引言
Dictionary在C#中算是比较常用的数据结构了,它的读取速度很快,效率很高。以前没有怎么看它的源码实现,前几天看了看它的源码实现,还是有点意思的,下面我将逐步说下它的实现原理。
数据结构
它是通过Hash Bucket和链表形成的数据结构,将一份数据分为多个链表,且每个链表都对应它的Bucket。可以看以下的图:
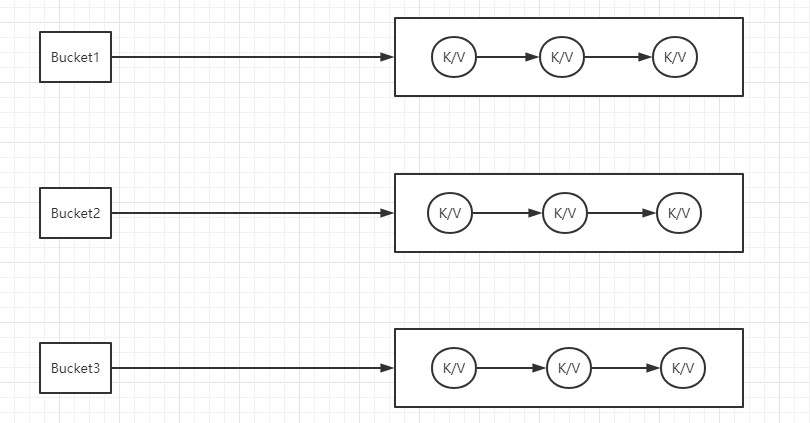
看不明白不要急,我们先看源码Dictionary类里面定义的字段都有什么。
private struct Entry {
public int hashCode; // 每个K/V对应的Hash值
public int next; // 指向下一个K/V的index,-1代表最后一个
public TKey key; // key的值
public TValue value; // Value的值
}
private int[] buckets; //定义桶的数组
private Entry[] entries; //定义元素的数组
private int count; //元素总数量
private int version; //版本
private int freeList; //被移除后,空闲元素的下标
private int freeCount; //空闲元素的数量
有了上面字段的定义,接下来我分分析它是怎么添加元素,寻找元素和删除元素的。
添加元素
首先我们先把主要的源码贴出来,从源码上分析主要实现。
private void Insert(TKey key, TValue value, bool add) {
if( key == null ) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize(0); //初始化上面的那些字段
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length; //获取对应的目标Bucket
//寻找是否有相同key的元素
for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (add) {
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
}
int index;
if (freeCount > 0) { //判断现在是否有空闲的元素,优先使用空闲的元素
index = freeList;
freeList = entries[index].next;
freeCount--;
}
else {
if (count == entries.Length) //判断是否存储的项和Entries的长度,相等的话,就重新扩容。
{
Resize();// 扩容Buctet和Entries的大小
targetBucket = hashCode % buckets.Length;
}
index = count;
count++;
}
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
}
源码详细讲解。
- 初次添加元素时,如果构造函数中不传入大小,默认会自动取一个最小的质数(即:3)来作为桶的大小和元素集合的大小,并且初始换里面的字段变量。
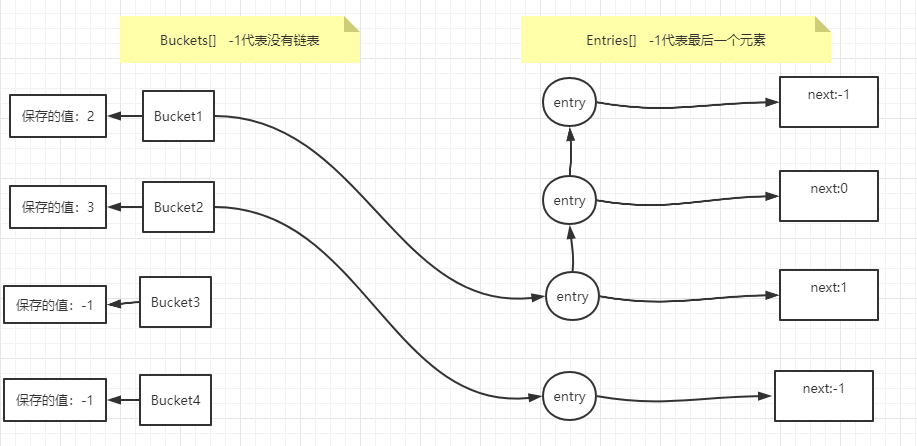
- 在寻找元素插入的位置的时候,首先通过元素的hashcode % bucket的长度优先得到要插入的目标的Bucket是哪个,然后将元素的hashCode和next赋值。
- 这里next赋值的话详细说一下。首先,我们先分析buckets,它里面的每个bucket保存的是对应链表最后一个元素的下标,可以通过最后一行代码得知,每次给元素赋值之后,当前元素的下标,会赋值给对应的bucket。
而每个新插入元素,只需要当前bucket里面的值赋值给它当前的next指向的index就可以了。
图示
查找元素
我们还是先简单看一下主要实现部分的源码。
private int FindEntry(TKey key) {
if( key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; //首先获取key的hashCode
//寻址的第一个元素就是对应目标桶里面记录的index,然后通过对应元素的next指向下一个元素,当next为-1时,就是代表已经到最后一个元素了。
for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) {
//判断元素的hashcode和key是否都相等。
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i;
}
}
return -1;
}
源码详细讲解。
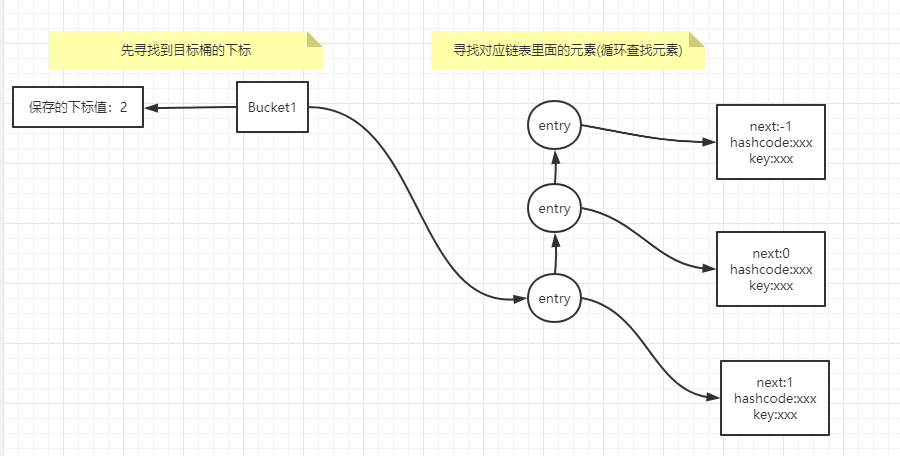
- 其实这里代码已经写的很清楚了,它是先找到目标桶,因为目标桶里面记录的是它对应链表的最后一个元素的下标,然后顺着元素的next找,直到找到这个元素为止。
- 可以仔细想想,这样的话,每次查找就可以过滤一大批的数据,所以查的速度就更快了,但是当数据量大的时候,也是会有效率问题。
图示
移除元素
还是先简单看下源代码主要实现的部分。
public bool Remove(TKey key) {
if(key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int bucket = hashCode % buckets.Length;
int last = -1; //这个变量主要是记录上一个元素的下标。
//和上面一样,先查找要删除的元素。
for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
if (last < 0) { //代表第一个元素就是要找的元素
buckets[bucket] = entries[i].next; //把buctet指向的下标,指向下一个元素
}
else {
entries[last].next = entries[i].next; //将上一个元素的下标,指向下一个元素的下标,去掉被删除的元素。
}
entries[i].hashCode = -1;
entries[i].next = freeList; //当前元素指向上一个空闲元素的下标
entries[i].key = default(TKey);
entries[i].value = default(TValue);
freeList = i; //记录最后一个被移除元素的下标
freeCount++; //每次移除,空闲的元素+1
version++;
return true;
}
}
}
return false;
}
源码详细讲解。
- 查找对应的元素和上面的逻辑其实是一样的,它这里定义了一个变量,用来记录上一个元素的下标。
- 当找到对应的元素时,把上个元素的next指向当前被移除元素的next,即把当前被移除的元素跳过去。
- 然后将被移除元素的字段初始化,需要注意的是这个next的值,它用的是freelist,记录最后一个被移除元素的index,每移除一个元素,被移除的元素数量就+1,即freecount。
被移除的元素也会形成一个链表,它的next首部元素next指向-1,后边被移除的元素next指向上一个被移除元素的index。 - 回过头再去看添加的时候,它会判断,freeCount的数量是否是大于0的,如果大于0的话,优先使用被移除元素的位置并填充它们,它的index就是freeList,然后再把当前元素的next赋值给
freelist(即下次再插入元素的时候,就是上一个被移除元素的下标)。 - 最后在下面给当前元素赋值的时候,它的next又指向当前bucket里面的值,即作为对应链表的尾部。
图示

关于扩容
先简单看下主要实现部分的源码。
private void Resize(int newSize, bool forceNewHashCodes) {
Contract.Assert(newSize >= entries.Length); // 这个newSize是获取大于count的最小质数
int[] newBuckets = new int[newSize];
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1; //初始化每个bucket的值
Entry[] newEntries = new Entry[newSize];
Array.Copy(entries, 0, newEntries, 0, count); //将原来的entries的值copy到新的entries里面
for (int i = 0; i < count; i++) {
if (newEntries[i].hashCode >= 0) { //判断hashcode代表是有效的entry
int bucket = newEntries[i].hashCode % newSize;
newEntries[i].next = newBuckets[bucket];
newBuckets[bucket] = i; //上面的操作就是重新找新的桶,然后重新给entey的next赋值。
}
}
buckets = newBuckets;
entries = newEntries;
}
源码详细讲解
- 这里的newSize会在里面的元素数达到entries的长度是扩容,它是在一个helper类里面进行取值,它是拿大于它的最小质数。
- 这个新的size就是buckets的长度和entries的长度,先把原来的entries的值copy到新的entries里面。
- 然后循环新的的entries,重新定义新的桶的值并且给原来的数据,重新形成新的链表。
总结
关于dictionary的解析也是我一个简单的理解吧,主要还是看源码能了解的更多,希望能够帮助到需要的人。
微软源码的地址可以看这个: https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,bba8e22685381014