Random erasing
论文名称:Random erasing data augmentation
论文地址:https://arxiv.org/pdf/1708.04896v2.pdf
github: https://github.com/zhunzhong07/Random-Erasing
作者提出的目的主要是模拟遮挡,从而提高模型泛化能力。如果把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景。

可以通过参数控制擦除的面积比例和宽高比,如果随机到指定数目还无法满足设置条件,则强制返回。 一些可视化效果如下:

对于目标检测,作者还实现了3种做法,如下图所示:

和其他数据增强联合使用:

代码:
if random.uniform(0, 1) > self.probability: return img for attempt in range(100): area = img.size()[1] * img.size()[2] target_area = random.uniform(self.sl, self.sh) * area aspect_ratio = random.uniform(self.r1, 1 / self.r1) h = int(round(math.sqrt(target_area * aspect_ratio))) w = int(round(math.sqrt(target_area / aspect_ratio))) if w < img.size()[2] and h < img.size()[1]: x1 = random.randint(0, img.size()[1] - h) y1 = random.randint(0, img.size()[2] - w) if img.size()[0] == 3: img[0, x1:x1 + h, y1:y1 + w] = self.mean[0] img[1, x1:x1 + h, y1:y1 + w] = self.mean[1] img[2, x1:x1 + h, y1:y1 + w] = self.mean[2] else: img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]
Cutout
论文名称:Improved Regularization of Convolutional Neural Networks with Cutout
论文地址:https://arxiv.org/abs/1708.04552v2
github: https://github.com/uoguelph-mlrg/Cutout
本文和随机擦除几乎同时发表,区别在于在cutout中,擦除矩形区域存在一定概率不完全在原图像中的。而在Random Erasing中,擦除矩形区域一定在原图像内。Cutout变相的实现了任意大小的擦除,以及保留更多重要区域。实现上比random erasing简单,随机选择一个固定大小的正方形区域,然后采用全0填充就OK了,当然为了避免填充0值对训练的影响,应该要对数据进行中心归一化操作,norm到0。

作者其实开发了一个早期做法,具体是:在训练的每个epoch过程中,保存每张图片对应的最大激活特征图(以resnet为例,可以是layer4层特征图),在下一个训练回合,对每张图片的最大激活图进行上采样到和原图一样大,然后使用阈值切分为二值图,盖在原图上再输入到cnn中进行训练,像这样:

Hide-and-Seek
论文名称:Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
论文地址:https://arxiv.org/abs/1811.02545
github地址:https://github.com/kkanshul/Hide-and-Seek
可以认为是random earsing的推广。核心思想就是去掉一些区域,使得其他区域也可以识别出物体,增加特征可判别能力。和大部分细粒度论文思想类型,如下所示:
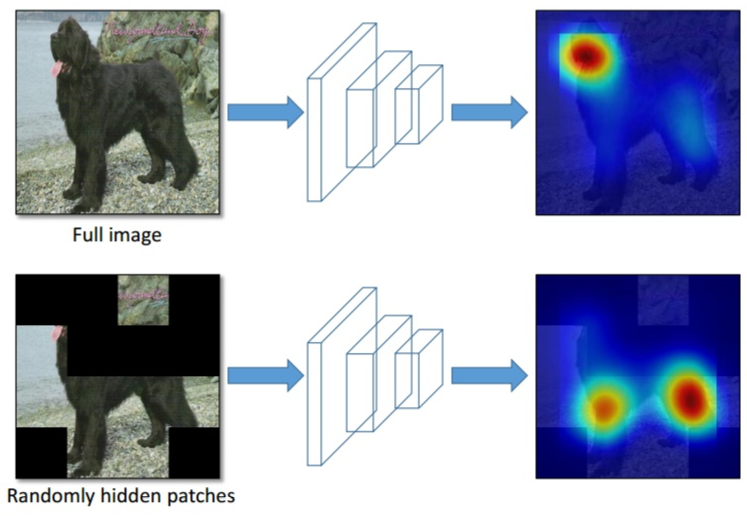
做法是将图片切分为sxs个网格,每个网格采用一定概率进行遮挡,可以模拟出随机擦除和cutout效果。作者认为隐藏值的设置可能会改变训练数据的分布。如果暴力填黑,认为会出现训练和测试数据分布不一致问题,可能不好,特别是对于第一层卷积而言。作者采用了一些理论计算,最后得到采用整个数据集的均值来填充造成的影响最小:

GridMask Data Augmentation
论文名称:GridMask Data Augmentation
论文地址:https://arxiv.org/abs/2001.04086v2
本文的出发点是:删除信息和保留信息之间要做一个平衡,而随机擦除、cutout和hide-seek方法都可能会出现可判别区域全部删除或者全部保留,引入噪声,可能不好。如下所示:

文中提出只需要结构化drop操作,例如均匀分布似的删除正方形区域即可。并且可以通过密度和size参数控制,达到平衡。如下所示:

其包括4个超参:
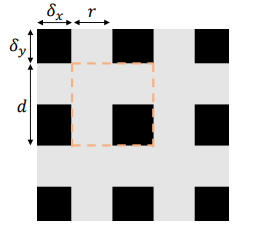
橙色的框框代表一个unit,r表示灰色的小块块占这个unit的比例;d表示的是这个unit的长度,其他两个表示第一个unit的偏移。
object Region Mining with Adversarial Erasing
论文地址:https://arxiv.org/pdf/1703.08448.pdf
本文要解决的问题是使用分类做法来做分割任务(弱监督分割),通过迭代训练的方式不断挖掘不同的可判别区域,最终组合得到完整的分割结果。第t次训练迭代(一次迭代就是指的一次完整的训练过程),对于每张图片都可以得到cam图(类别激活图),将cam图二值化然后盖在原图上,进行下一次迭代训练,每次迭代都是学习一个不同的可判别区域,迭代结束条件就是分类性能不行了,因为可判别区域全部被盖住了(由于该参数其实很难设置,故实验直接取3)。最后的分割结果就是多次迭代的cam图叠加起来即可:

Stylized-ImageNet
论文名称:ImageNet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness
本文属于数据增强论文,做的唯一一件事就是:对ImageNet数据集进行风格化。
本文结论是:CNN训练学习到的实际是纹理特征(texture bias)而不是形状特征,这和人类的认知方式有所区别,如论文题目所言,存在纹理偏置。而本文引入风格化imagenet数据集,平衡纹理和形状偏置,提高泛化能力。
本文指出在ImageNet上训练的CNN强烈的偏向于识别纹理而不是形状,这和人的行为是极为不同的,存在纹理偏差,所以提出了Stylized-ImageNet数据,混合原始数据训练就可以实现既关注纹理,也关注形状(也就是论文标题提到的减少纹理偏向,增加形状偏向)。从而不仅更适合人类的行为,更惊讶的是提升了目标检测的精度,以及鲁棒性,更加体现了基于形状表示的优势。