一:基础数据准备
DROP TABLE IF EXISTS `tbl_user`; CREATE TABLE `tbl_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `email` varchar(20) DEFAULT NULL, `age` tinyint(4) DEFAULT NULL, `type` int(11) DEFAULT NULL, `create_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8; INSERT INTO `tbl_user` VALUES ('1', 'admin', 'admin@126.com', '18', '1', '2018-07-09 11:08:57'), ('2', 'mengday', 'mengday@163.com', '31', '2', '2018-07-09 11:09:00'), ('3', 'mengdee', 'mengdee@163.com', '20', '2', '2018-07-09 11:09:04'), ('4', 'root', 'root@163.com', '31', '1', '2018-07-09 14:36:19'), ('5', 'zhangsan', 'zhangsan@126.com', '20', '1', '2018-07-09 14:37:28'), ('6', 'lisi', 'lisi@gmail.com', '20', '1', '2018-07-09 14:37:31'), ('7', 'wangwu', 'wangwu@163.com', '18', '1', '2018-07-09 14:37:34'), ('8', 'zhaoliu', 'zhaoliu@163.com', '22', '1', '2018-07-11 18:29:24'), ('9', 'fengqi', 'fengqi@163.com', '19', '1', '2018-07-11 18:29:32'); DROP TABLE IF EXISTS `tbl_userinfo`; CREATE TABLE `tbl_userinfo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `address` varchar(255) DEFAULT NULL, `user_id` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `idx_userId` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8; INSERT INTO `tbl_userinfo` VALUES ('1', '上海市', '1'), ('2', '北京市', '2'), ('3', '杭州', '3'), ('4', '深圳', '4'), ('5', '广州', '5'), ('6', '海南', '6');
二:五百万数据插入
上面插入几条测试数据,在使用索引时还需要插入更多的数据作为测试数据,下面就通过存储过程插入500W条数据作为测试数据
-- 修改mysql默认的结束符号,默认是分号;但是在函数和存储过程中会使用到分号导致解析不正确 DELIMITER $$ -- 随机生成一个指定长度的字符串 CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) BEGIN # 定义三个变量 DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = CONCAT(return_str, SUBSTRING(chars_str, FLOOR(1+RAND()*52), 1)); SET i = i + 1; END WHILE; RETURN return_str; END $$ -- 创建插入的存储过程 CREATE PROCEDURE insert_user(IN START INT(10), IN max_num INT(10)) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO tbl_user VALUES ((START+i) ,rand_string(8), CONCAT(rand_string(6), '@random.com'), 1+FLOOR(RAND()*100), 3, NOW()); UNTIL i = max_num END REPEAT; COMMIT; END $$ -- 将命令结束符修改回来 DELIMITER ; -- 调用存储过程,插入500万数据,需要等待一会时间,等待执行完成 CALL insert_user(100001,5000000); -- Query OK, 0 rows affected (7 min 49.89 sec) SELECT COUNT(*) FROM tbl_user;
三:使用索引和不使用索引的比较
使用索引之前的查询
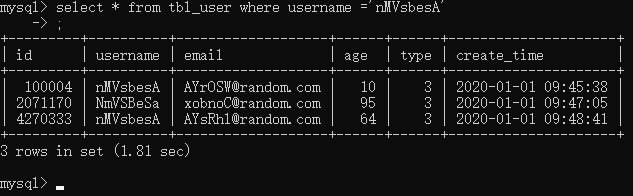
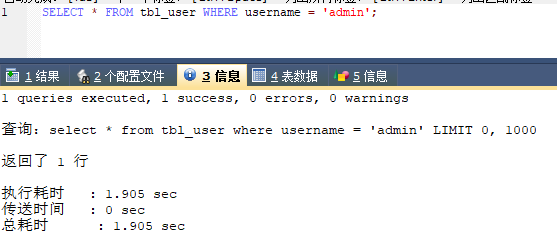
然后给username创建索引再次查询(数据库卡死了,我用sqlyog做)
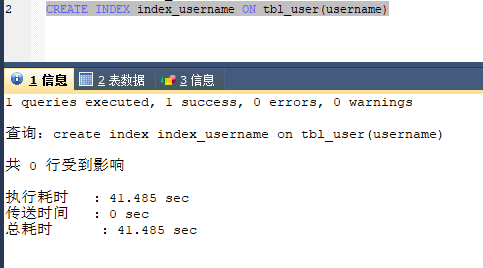
创建索引用了40秒,属实有点慢
然后再查询试试,基本是秒查了,效率提升很明显
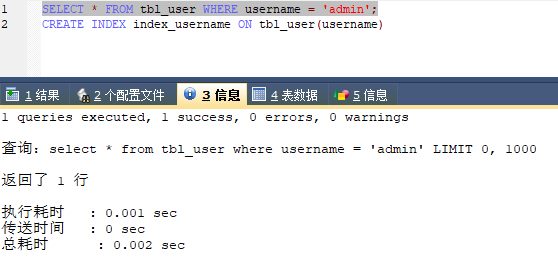
之前再黑窗口加的索引也上去了

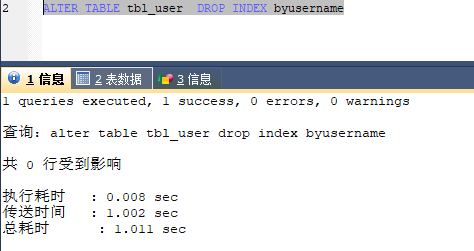
然后删除一个索引,byusername
四:explain命令

explain参数详解



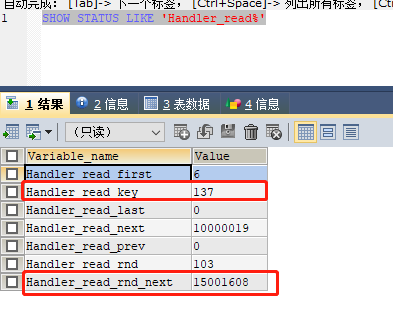
查看索引的使用情况:show status like 'Handler_read%'
Handler_read_key: 越高越好
Handler_read_rnd_next:越低越好
查询优化器:
- 重新定义表的关联顺序(优化器会根据统计信息来决定表的关联顺序)
- 将外连接转化成内连接(当外连接等于内连接)
- 使用等价变换规则(如去掉1=1)
- 优化count()、min()、max()
- 子查询优化
- 提前终止查询
- in条件优化
mysql可以通过 EXPLAIN EXTENDED 和 SHOW WARNINGS 来查看mysql优化器改写后的sql语句
下图提示我们别用*查询,应该写具体那一列

五:走索引的情况和不走索引的情况
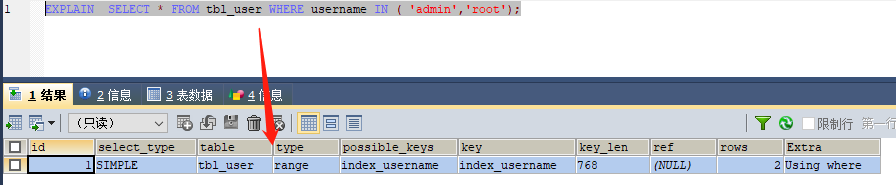
1. in走索引
in操作能避免则避免,若实在避免不了,需要仔细评估in后边的集合元素数量,控制在1000个之内。
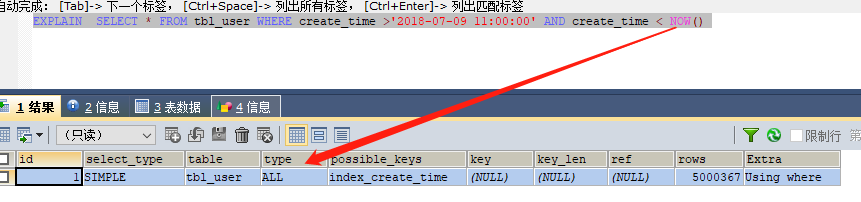
2. 范围查询走索引
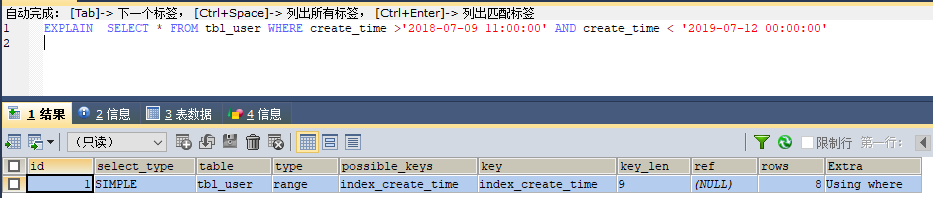
但是条件必须是一个具体的值,如果条件为 now() 当前时间,则会导致全表扫描
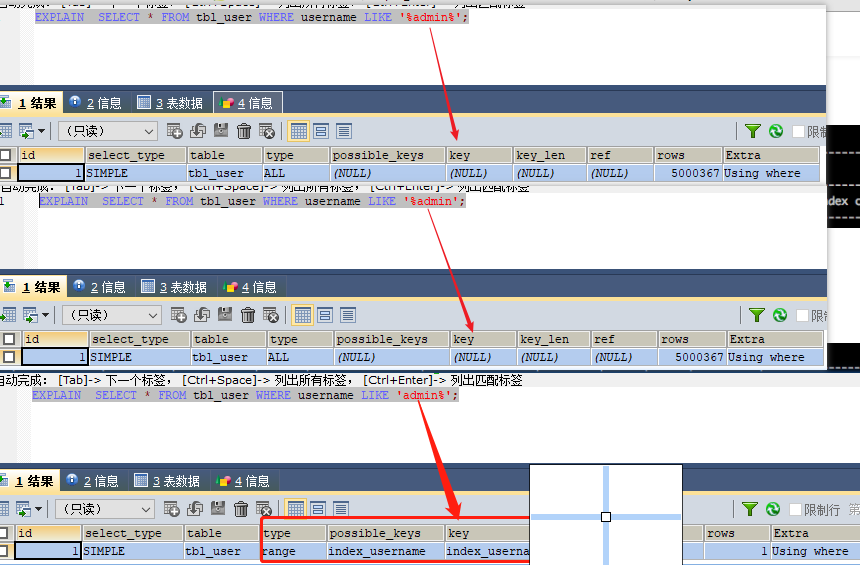
3. 模糊查询只有左前缀使用索引
4. 反向条件不走索引 != 、 <> 、 NOT IN、IS NOT NULL

一个优化的实例:
# 常见的对not in的优化,使用左连接加上is null的条件过滤 SELECT id, username, age FROM tbl_user WHERE id NOT IN (SELECT user_id FROM tbl_order); SELECT u.id, u.username, u.age FROM tbl_user u LEFT JOIN tbl_order o ON u.id = o.user_id WHERE o.user_id IS NULL;
5. 对条件计算(使用函数或者算数表达式)不走索引
使用函数计算不走索引,无论是对字段使用了函数还是值使用了函数都不走索引,解决办法通过应用程序计算好,将计算的结果传递给sql,而不是让数据库去计算



6. 查询时必须使用正确的数据类型
如果索引字段是字符串类型,那么查询条件的值必须使用引号,否则不走索引

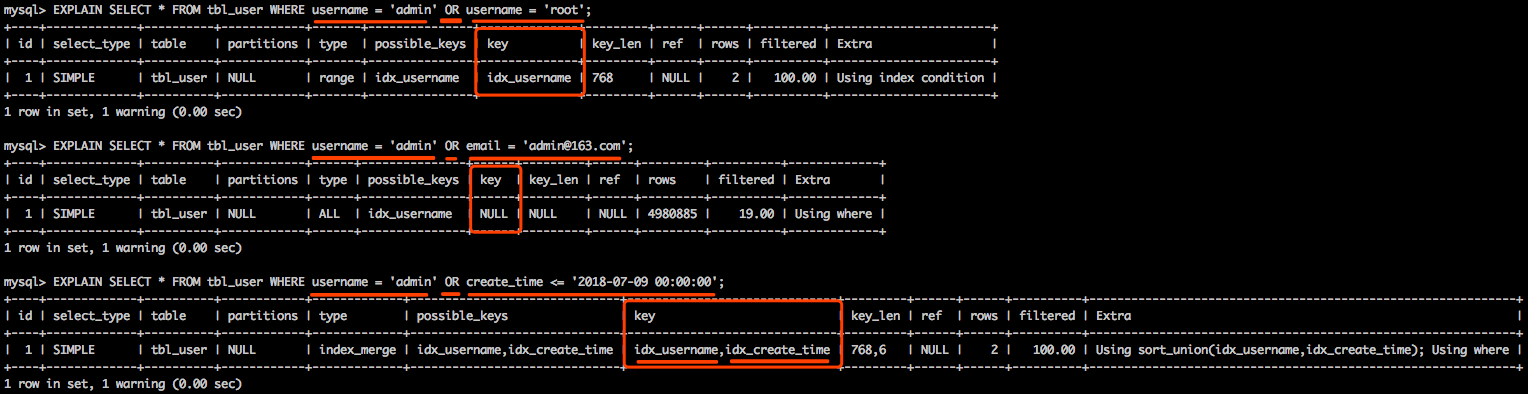
7. or 使用索引和不使用索引的情况
or 只有两边都有索引才走索引,如果都没有或者只有一个是不走索引的
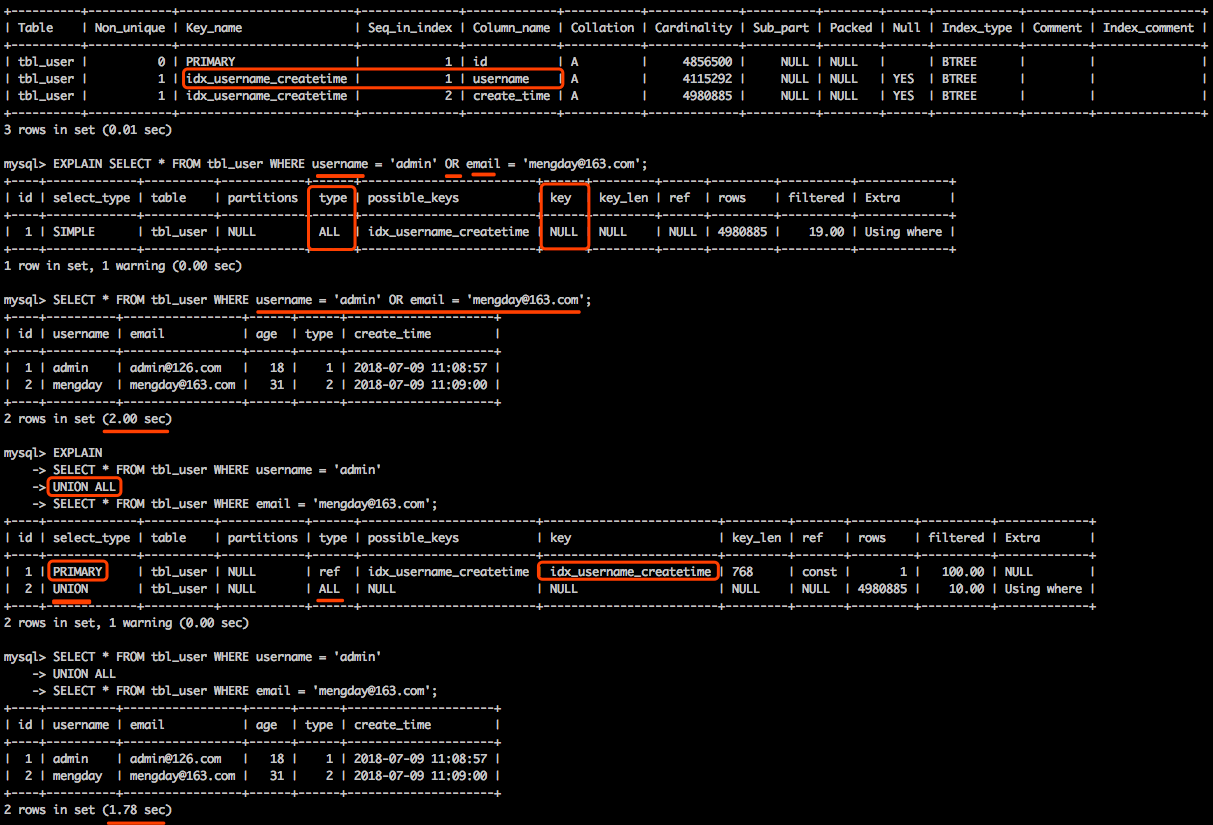
8. 用union少用or
尽量避免使用or,因为大部分or连接的两个条件同时都进行索引的情况几率比较小,应使用uninon代替,这样能走索引的走索引,不能走索引的就全表扫描。
9. 能用union all就不用union
union all 不去重复,union去重复,union使用了临时表,应尽量避免使用临时表

10. 复合索引
对于复合索引,如果单独使用右边的索引字段作为条件时不走索引的。即复合索引如果不满足最左原则leftmost不会走复合索引
暂未完成,更新还会继续