简介
来源:廖雪峰的官方网站
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。
而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
函数式编程最早是数学家阿隆佐·邱奇研究的一套函数变换逻辑,又称Lambda Calculus(λ-Calculus),所以也经常把函数式编程称为Lambda计算。
Java平台从Java 8开始,支持函数式编程。
这部分整理的导图:链接
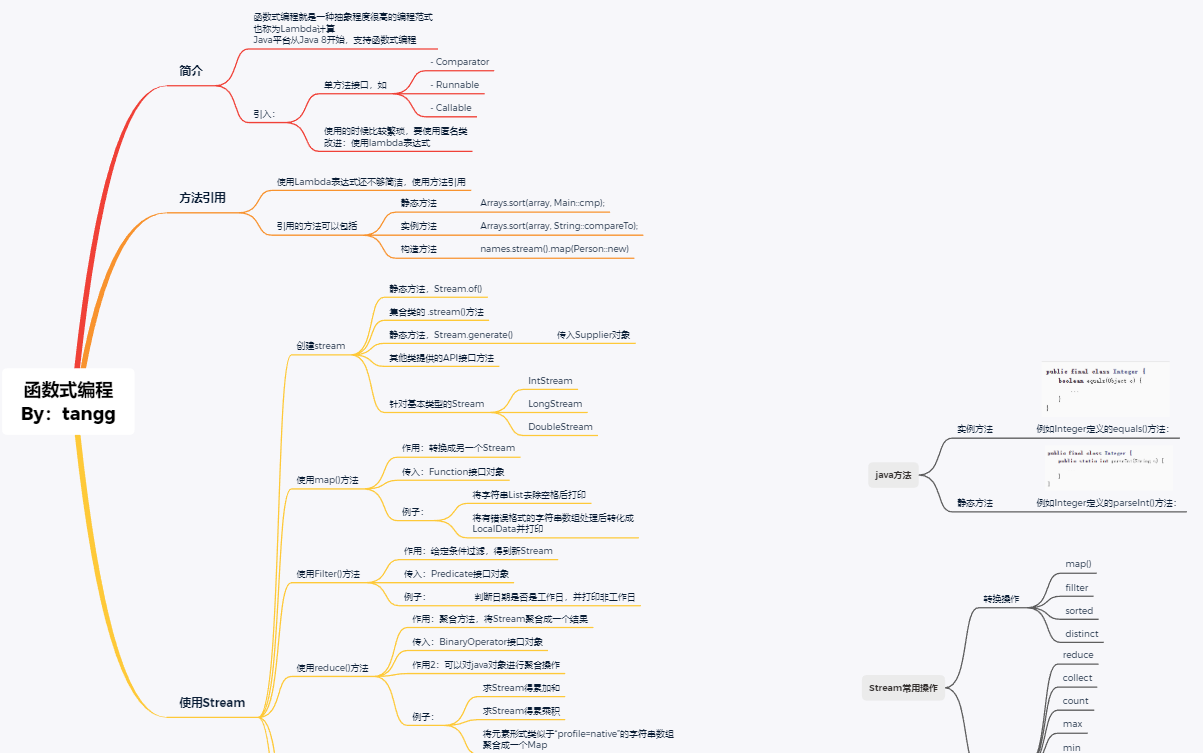
1. Lambda基础
回顾:java的方法

**概念:FunctionalInterface **
把只定义了单方法的接口称之为FunctionalInterface,用注解@FunctionalInterface标记。
- Comparator
- Runnable
- Callable
例如,Callable接口:
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
Lambda表达式
在使用单方法接口的时候,以Comparator为例,我们想要调用Arrays.sort()时,可以传入一个Comparator实例,以匿名类方式编写如下:
String[] array = ...
Arrays.sort(array, new Comparator<String>() {
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});
上述写法非常繁琐。从Java 8开始,我们可以用Lambda表达式替换单方法接口。改写上述代码如下:
// Lambda
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, (s1, s2) -> {
return s1.compareTo(s2);
});
System.out.println(String.join(", ", array));
}
}
观察Lambda表达式的写法,它只需要写出方法定义:
(s1, s2) -> {
return s1.compareTo(s2);
}
其中,
参数是(s1, s2),参数类型可以省略,因为编译器可以自动推断出String类型。
-> { ... }表示方法体,所有代码写在内部即可。Lambda表达式没有class定义,因此写法非常简洁。
如果只有一行return xxx的代码,完全可以用更简单的写法:
Arrays.sort(array, (s1, s2) -> s1.compareTo(s2));
返回值的类型也是由编译器自动推断的,这里推断出的返回值是int,因此,只要返回int,编译器就不会报错。
2. 方法引用
在上面介绍了 Lambda的表达式,但是,还可以更进一步,不写表达式,直接传入方法引用
2.1 引用静态方法
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, Main::cmp);
System.out.println(String.join(", ", array));
}
static int cmp(String s1, String s2) {
return s1.compareTo(s2);
}
}
在Arrays.sort()中直接传入了静态方法cmp的引用,用Main::cmp表示。
因此,所谓方法引用,是指如果某个方法签名和接口恰好一致,就可以直接传入方法引用。
注意:在这里,方法签名只看参数类型和返回类型,不看方法名称,也不看类的继承关系。
因为Comparator接口定义的方法是int compare(String, String),和静态方法int cmp(String, String)相比,除了方法名外,方法参数一致,返回类型相同,因此,我们说两者的方法签名一致,可以直接把方法名作为Lambda表达式传入:
Arrays.sort(array, Main::cmp);
2.2 引用实例方法
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, String::compareTo);
System.out.println(String.join(", ", array));
}
}
观察String.compareTo()的方法定义:
public final class String {
public int compareTo(String o) {
...
}
}
这个方法的签名只有一个参数,为什么和int Comparator.compare(String, String)能匹配呢?
因为实例方法有一个隐含的this参数,String类的compareTo()方法在实际调用的时候,第一个隐含参数总是传入this,相当于静态方法:
public static int compareTo(this, String o);
所以,String.compareTo()方法也可作为方法引用传入。
2.3 引用构造方法
例子:如果要把一个List转换为List
// 引用构造方法
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
List<String> names = List.of("Bob", "Alice", "Tim");
List<Person> persons = names
.stream()
.map(Person::new)
.collect(Collectors.toList());
System.out.println(persons);
}
}
class Person {
String name;
public Person(String name) {
this.name = name;
}
public String toString() {
return "Person:" + this.name;
}
}
这里的map()需要传入的FunctionalInterface的定义是:
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
把泛型对应上就是方法签名Person apply(String),即传入参数String,返回类型Person。
而Person类的构造方法恰好满足这个条件,因为构造方法的参数是String,
构造方法虽然没有return语句,但它会隐式地返回this实例,类型就是Person,因此,此处可以引用构造方法。构造方法的引用写法是类名::new,因此,此处传入Person::new。
小结
FunctionalInterface允许传入:
- 接口的实现类(传统写法,代码较繁琐);
- Lambda表达式(只需列出参数名,由编译器推断类型);
- 符合方法签名的静态方法;
- 符合方法签名的实例方法(实例类型被看做第一个参数类型);
- 符合方法签名的构造方法(实例类型被看做返回类型)。
FunctionalInterface不强制继承关系,不需要方法名称相同,只要求方法参数(类型和数量)与方法返回类型相同,即认为方法签名相同。
3. 使用Stream
Java从8开始,不但引入了Lambda表达式,还引入了流式API:Stream API。它位于java.util.stream包中。
简介:
创建Stream
Stream<BigInteger> naturals = createNaturalStream();
naturals.map(n -> n.multiply(n)) // 1, 4, 9, 16, 25...
.limit(100)
.forEach(System.out::println);
Stream的特点:
-
它可以“存储”有限个或无限个元素。这里的存储打了个引号,是因为元素有可能已经全部存储在内存中,也有可能是根据需要实时计算出来的。
-
一个
Stream可以轻易地转换为另一个Stream,而不是修改原Stream本身。 -
真正的计算通常发生在最后结果的获取,也就是惰性计算。
通常把Stream的操作写成链式操作,代码更简洁:
createNaturalStream()
.map(BigInteger::multiply)
.limit(100)
.forEach(System.out::println);
因此,Stream API的基本用法就是:创建一个Stream,然后做若干次转换,最后调用一个求值方法获取真正计算的结果:
int result = createNaturalStream() // 创建Stream
.filter(n -> n % 2 == 0) // 任意个转换
.map(n -> n * n) // 任意个转换
.limit(100) // 任意个转换
.sum(); // 最终计算结果
3.1 创建Stream
静态方法:Stream.of()
直接用Stream.of()静态方法,传入可变参数即创建了一个能输出确定元素的Stream:
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
Stream<String> stream = Stream.of("A", "B", "C", "D");
// forEach()方法相当于内部循环调用,
// 可传入符合Consumer接口的void accept(T t)的方法引用:
stream.forEach(System.out::println);
}
}
基于数组或Collection
第二种创建Stream的方法是基于一个数组或者Collection,这样该Stream输出的元素就是数组或者Collection持有的元素:
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" });
Stream<String> stream2 = List.of("X", "Y", "Z").stream();
stream1.forEach(System.out::println);
stream2.forEach(System.out::println);
}
}
把数组变成Stream使用Arrays.stream()方法。
对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream。
上述创建Stream的方法都是把一个现有的序列变为Stream,它的元素是固定的。
静态方法:Stream.genrate(),传入Supplier
创建Stream还可以通过Stream.generate()方法,它需要传入一个Supplier对象:
Stream<String> s = Stream.generate(Supplier<String> sp);
基于Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。
例如,我们编写一个能不断生成自然数的Supplier,它的代码非常简单,每次调用get()方法,就生成下一个自然数:
import java.util.function.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
Stream<Integer> natual = Stream.generate(new NatualSupplier());
// 注意:无限序列必须先变成有限序列再打印:
natual.limit(20).forEach(System.out::println);
}
}
class NatualSupplier implements Supplier<Integer> {
int n = 0;
public Integer get() {
n++;
return n;
}
}
每个元素都是实时计算出来的,用的时候再算。
对于无限序列,如果直接调用forEach()或者count()这些最终求值操作,会进入死循环,因为永远无法计算完这个序列,所以正确的方法是先把无限序列变成有限序列,例如,用limit()方法可以截取前面若干个元素,这样就变成了一个有限序列,对这个有限序列调用forEach()或者count()操作就没有问题。
其他方法
通过一些API提供的接口,直接获得Stream。
例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容:
try (Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))) {
...
}
此方法对于按行遍历文本文件十分有用。
另外,正则表达式的Pattern对象有一个splitAsStream()方法,可以直接把一个长字符串分割成Stream序列而不是数组:
Pattern p = Pattern.compile("\s+");
Stream<String> s = p.splitAsStream("The quick brown fox jumps over the lazy dog");
s.forEach(System.out::println);
基本类型的Stream
因为Java的范型不支持基本类型,所以我们无法用Stream这样的类型,会发生编译错误。
为了保存int,只能使用String,但这样会产生频繁的装箱、拆箱操作。
为了提高效率,Java标准库提供了IntStream、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和范型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:
// 将int[]数组变为IntStream:
IntStream is = Arrays.stream(new int[] { 1, 2, 3 });
// 将Stream<String>转换为LongStream:
LongStream ls = List.of("1", "2", "3").stream().mapToLong(Long::parseLong);
3.2 使用map
map()方法用于将一个Stream的每个元素映射成另一个元素并转换成一个新的Stream;- 可以将一种元素类型转换成另一种元素类型。
map操作,把一个Stream的每个元素一一对应到应用了目标函数的结果上。
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> s2 = s.map(n -> n * n);
Function接口对象
如果我们查看Stream的源码,会发现map()方法接收的对象是Function接口对象,它定义了一个apply()方法,负责把一个T类型转换成R类型:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
其中,Function的定义是:
@FunctionalInterface
public interface Function<T, R> {
// 将T类型转换为R:
R apply(T t);
}
利用map(),不但能完成数学计算,对于字符串操作,以及任何Java对象都是非常有用的。例如:
import java.util.*;
mport java.util.stream.*;
public class Main {
public static void main(String[] args) {
List.of(" Apple ", " pear ", " ORANGE", " BaNaNa ")
.stream()
.map(String::trim) // 去空格
.map(String::toLowerCase) // 变小写
.forEach(System.out::println); // 打印
}
}
例子:
使用map()把一组String转换为LocalDate并打印。
package com.itranswarp.learnjava;
import java.time.LocalDate;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] array = new String[] { " 2019-12-31 ", "2020 - 01-09 ", "2020- 05 - 01 ", "2022 - 02 - 01", " 2025-01 -01" };
Arrays.stream(array)
// .map(s -> s.replaceAll("\s+", "")) //使用正则表达式,将空格删除掉
.map(s -> s.replace(" ", ""))
.map(LocalDate::parse)
.forEach(System.out::println);
}
}
3.3 使用filter
Stream.filter()是Stream的另一个常用转换方法。
所谓filter()操作,就是对一个Stream的所有元素一一进行测试,不满足条件的就被“滤掉”了,剩下的满足条件的元素就构成了一个新的Stream。
例如,我们对1,2,3,4,5这个Stream调用filter(),传入的测试函数f(x) = x % 2 != 0用来判断元素是否是奇数,这样就过滤掉偶数,只剩下奇数,因此我们得到了另一个序列1,3,5:
例子:只保留奇数
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9)
.filter(n -> n % 2 != 0)
.forEach(System.out::println);
}
}
Predicate接口对象
filter()方法接收的对象是Predicate接口对象,它定义了一个test()方法,负责判断元素是否符合条件:
@FunctionalInterface
public interface Predicate<T> {
// 判断元素t是否符合条件:
boolean test(T t);
}
filter()除了常用于数值外,也可应用于任何Java对象。
例子:从一组给定的LocalData中过滤掉工作日,得到休息日
import java.time.*;
import java.util.function.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
Stream.generate(new LocalDateSupplier())
.limit(31)
.filter(ldt -> ldt.getDayOfWeek() == DayOfWeek.SATURDAY || ldt.getDayOfWeek() == DayOfWeek.SUNDAY)
.forEach(System.out::println);
}
}
class LocalDateSupplier implements Supplier<LocalDate> {
LocalDate start = LocalDate.of(2020, 1, 1);
int n = -1;
public LocalDate get() {
n++;
return start.plusDays(n);
}
}
3.4 使用reduce
map()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果。
例子:Stream求和操作
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, n) -> acc + n);
System.out.println(sum); // 45
}
}
BinaryOperator接口对象
reduce()方法传入的对象是BinaryOperator接口,它定义了一个apply()方法,负责把上次累加的结果和本次的元素 进行运算,并返回累加的结果:
@FunctionalInterface
public interface BinaryOperator<T> {
// Bi操作:两个输入,一个输出
T apply(T t, T u);
}
用for循环改写一下:
Stream<Integer> stream = ...
int sum = 0;
for (n : stream) {
sum = (sum, n) -> sum + n;
}
例子:用reduce求乘积
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(1, (acc, n) -> acc * n);
System.out.println(s); // 362880
}
}
对Java对象进行操作
除了可以对数值进行累积计算外,灵活运用reduce()也可以对Java对象进行操作。下面的代码演示了如何将配置文件的每一行配置通过map()和reduce()操作聚合成一个Map:(后续使用stream的输出为map集合的功能操作起来更加方便)
import java.util.*;
public class Main {
public static void main(String[] args) {
//按行读取配置文件,读取完成后存储在list中
List<String> props = List.of("profile=native", "debug=true", "logging=warn", "interval=500");
//使用Stream的reduce功能
Map<String, String> map = props.stream()
//读取到的是每一行的字符
.map(kv -> {
//先将字符串拆成等号前后两部分
String[] ss = kv.split("=",2);
//每一个(每一行)的字符串都将返回一个map
return Map.of(ss[0], ss[1]);
})
//将上面得到的多个map聚合成一个map
.reduce(new HashMap<String, String>(), (m, kv) -> {
m.putAll(kv);
return m;
});
//打印转化后并且聚合后的map
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
}
小结
reduce()方法将一个Stream的每个元素依次作用于BinaryOperator,并将结果合并。
reduce()是聚合方法,聚合方法会立刻对Stream进行计算。
3.5 输出集合
对Stream来说操作可以分为两类,
- 转换操作,即把一个
Stream转换为另一个Stream,例如map()和filter(), - 聚合操作,即对
Stream的每个元素进行计算,得到一个确定的结果,例如reduce()。
区分这两种操作是非常重要的,因为对于Stream来说,对其进行转换操作并不会触发任何计算!
Stream通过collect()方法可以方便地输出为List、Set、Map,还可以分组输出(属于聚合操作)
输出为List
如果我们希望把Stream的元素保存到集合,例如List,因为List的元素是确定的Java对象,因此,把Stream变为List不是一个转换操作,而是一个聚合操作,它会强制Stream输出每个元素。
例子: 将一组String先过滤掉空字符串,然后把非空字符串保存到List中
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
Stream<String> stream = Stream.of("Apple", "", null, "Pear", " ", "Orange");
List<String> list = stream.filter(s -> s != null && !s.isBlank())
.collect(Collectors.toList());
System.out.println(list);
}
}
把Stream的每个元素收集到List的方法是调用collect()并传入Collectors.toList()对象,它实际上是一个Collector实例,通过类似reduce()的操作,把每个元素添加到一个收集器中(实际上是ArrayList)。
类似的,collect(Collectors.toSet())可以把Stream的每个元素收集到Set中。
输出为数组
把Stream的元素输出为数组和输出为List类似,我们只需要调用toArray()方法,并传入数组的“构造方法”:
List<String> list = List.of("Apple", "Banana", "Orange");
String[] array = list.stream().toArray(String[]::new);
注意到传入的“构造方法”是String[]::new,它的签名实际上是IntFunction定义的String[] apply(int),即传入int参数,获得String[]数组的返回值。
输出为Map
如果我们要把Stream的元素收集到Map中,就稍微麻烦一点。因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft");
Map<String, String> map = stream
.collect(Collectors.toMap(
// 把元素s映射为key:
s -> s.substring(0, s.indexOf(':')),
// 把元素s映射为value:
s -> s.substring(s.indexOf(':') + 1)));
System.out.println(map);
}
}
分组输出
Stream还有一个强大的分组功能,可以按组输出。我们看下面的例子:
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots");
Map<String, List<String>> groups = list.stream()
.collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList()));
System.out.println(groups);
}
}
分组输出使用Collectors.groupingBy(),它需要提供两个函数:
- 一个是分组的key,这里使用
s -> s.substring(0, 1),表示只要首字母相同的String分到一组, - 第二个是分组的value,这里直接使用
Collectors.toList(),表示输出为List,上述代码运行结果如下:
{
A=[Apple, Avocado, Apricots],
B=[Banana, Blackberry],
C=[Coconut, Cherry]
}
3.6 其他操作
排序
(是转化操作)
对Stream的元素进行排序十分简单,只需调用sorted()方法:
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("Orange", "apple", "Banana")
.stream()
.sorted()
.collect(Collectors.toList());
System.out.println(list);
}
}
Comparable接口
此方法要求Stream的每个元素必须实现Comparable接口。如果要自定义排序,传入指定的Comparator即可:
List<String> list = List.of("Orange", "apple", "Banana")
.stream()
.sorted(String::compareToIgnoreCase)
.collect(Collectors.toList());
注意sorted()只是一个转换操作,它会返回一个新的Stream
去重
对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():
List.of("A", "B", "A", "C", "B", "D")
.stream()
.distinct()
.collect(Collectors.toList()); // [A, B, C, D]
截取
是转换操作
截取操作常用于把一个无限的Stream转换成有限的Stream,
skip()用于跳过当前Stream的前N个元素,
limit()用于截取当前Stream最多前N个元素:
List.of("A", "B", "C", "D", "E", "F")
.stream()
.skip(2) // 跳过A, B
.limit(3) // 截取C, D, E
.collect(Collectors.toList()); // [C, D, E]
截取操作也是一个转换操作,将返回新的Stream。
合并
将两个Stream合并为一个Stream可以使用Stream的静态方法concat():
Stream<String> s1 = List.of("A", "B", "C").stream();
Stream<String> s2 = List.of("D", "E").stream();
// 合并:
Stream<String> s = Stream.concat(s1, s2);
System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]
flatMap
指把Stream的每个元素(这里是List)映射为Stream,然后合并成一个新的Stream:
例子:如果Stream的元素是集合:
Stream<List<Integer>> s = Stream.of(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9));
而我们希望把上述Stream转换为Stream,就可以使用flatMap():
Stream<Integer> i = s.flatMap(list -> list.stream());
并行
通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。
把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换:
Stream<String> s = ...
String[] result = s.parallel() // 变成一个可以并行处理的Stream
.sorted() // 可以进行并行排序
.toArray(String[]::new);
其他聚合方法
测试Stream的元素是否满足以下条件:
boolean allMatch(Predicate):测试是否所有元素均满足测试条件;boolean anyMatch(Predicate):测试是否至少有一个元素满足测试条件。
最后一个常用的方法是forEach(),它可以循环处理Stream的每个元素,我们经常传入System.out::println来打印Stream的元素:
Stream<String> s = ...
s.forEach(str -> {
System.out.println("Hello, " + str);
});
小结
Stream提供的常用操作有:
转换操作:
map(),给定规则转换filter(),给定规则过滤sorted(),排序distinct();去重
聚合操作:
reduce(),聚合collect(),输出集合count(),元素计数max(),找出最大元素min(),找出最小元素sum(),针对IntStream、LongStream和DoubleStream元素求和average(),针对IntStream、LongStream和DoubleStream元素求平均
合并操作:concat(),flatMap();
并行处理:parallel();
其他操作:allMatch(), anyMatch(), forEach()。