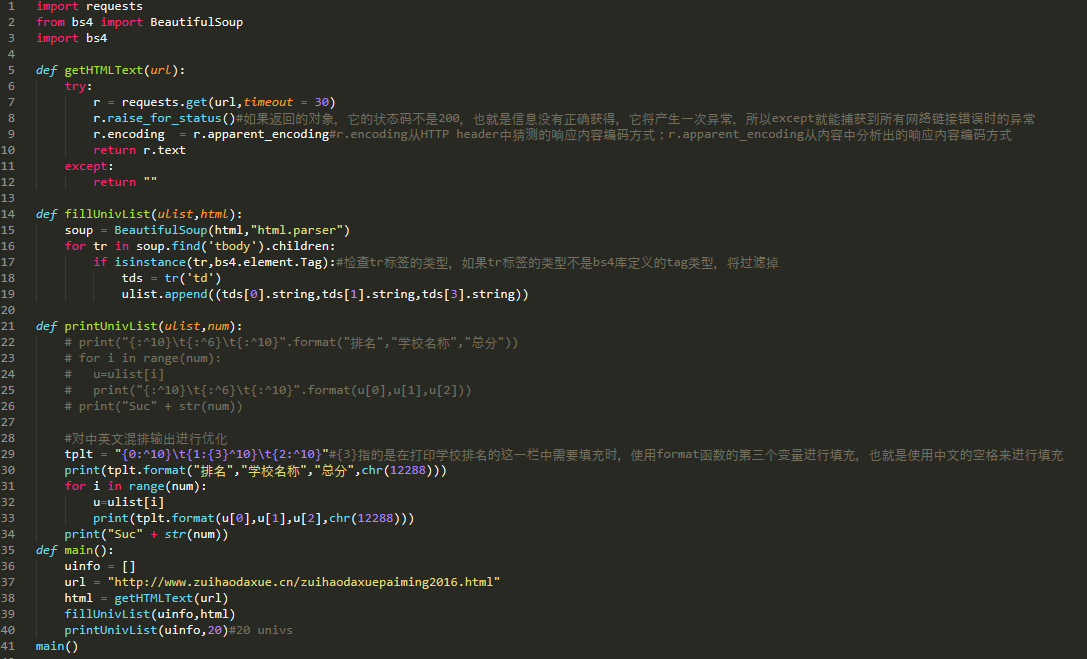
实例1:中国大学排名定向爬虫
功能描述
输入:大学排名URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests-bs4
定向爬虫:仅对输入URL进行爬取,不扩展爬取
程序的结构设计
步骤1:从网络上获取大学排名网页内容getHTMLText()
步骤2:提取网页内容中信息到合适的数据结构fillUnivList()
步骤3:利用数据结构展示并输出结果printUnivList()
大学排名除了排名之外还包括大学的基本信息,是一个典型的二维数据结构,所以采用二维列表组织相关信息

import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#检查tr标签的类型,如果tr标签的类型不是bs4库定义的tag类型,将过滤掉
tds = tr('td')
ulist.append((tds[0].string,tds[1].string,tds[3].string))
def printUnivList(ulist,num):
# print("{:^10} {:^6} {:^10}".format("排名","学校名称","总分"))
# for i in range(num):
# u=ulist[i]
# print("{:^10} {:^6} {:^10}".format(u[0],u[1],u[2]))
# print("Suc" + str(num))
#对中英文混排输出进行优化
tplt = "{0:^10} {1:{3}^10} {2:^10}"#{3}指的是在打印学校排名的这一栏中需要填充时,使用format函数的第三个变量进行填充,也就是使用中文的空格来进行填充
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
print("Suc" + str(num))
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)#20 univs
main()
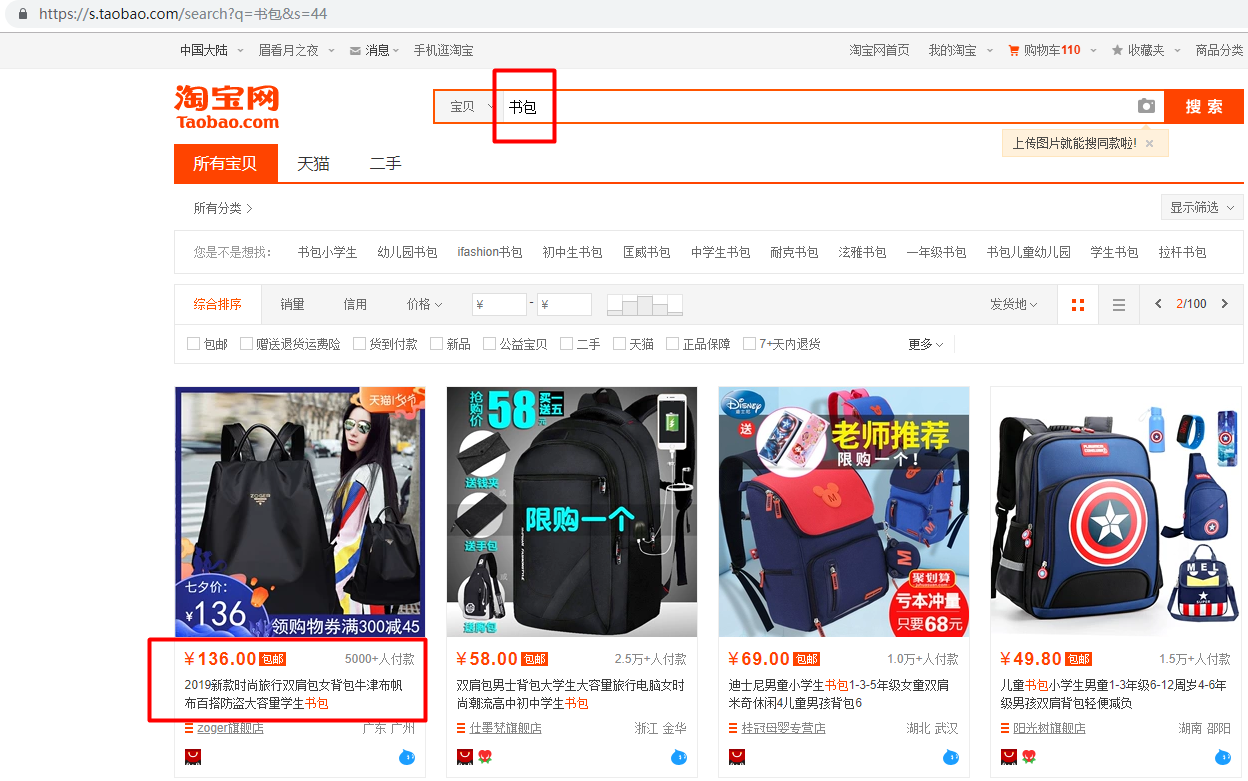
实例2:淘宝商品信息定向爬虫
功能描述
目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格
理解:淘宝的搜索接口
翻页的处理
技术路线:requests-re
定向爬虫可行性
程序的结构设计
步骤1:提交商品搜索请求,循环获取页面
步骤2:对于每个页面,提取商品名称和价格信息
步骤3:将信息输出到屏幕上


import requests
import re
def getHTMLTest(url):
try:#coo的值为自己登录淘宝后,输入书包搜索后的cookie
coo = 'thw=cn; cna=24t1FdsskikCAXEteKSVn8yS; v=0; t=6615fa5b788406278f02379f51d55807;
cookie2=55a650e680a8e140771936b04cb56e95; _tb_token_=f68134b3ee336; unb=763489836;
uc3=nk2=oAY%2Bx%2FHWV8vidQ%3D%3D&id2=VAcN5rR6zAjv&vt3=F8dBy32junLF5eJpjDs%3D&lg2=VT5L2FSpMGV7TQ%3D%3D;
csg=8ec2be45; lgc=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; cookie17=VAcN5rR6zAjv;
dnk=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; skt=e8b0543f48622a97; existShop=MTU2NDkwODMzOQ%3D%3D;
uc4=id4=0%40Vh5PI3jEh3Oc2p0oDeG%2Fvw4ylAo%3D&nk4=0%40olT0l5EQsQIZXSm9RQUe%2FzVpfGL%2F;
tracknick=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; _cc_=VT5L2FSpdA%3D%3D; tg=0; _l_g_=Ug%3D%3D;
sg=%E5%A4%9C6f; _nk_=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C;
cookie1=Vv6fkO6X3Dbd0%2BjR5Pm9%2FVMegu88LAEuGgMSjoFaFFg%3D;
enc=aBauooIlET%2FTz%2FO%2By206HZzzoZUzq%2BmM220DoSa8xXJAwE9%2FtIJe5hfuwu12e9GfpcG%2F9ZNzpm6JBo%2F2D%2BNsig%3D%3D;
mt=ci=110_1; hng=CN%7Czh-CN%7CCNY%7C156; swfstore=308335;
x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0;
uc1=cookie14=UoTaHPGk7cSIQw%3D%3D&cookie15=V32FPkk%2Fw0dUvg%3D%3D;
whl=-1%260%260%261564908848429; JSESSIONID=9A789A993ECB09BAABEF6E4A29CC2510;
l=cBgxe_J4qUKhmO7bBOCg5uI8LO7OSIRA_uPRwCVXi_5Ba6Ls0d_Ok7JG-Fp6VjWd90TB4dG4psy9-etkiKy06Pt-g3fP.;
isg=BFtbb-bCgqTERv7QpzRjXQhf6r8FmG5bzZ8Il02YN9pxLHsO1QD_gnmuxswHC8cq'
r = requests.get(url,headers={'cookie':coo},timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt,html):
try:
plt = re.findall(r'"view_price":"[d.]*"',html)
tlt = re.findall(r'"raw_title":".*?"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])#eval函数可以将获得的字符串的最外层的单引号或者双引号去掉
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4} {:8} {:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLTest(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
import requests import re def getHTMLTest(url): headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'} try:#coo的值为自己登录淘宝后,输入书包搜索后的cookie coo = 'thw=cn; cna=24t1FdsskikCAXEteKSVn8yS; v=0; t=6615fa5b788406278f02379f51d55807; cookie2=55a650e680a8e140771936b04cb56e95; _tb_token_=f68134b3ee336; unb=763489836; uc3=nk2=oAY%2Bx%2FHWV8vidQ%3D%3D&id2=VAcN5rR6zAjv&vt3=F8dBy32junLF5eJpjDs%3D&lg2=VT5L2FSpMGV7TQ%3D%3D; csg=8ec2be45; lgc=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; cookie17=VAcN5rR6zAjv; dnk=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; skt=e8b0543f48622a97; existShop=MTU2NDkwODMzOQ%3D%3D; uc4=id4=0%40Vh5PI3jEh3Oc2p0oDeG%2Fvw4ylAo%3D&nk4=0%40olT0l5EQsQIZXSm9RQUe%2FzVpfGL%2F; tracknick=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; _cc_=VT5L2FSpdA%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=%E5%A4%9C6f; _nk_=%5Cu7709%5Cu770B%5Cu6708%5Cu4E4B%5Cu591C; cookie1=Vv6fkO6X3Dbd0%2BjR5Pm9%2FVMegu88LAEuGgMSjoFaFFg%3D; enc=aBauooIlET%2FTz%2FO%2By206HZzzoZUzq%2BmM220DoSa8xXJAwE9%2FtIJe5hfuwu12e9GfpcG%2F9ZNzpm6JBo%2F2D%2BNsig%3D%3D; mt=ci=110_1; hng=CN%7Czh-CN%7CCNY%7C156; swfstore=308335; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; uc1=cookie14=UoTaHPGk7cSIQw%3D%3D&cookie15=V32FPkk%2Fw0dUvg%3D%3D; whl=-1%260%260%261564908848429; JSESSIONID=9A789A993ECB09BAABEF6E4A29CC2510; l=cBgxe_J4qUKhmO7bBOCg5uI8LO7OSIRA_uPRwCVXi_5Ba6Ls0d_Ok7JG-Fp6VjWd90TB4dG4psy9-etkiKy06Pt-g3fP.; isg=BFtbb-bCgqTERv7QpzRjXQhf6r8FmG5bzZ8Il02YN9pxLHsO1QD_gnmuxswHC8cq' cookies = {} for line in coo.split(';'):#浏览器伪装 name,value = line.strip().split('=',1) cookies[name] = value r = requests.get(url,cookies = cookies,headers = headers,timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt,html): try: plt = re.findall(r'"view_price":"[d.]*"',html) tlt = re.findall(r'"raw_title":".*?"',html) for i in range(len(plt)): price = eval(plt[i].split(':')[1])#eval函数可以将获得的字符串的最外层的单引号或者双引号去掉 title = eval(tlt[i].split(':')[1]) ilt.append([price,title]) except: print("") def printGoodsList(ilt): tplt = "{:4} {:8} {:16}" print(tplt.format("序号","价格","商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count,g[0],g[1])) def main(): goods = '书包' depth = 2 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44*i) html = getHTMLTest(url) parsePage(infoList,html) except: continue printGoodsList(infoList) main()
实例3:股票数据定向爬虫
功能描述
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:requests-bs4-re
候选数据网站的选择
新浪股票:https://finance.sina.com.cn/stock/
百度股票:https://gupiao.baidu.com/stock
选取原则:股票信息静态存在于HTML页面中,非js代码生成,没有Robots协议限制。
选取方法:浏览器F12,源代码查看等。
选取心态:不要纠结于某个网站,多找信息源尝试。
程序的结构设计
步骤1:从东方财富网获取股票列表
步骤2:根据股票列表逐个到百度股票获取个股信息
步骤3:将结果存储到文件
import requests from bs4 import BeautifulSoup import re import traceback #获得url对应的页面 def getHTMLText(url,code = 'utf-8'): try: r = requests.get(url,timeout = 30) r.raise_for_status() #r.encoding = r.apparent_encoding#编码识别的优化,手工的方式先获得编码的类型(apparent_encoding),然后直接赋给encoding r.encoding = code return r.text except: return "" #获得股票的信息列表 def getStockList(lst,stockURL): html = getHTMLText(stockURL,'GB2312') soup = BeautifulSoup(html,'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]d{6}",href)[0]) except: continue #获得每一支个股的股票信息,并且把他存到某一个数据结构 def getStockInfo(lst,stockURL,fpath): count = 0 for stock in lst: url = stockURL +stock + ".html" html = getHTMLText(url) try: if html == "": continue infoDict = {} soup = BeautifulSoup(html,'html.parser') stockInfo = soup.find('div',attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'股票名称':name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath,'a',encoding='utf-8') as f: f.write(str(infoDict) + ' ') count = count + 1 print(" 当前进度:{:.2f}%".format(count*100/len(lst)),end=' ')#增加动态的进度显示, # 能够将我们打印的字符串的最后的光标提到当前这一行的头部,下一次再进行相关打印的时候, #打印的信息就会覆盖之前打印的内容,这样实现了一个不换行的、动态变化的信息展示 except: count = count + 1 print(" 当前进度:{:.2f}%".format(count*100/len(lst)),end=' ') traceback.print_exc() continue def main(): stock_list_url = 'http://quote.eastmoney.com/stock_list.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D://BaiduStockInfo.txt' slist = [] getStockList(slist,stock_list_url) getStockInfo(slist,stock_info_url,output_file) main()
>>> r = requests.get('http://quote.eastmoney.com/stock_list.html',timeout = 30)
>>> r.apparent_encoding
'GB2312'
>>> r = requests.get('https://gupiao.baidu.com/stock/',timeout = 30)
>>> r.apparent_encoding
'utf-8'