1.环境搭建
基础环境配置 jdk+idea+maven+scala2.11。以上工具安装配置此处不再赘述。
2.源码导入
官网下载spark源码后解压到合适的项目目录下,打开idea,File->open 找到源码文件夹,选中spark-parent的pom文件,确定-> open as a project。接下来就是漫长的依赖解析过程。
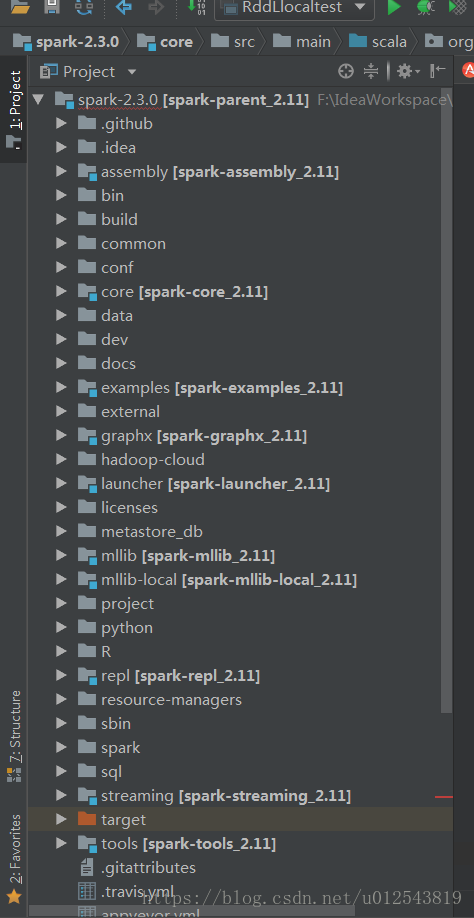
3.依赖解析完成后,得到一个漂亮的spark项目
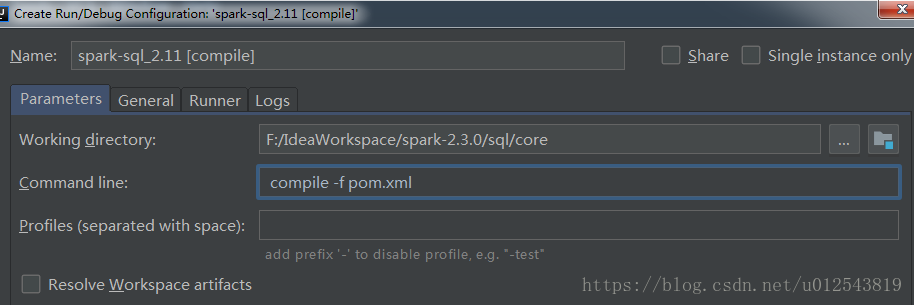
4. 尝试编译。最近需要用到spark-sql相关的东西,我们先尝试编译一下spark-sql,在idea右侧工具栏中找到maven project,找到对应的模块,点击展开lifecycle。

我们在想要的lifecycle上右击,选择create XXX,此处我选择的是compile,然后会进入到参数编辑的界面,可以对mvn的参数进行设置。这里我暂时使用默认设置。
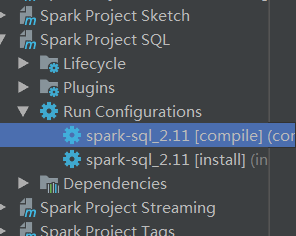
完成后就会发现run configuration 下面多了一选项,我们可以双击执行或者右键进行编辑。
我们运行一下。最后得到如下输出,则编译成功
[info] Compile success at 2018-8-7 11:01:04 [4:35.895s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:56 min
[INFO] Finished at: 2018-08-07T11:01:04+08:00
[INFO] ------------------------------------------------------------------------
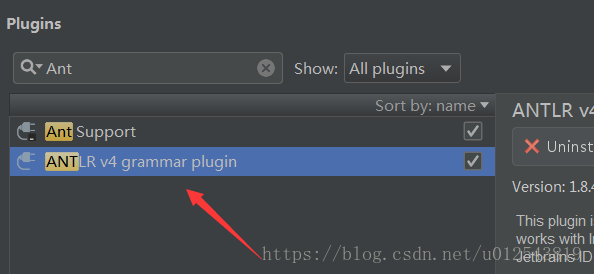
spark sql 有一个基础的sql语法规则定义文件,sqlBase.g4,如果要方便的查看sql语法解析树,需要一个插件ANTLR V4
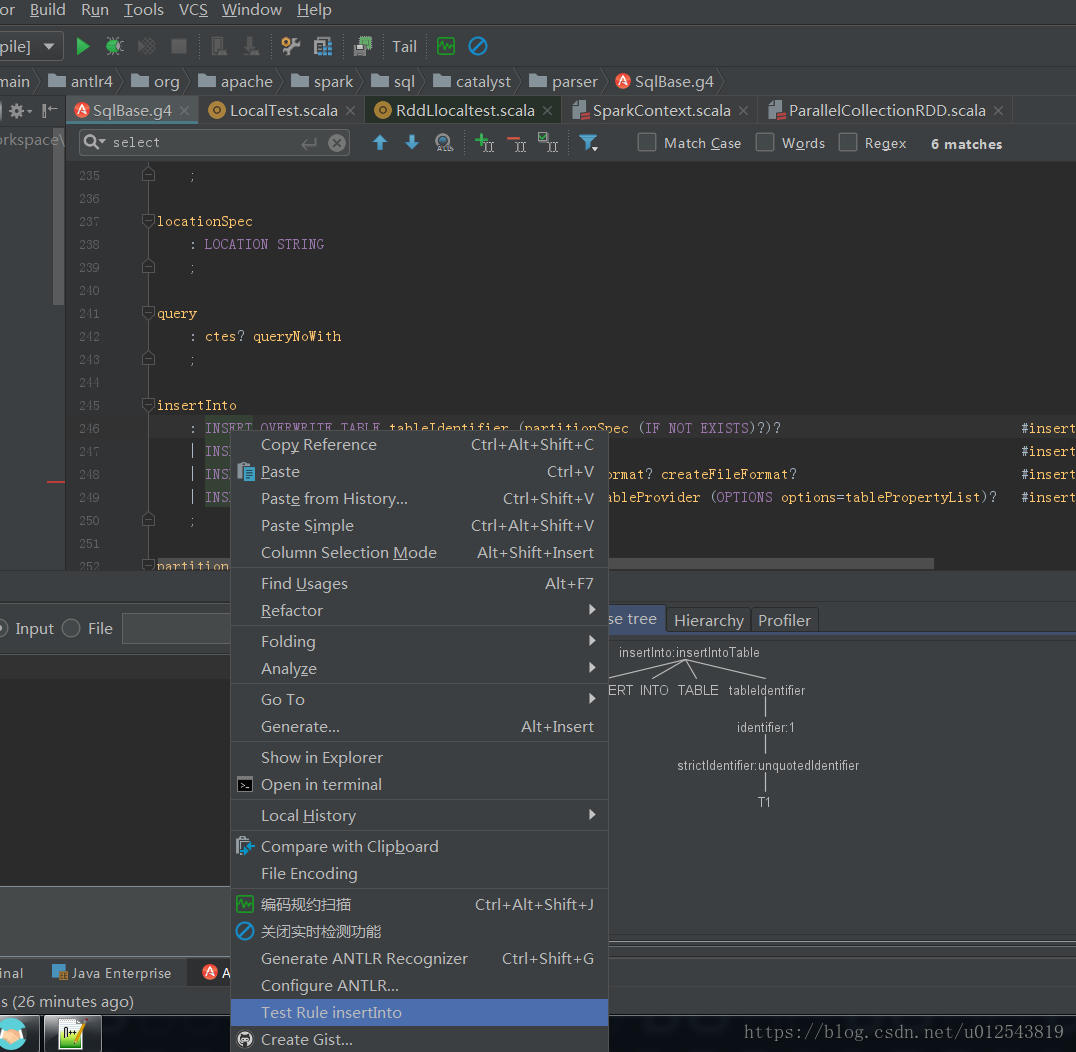
我们找到sqlBase文件,在某个语法上右键,选择Test Rule XXX,即可查看某个语法的解析树
关于环境搭建的基本暂时就到这里吧。
---------------------
作者:彼岸枫雪非
来源:CSDN
原文:https://blog.csdn.net/u012543819/article/details/81455353
版权声明:本文为博主原创文章,转载请附上博文链接!