并到dest字符串的后面。
int strcmp(const char *str1,const char *str2);//比较两个字符串是否相等,原理是用字符相减的形式,如果相等,返回值为0,;如果不相等,返回值根据ASCII原理,返回正值(str1>str2),负值(str1<str2)。
size_t strlen(const char *s);//测量字符串的长度,不包括"�"结束符,该函数还可以用来测量指针。
strcpy以及strncpy的实现:
char *strcpy(char *s1,char *s2) { char *tmp=s1; while(*s1++=*s2++); return tmp; } char *strncpy(char *s1,char *s2,size_t n) { char *tmp=s1; while(n) { if(!(*s1++=*s2++))break;//遇到'�'就结束循环 n--; } while(n--)*s1++='�';//用'�'填充剩余的部分 return tmp; }
strcat以及strncat的实现:
char *strcat(char *s,char *s) { char *tmp=s1; while(*s1) s1++;//前进到s1的末尾处 while(*s1++=*s2++) ;//循环赋值直到遇到s2中的'�' return tmp; } char *strncat(char *s1,char *s2,size_t n) { char *tmp=s1; while(*s1) s1++;//前进到s1的末尾 while(n--) if(!(*s1++=*s2++))break;//遇到'�'就循环结束 *s1='�'; return tmp; }
strcmp以及strncmp的实现
int *strcmp(char *s1,char *s2) { while(*s1==*s2){ if(*s1=='�') return 0; s1++; s2++; } return (unsigned char)*s1-(unsigned char)*s2; } int *strncmp(char *s1,const char *s2,size_t n) { while(n && s1 && s2){ if(*s1 != *s2) return (unsigned char)*s1-(unsigned char)*s2; s1++; s2++; n--; } if(!n)return 0;//相等 if(*s1)return 1;//s1>s2 return -1;//s1<s2 }
strlen的实现
size_t strlen(const char *s) { size_t len=0; while(*s++) len++; return len; }
34.简述嵌入式操作系统的软硬件结构,以及它与通用操作系统的区别?以自己熟悉的嵌入式 处理器为例,简述从上电到程序运行的过程。(这个是做广州数控的软件开发笔试时遇到的)
嵌入式操作系统从组成上可以分为硬件系统和软件系统。硬件系统层由嵌入式微处理器、嵌入式存储器系统、通用设备和I/O接口等组成。软件层由操作系统和应用软件组成。
嵌入式操作系统与通用操作系统的区别:(1)以应用为中心;(2)以计算机技术为基础;(3)软件和硬件可裁剪;(4)对系统性能要求严格;(5)软件的固件化;(6)需要专门的开发工具
上电到程序运行的过程:上电-----基础硬件(CPU,时钟,内存,flash,串口初始化)的自启动,将系统硬件环境调整到一个合适的状态,为启动内核做准备。-----加载操作系统到内核,跳转到系统内核代码运行。
35.volatile关键字
volatile关键字用于修饰易变的变量,防止编译器优化。编译器在编译时,遇到运算的数据已经存在寄存器中,并且没有被修改,编译器就会直接使用在寄存器中的备份,而不用去内存中再取一次,这种操作就叫编译器的优化。被volatile关键字修饰的变量在使用的时候不允许使用在寄存器中的备份,必须去原始地址读取。
volatile的三个例子:(1)并行设备的硬件寄存器,存储器映射的硬件寄存器通常加volatile;(2)一个中断服务程序中修改的供其他程序检测的变量;(3)多线程应用中被几个任务共享的变量
一个变量既可以是const还可以是volatile,例如状态寄存器。一个指针也可以是volatile,例如中断服务子程序中修改一个纸箱buffer的指针。
36.new可以指定初值吗?new的对象离开作用域之后会被析构吗?
(根据网上查到的说法)如果new的是普通的数组,例如:int,char这些基本数据类型,数值是随机的;如果new的是对象数组,会被默认的构造函数初始化成默认值。
new的对象,即使离开了作用域,也会一直存在,必须主动delete,否则会一直到程序结束才会调用析构函数。(内存泄漏)。
37.算术表达式的前缀、中缀、后缀表达式
我们日常生活一般使用的是中缀表达式,但是计算机很难理解中缀表达式,需要转换成前缀或者后缀表达式才能计算。
前缀表达式就是运算符在数字(操作数)的前面。
"x - + 5 6 7 8"运算步骤:将数字按照从右到左的顺序入栈,按照从左到右的顺序遍历运算符,第一个遇到"+",将栈顶的两个数字取出来,与"+"进行运算,栈顶的元素在运算符的前面,次顶的元素在运算符的后面,5+6运算的结果11再入栈,遇到"-",也是将栈顶的两个元素取出来运算,11-7的结果4再次入栈,最后遇到"x",取出两个元素运算,4x8的结果32就是这个前缀表达式的运算结果。
后缀表达式就是运算符在数字(操作数)的后面。从左往右操作。
"1 2 3 + 4 *5 - +"运算步骤:从左往右扫描先碰到+号,取+号前面两个操作数:2,3 得到:2+3.继续往下扫碰到*号,取4 和2+3 得到:(2+3)*4;-号,取(2+3)*4和5得到::(2+3)*4-5;+号:取(2+3)*4-5和1得到:1+(2+3)*4-5
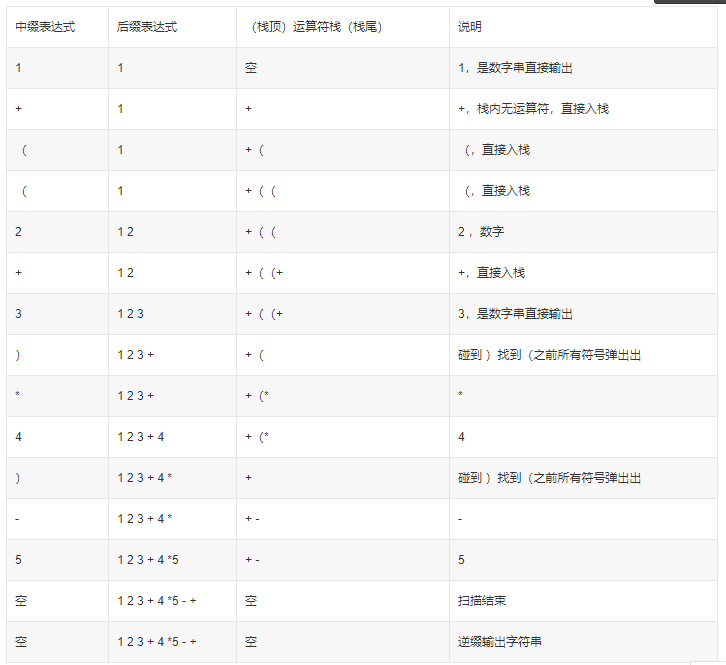
将中缀表达式转换成前缀表达式:(1)创建两个栈,一个存运算符一个存操作数,运算符(以括号为分界)在栈内遵循越往栈顶优先级不降低的原则进行排列;(2)从左到右扫描中缀表达式,从右边的第一个字符开始判断,如果当前字符是数字,则分配到数据串的结尾并将数字串直接输出;如果是运算符,则比较优先级,如果当前运算符的优先级大于栈顶运算符的优先级(当栈顶是括号的时候直接入栈),则将运算符直接入栈;否则将栈顶运算符出栈并输出,知道当前运算符的优先级大于等于栈顶运算符的优先级(如果栈顶是括号,直接入栈),再将当前运算符入栈。如果是括号,则根据括号的方向进行处理,右括号则直接入栈;否则,遇到与括号前将所有的运算符全部出栈并输出,遇到右括号之后将左右的两括号一起删除。(3)重复上述操作,直至扫描结束,将栈内剩余运算符全部出栈并逆序输出字符串,就转换完成了。
例子:1+((2+3)*4)-5

中缀表达式转换成后缀表达式,过程跟前面的差不多,只不过是方向反了,从左往右扫描。
例子:1+((2+3)*4)-5
38.属于同一进程的线程共享哪些资源?
属于同一进程间的线程共享的资源有:(1)堆空间;(2)全局变量,静态变量;(3)文件设备资源;(4)进程的代码段,打开的文件描述符,进程的当前目录
独享的资源有:(1)栈空间;(2)寄存器,程序计数器pc;(3)线程id,线程优先级;(4)错误返回码
39.进程资源死锁的最小值问题
某计算机系统有8台打印机,有k个进程竞争使用,每个进程最多需要3台打印机,该系统可能发生死锁的最小值是(C)
A.2 B.3 C.4 D.5
解答:每个进程3台,不会产生死锁;对于三个进程,可以有两个进程分别获得3台,使其执行完释放后让第三个进程获得3台,所以也不会产生死锁;对于四个进程,假若每个进程各获得2台而同时需要另外一台,产生了死锁,所以产生死锁的最小值是4。
类似题型(1):假设现在有P个进程,每个进程最多需要m个资源,并且有r个资源可用。什么样的条件可以保证死锁不会发生
解:如果一个进程有m个资源它就能够结束,不会使自己陷入死锁中。因此最差情况是每个进程有m-1个资源并且需要另外一个资源。如果留下有一个资源可用,那么其中某个进程就能够结束并释放它的所有资源.使其它进程也能够结束。所以避免死锁的条件是:
r≥p(m-1)+1。
由此条件解上题:r=8,m=3,带入公式得:2p≤7。即当P小于等于3时才可保证死锁不会发生,所以可能会产生死锁的最小值是4。
类似题型(2):某系统中有3个并发进程,都需要同类资源4个,试问该系统不会发生死锁的最少资源数是多少
解:带入上述条件公式:r≥3*(4-1)+1=10。所以答案为10个。.
40.C/C++是不允许函数嵌套定义的,只能嵌套调用。
41.定义管理进程间通信规则的是(A)
A.协议文件 B.数据库文件 C.系统文件 D.通信文件
42.波特率是什么?
波特率表示每秒钟传送的码元符号的个数,是衡量数据传送效率的指标,它用单位时间内载波调制状态改变的次数来表示。
43.struct以及union占用内存大小的计算
结构体在构建的时候,内存对齐。
计算方法:先找出里面元素最大的大小是多少(32位系统最大是4个字节,64位系统最大是8个字节),然后(1)按照顺序来分内存;(2)按照元素最大的大小来进行内存对齐申请;(3)如果剩下的空间不够放下一个元素,那个将开辟新的一层空间,直接跳过这个不够用的一层空间;(4)最后结尾如果还有剩余的内存,也会并入结构体的内存计算中。
共用体
共用体的定义:(1)共用体是一个结构;(2)它的所有成员相对于及地址的偏移量都是0;(3)次结构空间要大到足以容纳最宽的成员;(4)对齐方式要适合所有的成员(我是不怎么读得懂第二句)。
计算共用体的大小:(1)大小足够容纳最宽的成员;(2)大小能被包含的所有基本数据类型的大小整除。
union U { char s[9]; int n; double d; };
这里s占用9个字节,n占用4个字节,d占用8个字节,最大的是s,因此至少需要9个字节的空间,根据对齐方式,9既不能被4整除也不能被8整除,所以要补充到16,最后共用体的内存大小就是16。不用像结构体一样全部加起来,只要大小能被包含的所有基本数据类型的大小整除就行了。
41.ASSERT()断言
#include "assert.h" void assert( int expression );
assert的作用是计算表达式experssion,如果它的值是false,那么就会想stderr打印一条错误信息,然后调用abort来终止程序运行,使用assert的缺点是,频繁调用会极大地影响程序的性能,增加额外的开销,每个assert只检验一个条件。
42.typedef和define的区别
#define SIZE 10 typedef int elemType
(1)语法格式不同;(2)define是一个纯粹的替换,typedef是自定义一个数据类型,并不是替换;(3)命名上,#define一般用一个大写的字符去代表,typedef一般用小写字符_t去代表;(4)typedef能够定义复杂类型,宏定义则不行。
43.设有语句char a =‘72’,则变量a=(A)
A.包含1个字符 B.包含2个字符 C.包含3个字符 D. 说明不合法
解:是一个转义字符,这里的72是8进制的,如果是92就是错误的了,9已经超出8进制的范围了。
44.在WIN32平台下定义,请问p1+5=? ;p2+5=? ;
unsigned char *p1; unsigned int *p2; p1=(unsigned char *)0x801000; p2=(unsigned int *)0x810000;
解:0x801000+5*1=0x801005;p2+5= ; 0x810000+5*sizeof(long)4 = ..+在低字节中最大只能是15即为f=20又放不下,所以向高位进一,即低位16高位为1,那地位就剩4了,等于0x810014;
PS:
44.C++为什么要用模板类?
(1)可用来创建动态增加或减少的数据结构;(2)它与某种特定类型无关,因此代码可重复使用;(3)它在编译时检查数据类型而不是运行时检查数据类型,保证了类型的安全;(4)它是平台无关的,具有很好的移植性。
45.linux的文件权限操作
Linux系统中文件的权限是针对三种对象的,当前用户“u”,用户所属的组“g”,其他用户“o”,针对这三类用户,有r,w,x这三种权限,代表着三种权限的数字分别是4,2,1,chmod 764 file,就是给file这个文件添加rwxrw-r-权限,chmod 777 file就是给file这个文件添加rwxrwxrwx权限。
46.进程间通信、线程间通信
共同点:都能提高程序的并发度,提高程序运行效率和响应时间。
区别:每个进程都有自己的地址空间,线程则是共享地址空间。
线程的优缺点:执行开销小,但不利于资源的管理和保护。
进程的优缺点:执行开销大,但有利于资源的管理和保护。
进程间通信的方式:
(1)管道(pipe):管道是一种半双工的通信方式,数据只能单向流动,并且只能在有亲缘关系的进程间使用。
(2)有名管道(namedpipe):有名管道也是半双工的通信方式,允许无亲缘关系的进程互相通信。
(3)信号量(semophore):信号量是一个计数器,可以用来控制多个进程对资源的访问。通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也来访问该资源。因此,信号箱主要用来作为进程间以及属于同一进程的线程间的同步手段。
(4)消息队列(messagequeue):消息队列是消息的链表,存放在内核中,有消息队列标识符。消息队列客服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
(5)信号(signal):信号用于通知接收进程某个事件已经发生。
(6)共享内存(shared memory):共享内存就是映射一段能被其他进程访问的内存,这段内存由一个进程创建,但是多个进程都可以访问。
(7)套接字(socket):套接字可用于不同设备及其间的进程通信。
线程间通信的方式:
(1)锁机制:互斥锁、条件变量、读写锁
互斥锁提供了排他方式,方式数据结构被并发修改;读写锁允许多个线程同时读取共享数据,但是写入操作却是互斥的;条件变量以阻塞的方式运行,直到某个特定的条件为真的时候,阻塞才会消失,条件变量一般与互斥锁一起使用。
(2)信号量机制(semapore):包括无名线程信号量以及有名线程信号量。
(3)信号机制(signal):类似于进程间的信号处理。
线程间通信主要是用于线程同步,所以线程没有像进程通信那样用于数据交换的机制。
47.堆和栈的区别
在不同的语境之下,堆和栈代表不同的含义,有以下两种:(1)程序内存分布的场景下,堆和栈代表的是两种内存管理方式;(2)在数据结构的场景下,堆和栈代表两种常见的数据结构。
(1)内存分配中的堆和栈
栈空间是系统自动分配的,用于存放函数的参数值,局部变量;堆是程序员手动申请的空间,如果不手动释放空间,则在程序结束的时候,由系统自动回收。堆空间的分配过程:首先,在操作系统中有一个记录空闲地址的链表,当有程序动态申请这片内存空间的时候,就会遍历该链表,寻找第一个空间大于所申请的空间的节点,然后将该节点从链表中删除,并将这块空间分配给程序。另外,大多数程序会在这块内存空间的首地址中记录本次分配的大小,便于delete释放内存空间。
堆和栈的区别:
1.linux系统中的堆和栈空间是两片不同的空间,不能混为一谈。
2.栈空间是系统分配的,系统释放,以函数为单位分配内存,局部变量,形参都在栈空间上。堆空间是用户手动申请的,C语言用malloc/free来申请和释放,C++用new/delete来申请和释放,由于堆空间要手动申请,不然内存会泄露,而栈空间就不会内存泄漏。
3.栈空间的分配和释放速度和效率高,内存是连续的;堆空间的分配和释放效率相对低一些,内存不一定连续,容易产生内存碎片,但是灵活性高。
4.栈是高地址向低地址扩散的连续内存,栈的大小一般是2M或者10M;对是由低地址向高地址扩散的非连续内存,对的大小的影响因素较多,和系统的虚拟内存大小有关系。
(2)数据结构中的堆和栈
栈是一种线性表,不过只允许在一段插入和删除,这一段称为栈顶,另一端称为栈底,栈具有先进后出的特性。
堆是一种树形结构,是一个完全二叉树,满足所有的节点的值总是不大于或者小于它的双亲节点的值,即,在一个堆中,根节点是最大(大根堆)或者最小节点(小根堆)。
48.拷贝函数 memcpy、sprintf、strcpy
memcpy: void *memcpy(void *dest, const void *src, size_t n);
memcpy是memory copy的缩写,即内存复制,功能是从src的开始内存位置开始拷贝n个字节的数据到dest,如果dest存在数据,就被覆盖,memcpy返回的是dest的指针,memocpy函数定义在string.h头文件里面。
char name[]="cout"; char myname[32]=NULL; memcpy(myname,name,strlen(name)+1);
memcpy的底层实现
void *my_memcpy(void* dest,void* src,size_t n) { void *p=dest; while(n--){ *(char*)dest=*(char*)src; dest=(char*)dest+1; src=(char*)src+1; } return p; }
sprintf: int sprintf(char *str, const char *format, ...) 发送格式化数据到str所指向的字符串,函数的返回值是str所指向的字符串的长度。
作用:(1)格式化字符串;(2)连接字符串;
strcpy: char *strcpy(char *dest,const *src);
功能:把后面的src字符串的内容拷贝到dest字符串当中,拷贝结束是以遇到"�"才停下。strcpy的底层实现:
char *strcpy(char *s1,char *s2) { char *tmp=s1; while(*s1++=*s2++); return tmp; }
49.linux系统下的.ko文件,.so文件分别是什么文件?
.ko文件是内核模块文件,内核加载的某个模块,一般是驱动程序,.so文件是动态链接库文件,相当于windows下的.dll文件。
50.编程实现二叉树先序遍历。
#include <stdio.h> #include <stdlib.h> typedef struct BTree{ char data; struct BTree *lchild; struct BTree *rchild; }BiTree; //先序创建树 BiTree *create_tree(){ char ch='�'; scanf("%c",&ch); if(ch=='#'){ return NULL; }else{ BiTree *root=malloc(sizeof(BiTree)); root->data=ch; root->lchild=create_tree(); root->rchild=create_tree(); return root; } } //三种遍历都是不停地递归,直到一边遍历完了,再遍历另一边 //前序遍历 void show_tree(BiTree *root){ if(root==NULL)return; printf("%c",root->data); show_tree(root->lchild); show_tree(root->rchild); } //中序遍历 void show_mid(BiTree *root){ if(root==NULL)return; show_mid(root->lchild); printf("%c",root->data); show_mid(root->rchild); } //后续遍历 void show_tail(BiTree *root){ if(root==NULL)retrun; show_tail(root->lchild); show_tail(root->rchild); printf("%c",root->data); } //销毁二叉树 void destroy_tree(BiTree *root){ //后续遍历销毁 if(root==NULL)return; destroy_tree(root->lchild); destroy_tree(root->rchild); free(root); root=NULL; } int main() { BiTree *root=create_tree(); show_tree(root); show_mid(root); show_tail(root); return 0; }
51.链表反转
struct ListNode* reverse_List(struct ListNode *head){ //双指针法 if(head==NULL||head->next==NULL)return NULL; struct ListNode *p=NULL,*q=head,*tmp=NULL; while(q!==NULL){ tmp=q->next; q->next=p; p=q; q=tmp; } retrun p; }
TCP/UDP和三次握手/四次挥手摘自:https://www.jianshu.com/p/16742fbc1b29
进程线程的部分内容摘自:https://blog.csdn.net/qq_40340448/article/details/81836065
select、poll、epoll部分摘自:https://blog.csdn.net/BaiHuaXiu123/article/details/89948037
SQL部分摘自:https://blog.csdn.net/yinni11/article/details/79859659
字符串拷贝函数的底层实现部分摘自:https://www.cnblogs.com/OctoptusLian/p/9082296.html
35volatile关键字的例子摘自:https://www.cnblogs.com/smile-at-you/archive/2013/10/08/3357910.html
37算数表达式的前中后缀部分摘自:https://blog.csdn.net/linsheng9731/article/details/23125353
38线程资源贡献的部分摘自:https://blog.csdn.net/zengzhihao/article/details/80999562
39进程资源死锁问题摘自:https://wenku.baidu.com/view/f64570dfba4cf7ec4afe04a1b0717fd5360cb2c3.html
40.union部分摘自:https://www.cnblogs.com/weiyouqing/p/9685427.html
44模板类部分摘自:https://blog.csdn.net/weixin_41066529/article/details/90215972
46进程线程通信部分摘自:https://blog.csdn.net/liyue98/article/details/80112246
47栈和堆的区别部分摘自:https://blog.csdn.net/PinkBananA_/article/details/91399849