本文快速解析一下RPS/RFS的基本原理。
RPS-Receive Packet Steering
下面这个就是RPS的原理: 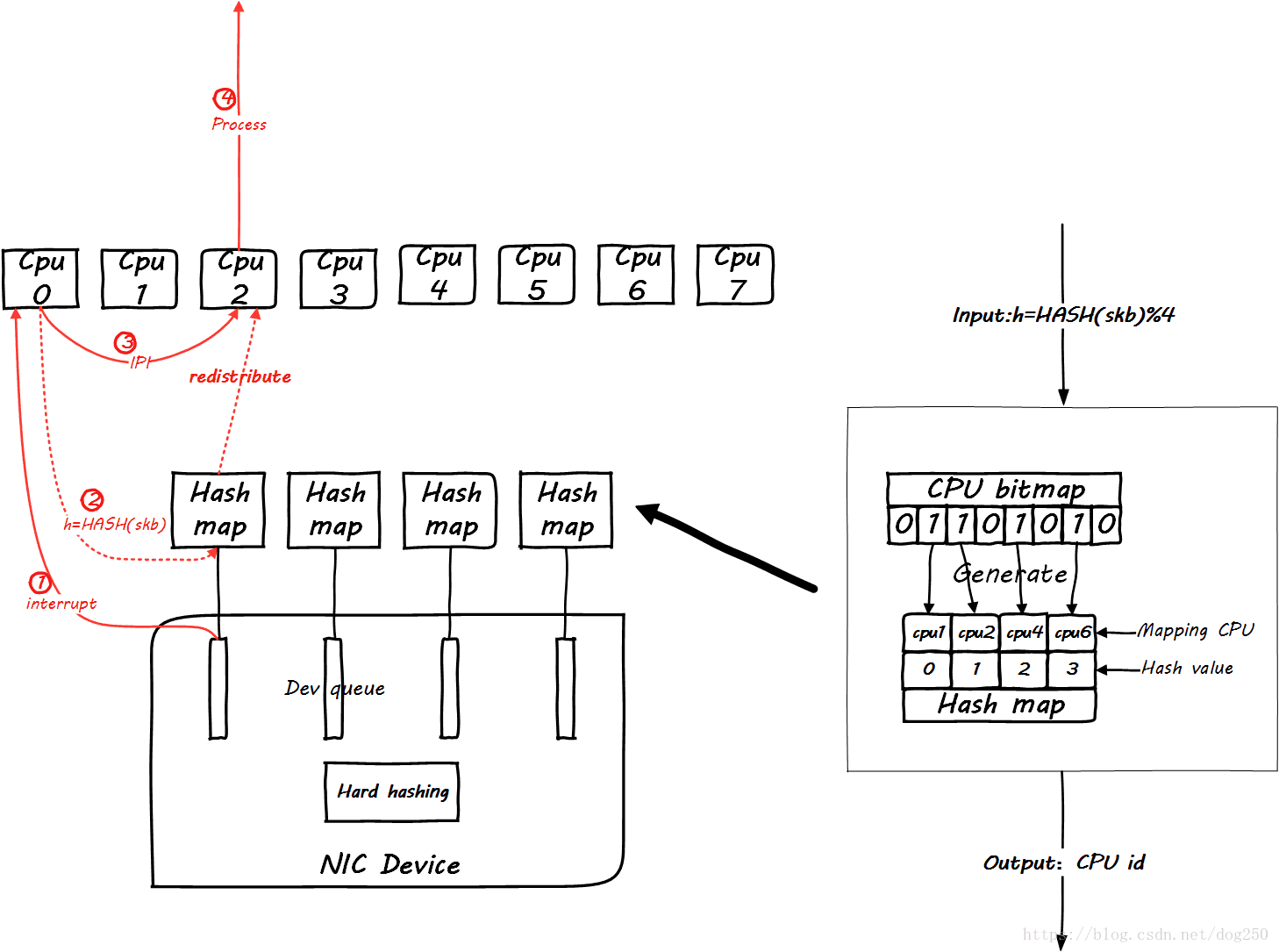
其实就是一个软件对CPU负载重分发的机制。其使能的作用点在CPU开始处理软中断的开始,即下面的地方:
netif_rx_internal netif_receive_skb_internal
RFS-Receive Flow Steering
RFS在RPS的基础上,充分考虑到同一个五元组flow进程上下文和软中断上下文之间处理CPU的一致性,为此在socket层面也要有相应的处理。
非常遗憾的是,一张图无法把这一切全部表达,那么我们分阶段进行,首先看同一个五元组flow第一个包到达的情形: 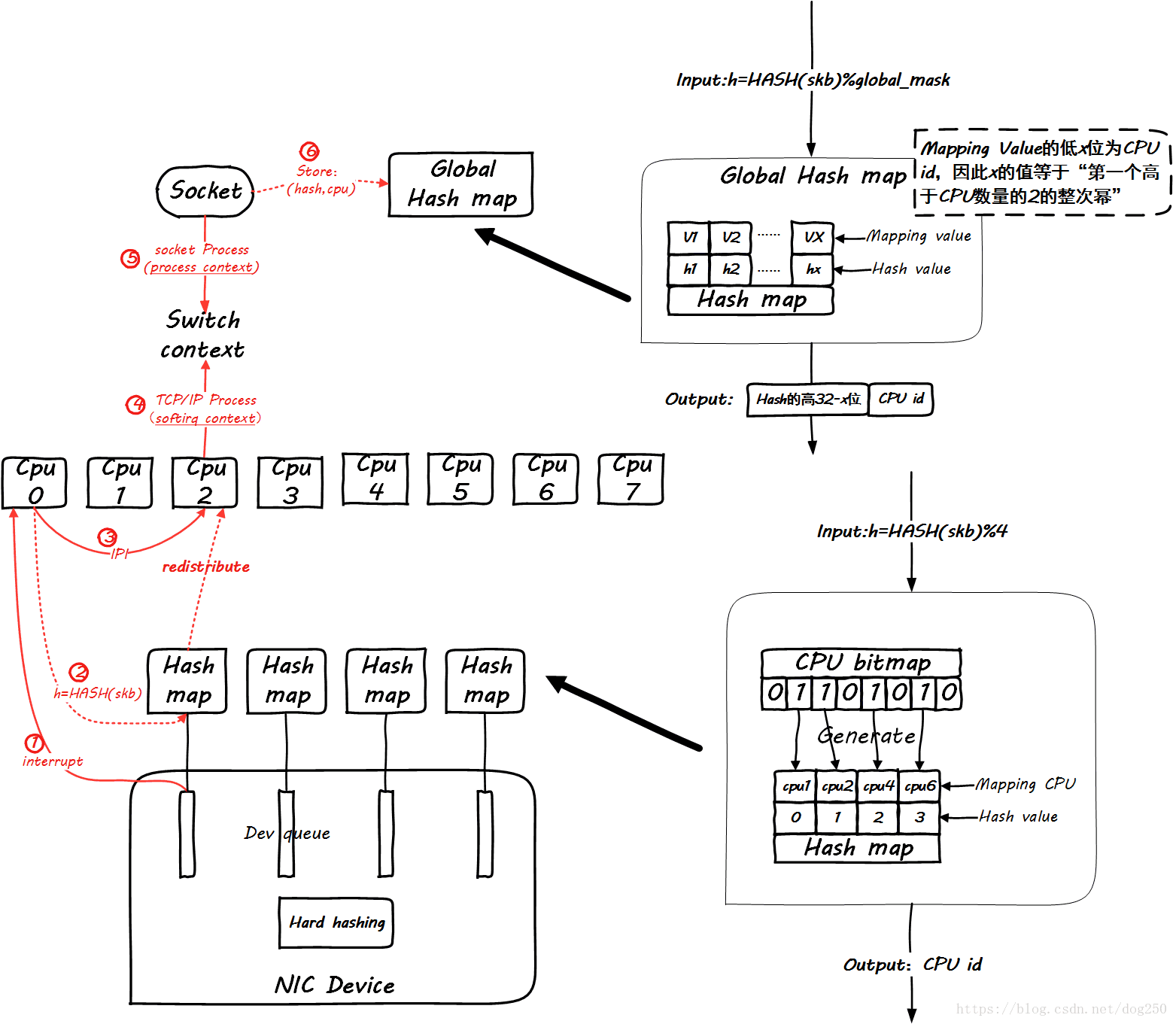
显然,global mapping作为全局映射,空间必须足够大才能容纳足够多的流,不然会相互覆盖。我建议设置成最大并发连接数的2倍。
然后,当同一个flow的后续包到来时,我们看一下global mapping如何起作用。先来看后续第一个包到来时的情景:
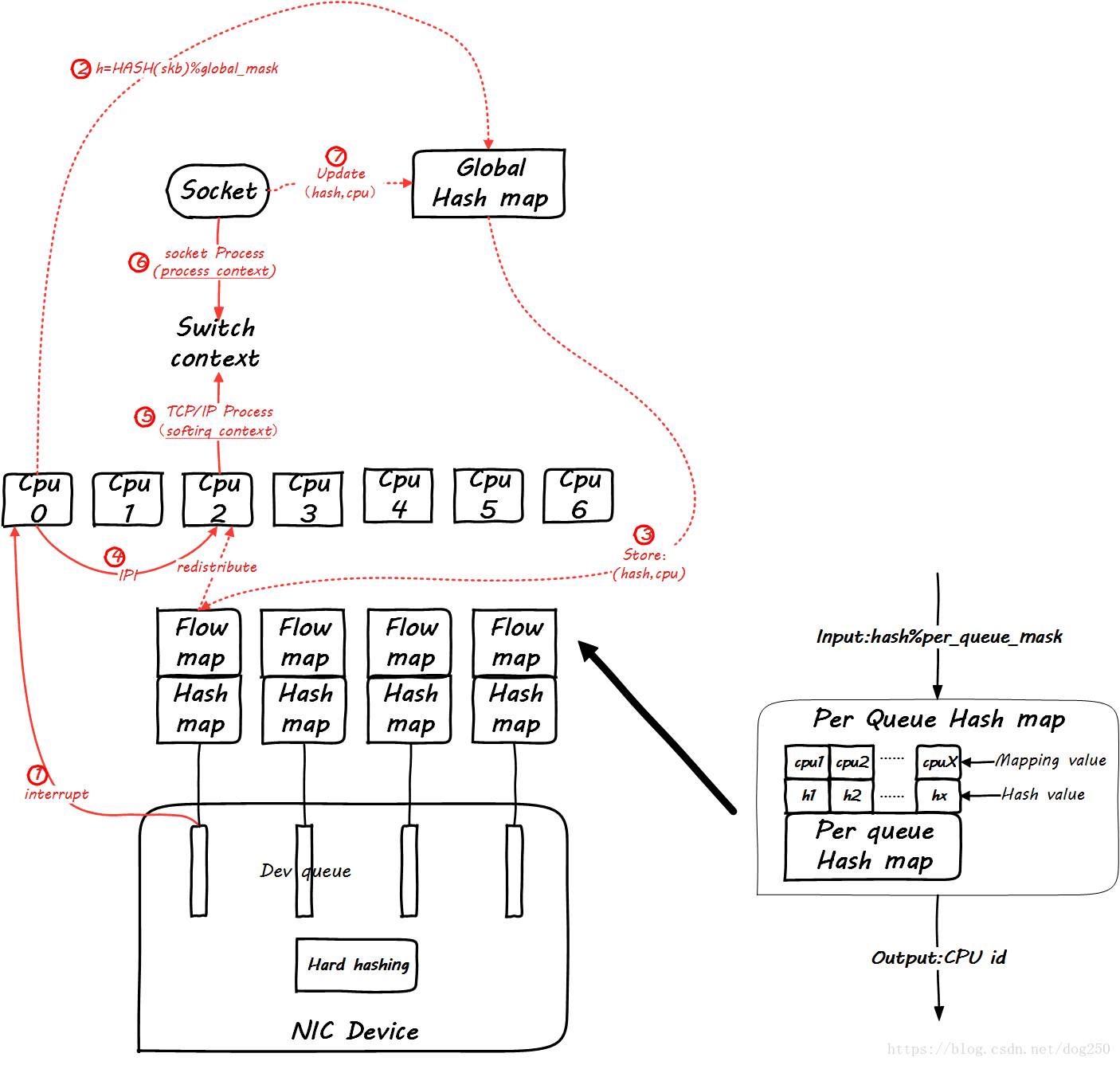
仔细看图,这里增加了一个Per Queue Hash map,这些map是从global map生成的,此后的数据包再到达时,就可以查这个map了:
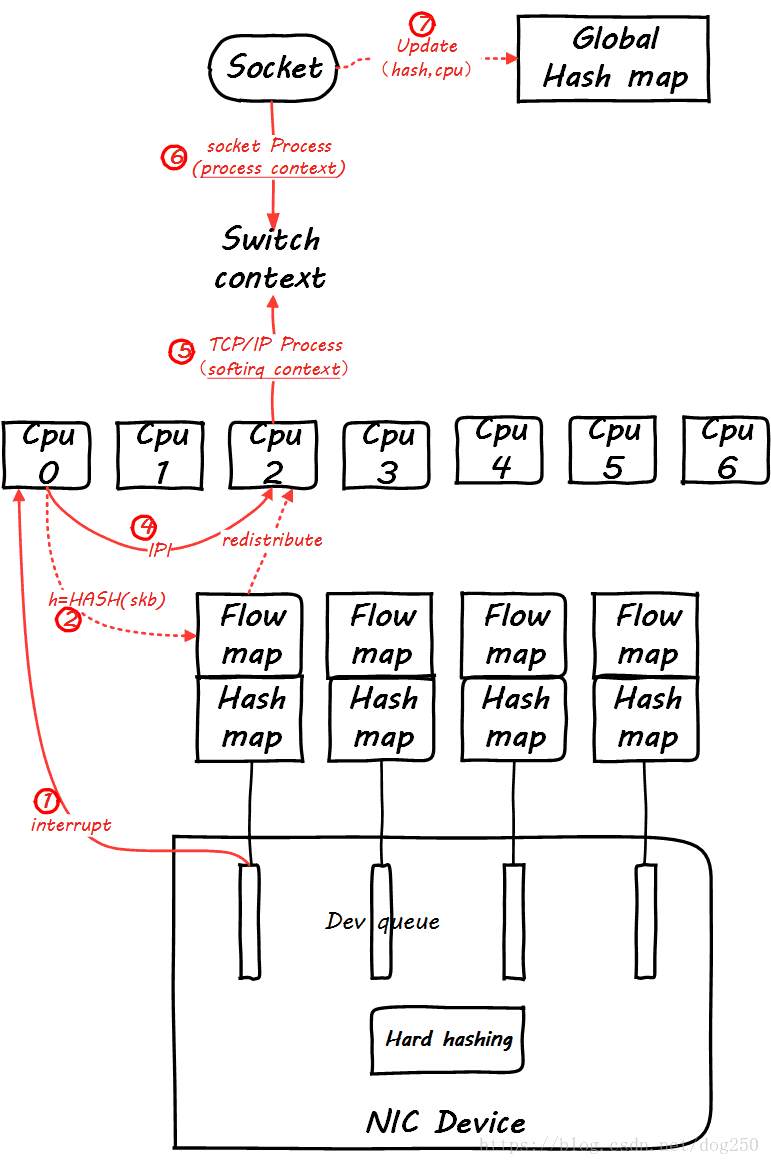
然而,这并没有看出来RFS和RPS的不同。
你能保证处理softirq和处理socket的是同一个CPU吗?你不能,有可能tcp_v4_rcv是CPU0在处理,然后在data_ready中把socket进程唤醒,然而调度器将进程wakeup到CPU1上了,这样在update global hash map的时候,就会更新一个不同的CPU,这个时候RFS的作用就体现了,RFS会把Per Queue Hash Map也更新了,进而接下来的数据包会全部重定向到新的CPU上,然而RPS并不会这么做。
RFS也不是只要发现CPU变了就无条件切换,而是要满足一个条件,即:
同一个流上次enqueue到旧CPU的数据包全部被处理完毕
如此可以保证同一个流处理的串行性,同时处理协议头的时候还能充分利用Hot cacheline。
Accelerated RFS
基本就是可以把软件发现的配置反向注入到硬件,需要硬件支持,不多说。
本文只讲原理,想知道Howto,请参考内核源码包Documentation/networking/scaling.txt文件。
trick and tips
有时候太均匀太平等了并不是好事。
在CPU运行繁重的用户态业务逻辑的时候,把中断打到同一个CPU上反而有一个天然限流的作用,要注意,先要找到瓶颈在哪里。如果瓶颈在业务逻辑的处理,那么当你启用RPS/RFS之后,你会发现用户态服务指标毫无起色,同时发现softirq飙高,这并不是一件好事。
参考下面的图示: 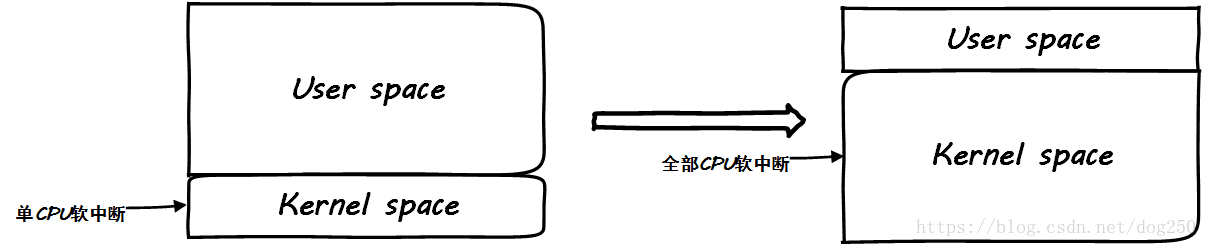
这样好吗?为了所谓内核态处理的优雅均衡,挤压了用户态的CPU时间,这是典型的初学者行为,为了内核而优化内核,典型的物业殴打业主!
其实,OS内核的作用只有一个,就是服务用户态业务逻辑的处理!
不多说。
作者:慕森王
链接:https://www.imooc.com/article/27960
来源:慕课网
原文:https://www.imooc.com/article/27960
上面的图是使用visio手工绘制主题画的