原文链接:http://tecdat.cn/?p=23038
原文出处:拓端数据部落公众号
简介
假设我们需要设计一个抽样调查,有一个完整的框架,包含目标人群的信息(识别信息和辅助信息)。如果我们的样本设计是分层的,我们需要选择如何在总体中形成分层,以便从现有的辅助信息中获得最大的优势。
换句话说,我们必须决定以何种方式来组合辅助变量(从现在开始是 "X "变量)的值,来确定一个新的变量,称为 "分层"。
为此,我们必须考虑到抽样调查的目标变量"Y "变量:如果为了形成分层,我们选择与Y变量最相关的X变量,那么由此产生的分层框架所抽取样本的效率就会大大增加。
每个活动变量的数值组合都决定了目标人群的特定分层,也就是 "最佳 "分层问题的可能解决方案。在这里,我们所说的最佳分层,是指能够确保最小样本成本的分层,足以满足对调查目标变量Y's的估计精度的约束(约束表示为不同兴趣领域的最大允许变异系数)。
当数据收集的成本在各分层中是统一的,那么总成本就与总体样本量成正比。一般来说,对于一个给定的总体来说,可能的替代分层的数量可能非常多,这取决于变量的数量和它们的值的数量,在这些情况下,不可能为了评估最佳分层而枚举它们。一个非常方便的解决方案是采用进化方法,包括应用遗传算法,在有限的迭代次数后可能收敛到一个接近最佳的解决方案。
步骤
抽样设计的优化首先是提供抽样框架,确定调查的目标估计值,并确定对其的精度限制。然后,在分析两组变量(分层和目标)之间的相关性的基础上,必须在框架中选择哪些分层变量。当所选的分层变量既是分类变量又是连续变量时,为了使它们具有同质性,应该对连续变量进行分类(例如使用聚类的K-means算法)。反之,如果分层变量都是连续类型的,则可以利用 "连续 "方法直接执行优化步骤。也可以执行两种优化,比较结果并选择更方便的方法。
在使用遗传算法进行优化之前,最好在使用k-means算法的基础上运行一个不同的快速优化任务,其目的有两个。
- 为最终分层的合适数量提供提示。
- 获得一个初始的 "好 "解决方案,作为遗传算法的 "建议",以加速其向最终解决方案的收敛。
在优化步骤中,可以指出必须选择的抽样单位集合("全取 "层)。优化之后,可以通过模拟从框架中选择大量的样本来评估解决方案的质量,并计算所有目标变量的抽样差异和偏差。还可以根据可用预算 "调整 "优化方案的样本量:如果允许更大的样本量,则按比例增加各层的抽样率,直到达到新的总样本量;如果我们不得不减少样本量,则采取相反的做法。
最后,我们开始选择样本。
在下文中,我们将从一个真实的抽样框架开始说明每个步骤。
优化步骤所需的输入准备
框架
为简单起见,让我们考虑数据集的一个子集。
-
-
head(mun)

为了限制处理时间,我们只选择了前三个地区和我们例子中感兴趣的变量。该数据集的每一行都包含一个城市的信息,由市政编号和市政名称标识,并属于三个选定的地区之一。
假设我们要计划一个抽样调查,目标估计值Ys是3个地区(感兴趣的区域)中每个地区的树林面积和建筑物面积的总数。假设每个市镇的总面积和总人口的值总是被更新。看相关矩阵。
cor(mun[,c(4:8)])

我们看到,树林面积和建筑物面积之间的相关性,以及"有建筑物的区域"和"总人口"之间的相关性都很高(分别为0.77和0.87),因此我们决定选择"有建筑物的区域","总人口"作为我们的框架中的分层变量X。
首先,我们决定将分层变量视为分类变量,所以我们必须对它们进行聚类。一个合适的方法是应用k-means聚类方法。
我们现在可以按照要求的格式定义框架数据帧。以合适的模型组织数据,以便进行下一步处理。
-
Frame(df = mun,value = "REG")
-
-
head(frame1)

Strata分层数据框
这个数据框架不是必需的,因为它是由从数据框架中自动生成的。不过,我们需要使用它来分析框架的初始分层,和在没有优化的情况下可能出现相关样本量。
Strata(frameF)

该数据框架中的每一行都输出了与给定分层有关的信息(通过对每个单元与X变量的值进行交叉分类获得),包括:
- 分层的标识符(名为 "strato")。
- 与框架中的变量相对应的m个辅助变量(从X1到Xm命名)的值。
- 人口中的单位总数(名为 "N")。
- 标志(名为'cens'),表示该层是要进行普查(=1)还是抽样调查(=0)。
- 成本变量,表示该分层中每个单位的访谈成本。
- 每个目标变量y的平均数和标准差,分别命名为 "Mi "和 "Si")。
- 分层所属的关注域的值('DOM1')。
精度约束
误差数据框包含对目标估计值设置的精度约束。这意味着要为每个目标变量和每个域值定义一个最大的变异系数。这个框架的每一行都与感兴趣的特定子域中的精度约束有关,由domainvalue值确定。在我们的案例中,我们选择定义以下约束:
- 分层的标识符。
- 与框架中的变量相对应的m个辅助变量(从X1到Xm命名)的值。
- 人口中的单位总数(名为 "N")。
- 标志(名为'cens'),表示该层是要进行普查(=1)还是抽样调查(=0)。
- 成本变量,表示该分层中每个单位的访谈成本。
- 每个目标变量y的平均数和标准差,分别命名为 "Mi "和 "Si")。
- 分层所属的关注域的值('DOM1')。
-
ndom <- length(unique(REG))
-
-
cv

这个例子报告了变量Y1和Y2的精度约束(允许的最大CV等于10%),这些约束对于域级DOM1的所有3个不同的子域(都是一样的。当然,我们可以按地区区分精度约束。需要强调的是,'domainvalue'的值与数据框中的值相同,并且与分层数据框中的变量'DOM1'的值对应。
现在我们想用函数bethel(Bethel(1989))来确定总的样本量,以及在给定分层下的相关分配。
hel(strata1,cv)
![]()
这是优化前,在当前分层下满足精度约束所需的总样本量(570)。
优化
执行优化步骤的函数。实际上,调用三个不同的优化函数:
- 优化分层(方法=原子,分层变量是分类的);
- 优化分层2(方法=连续,分层变量是连续的);
- 优化空间分层(方法=空间,分层变量是连续的,或为分类的)。
这里我们报告与三种方法有关的最重要的参数:
| 参数 | 说明 |
|---|---|
| frame | 数据框架的名称,包含与抽样框架有关的信息 |
| cens | 包含在任何情况下要选择的单位的数据框名称 |
| n | 要获得的最终优化分层的数量 |
| err | 包含精度等级的数据帧 |
| min | 每个层必须分配的最低单位数 |
‘atomic’方法
第一次运行,我们执行优化步骤(由于分层变量是分类类型的,所以需要使用atomic方法)。
-
Strata(method = "atomic",
-
-
pops = 10)

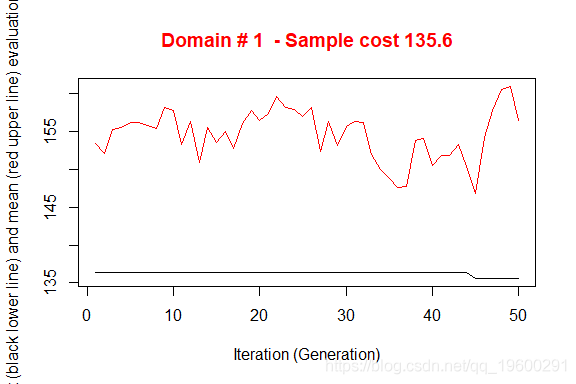
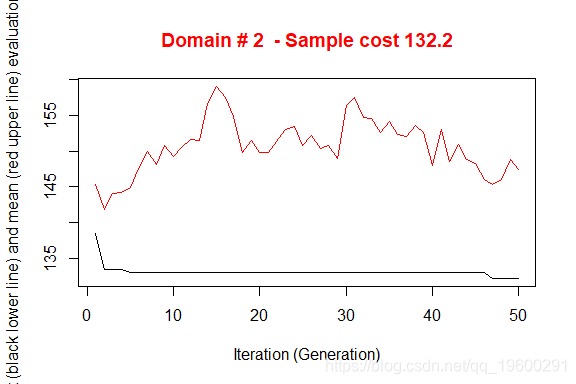
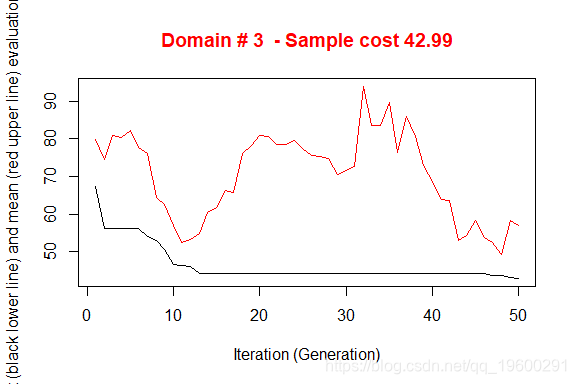
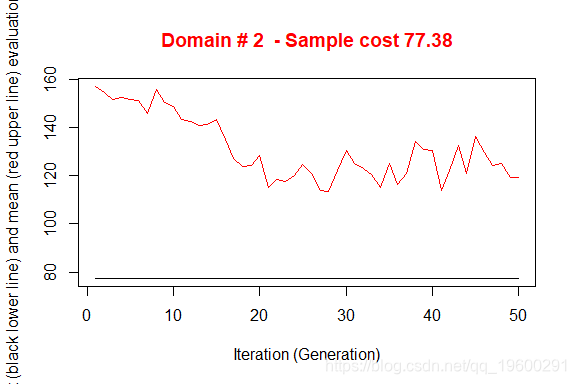
执行产生了3个不同的优化问题的解决方案。图中说明了从初始解开始向最终解收敛的情况。在X轴上报告了已执行的迭代,从1到最大,而在Y轴上报告了为满足精度约束所需的样本大小。上部(红色)线代表每次迭代的平均样本大小,而下部(黑色)线代表直到第i次迭代所发现的最佳解决方案。
我们可以通过执行函数来计算(分析)预期的CVs:

所得到的满足精度约束的样本总规模比简单应用Bethel算法对初始分层所得到的要低得多,但还不能令人满意。
为了探索其他解决方案,我们可能希望将抽样框架中的每个单元都视为一个原子分层,并让优化步骤根据Y变量的值对其进行汇总。在任何情况下,由于我们必须指出至少一个X变量,我们可以为此使用一个简单的递增数字。
-
-
frame2 <- FrameDF( mun)
-
head(frame2)

我们可以使用这种方法,因为框架中的单位数量很少。
即便如此,对1823个层的处理也可能很慢。
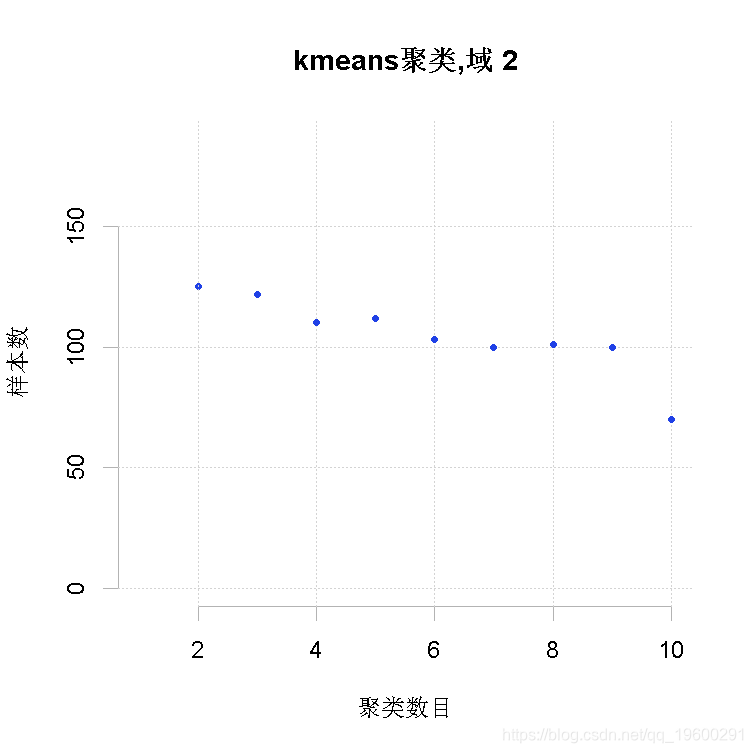
为了加快向最优解收敛的速度,可以给一个初始解作为 "建议"。通过考虑所有目标变量Y的均值对原子层进行聚类来产生这个初始解。满足精度约束所需的样本量为最小值的聚类数目被保留为最优数目。此外,每个领域内的最佳聚类数也被确定。可以指出要获得的最大聚类层数。
-
Strata(frame2, progress=F)
-
Kmeans(strata = strata2,
-
maxclusters = 10)
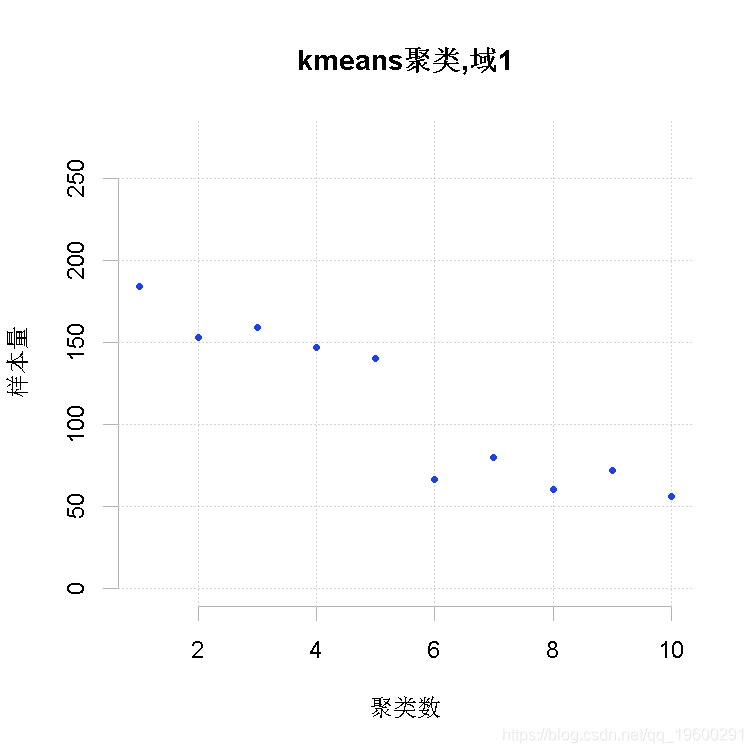
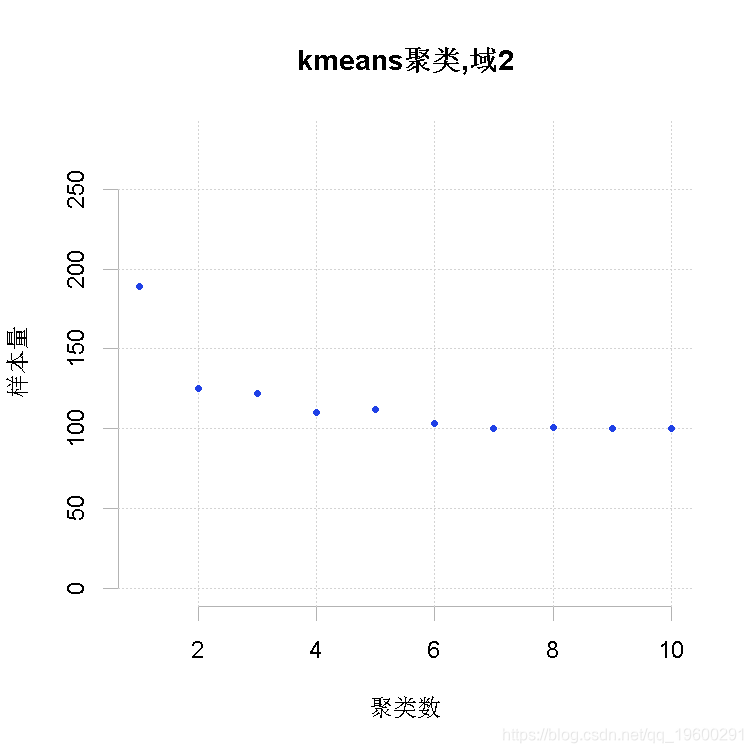
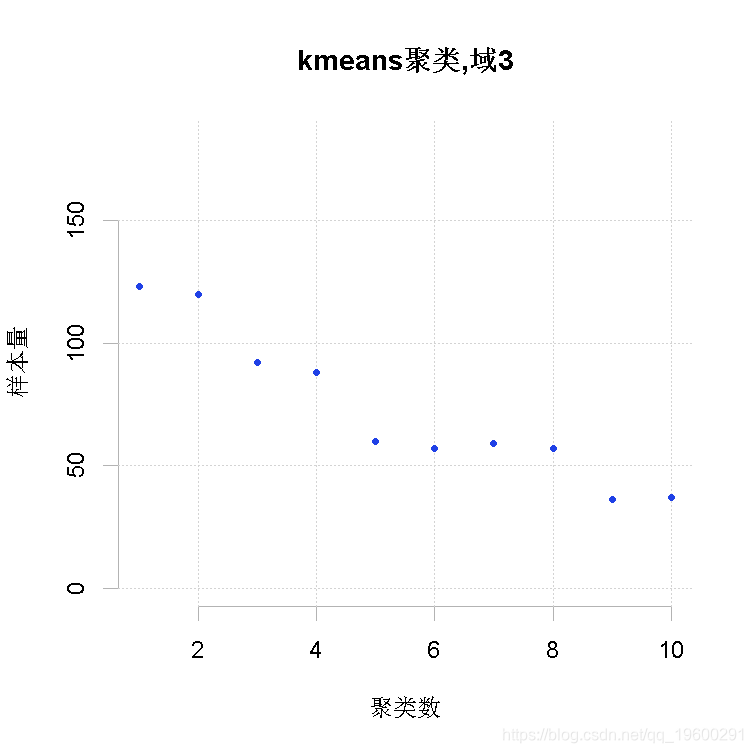
整体解决方案是通过串联各领域获得的最优聚类而获得的。其结果是一个有两列的数据框架:第一列表示聚类,第二列表示域。在此基础上,我们可以为每个域计算出最方便的最终层数。
-
apply(suggestions,
-
domainvalue,length(unique(x)))
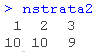
而我们可以提供初始解和层数nstrata作为优化步骤的输入。
-
Strata(
-
nStrata = nstrata2)
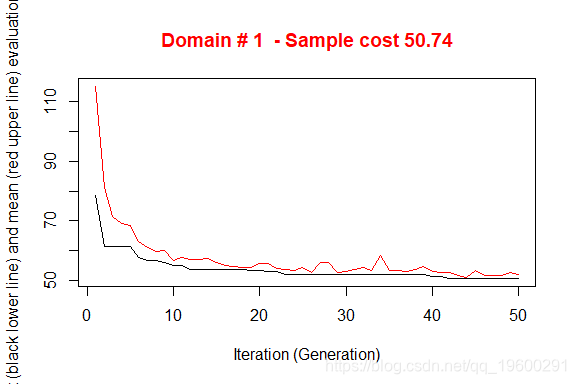
请注意,在这次运行中得到的解决方案在样本量方面明显优于前一次。
"连续"方法
最后要做的是测试连续方法。
首先,我们必须以这种方式重新定义框架dataframe。
-
FrameDF(
-
+ id = "市政编号",
-
+ X = c("总人口","建筑物面积"),
-
+ Y = c("有建筑物的区域","树林面积"),
-
+ value = "地区")
-
-
head(frame3)

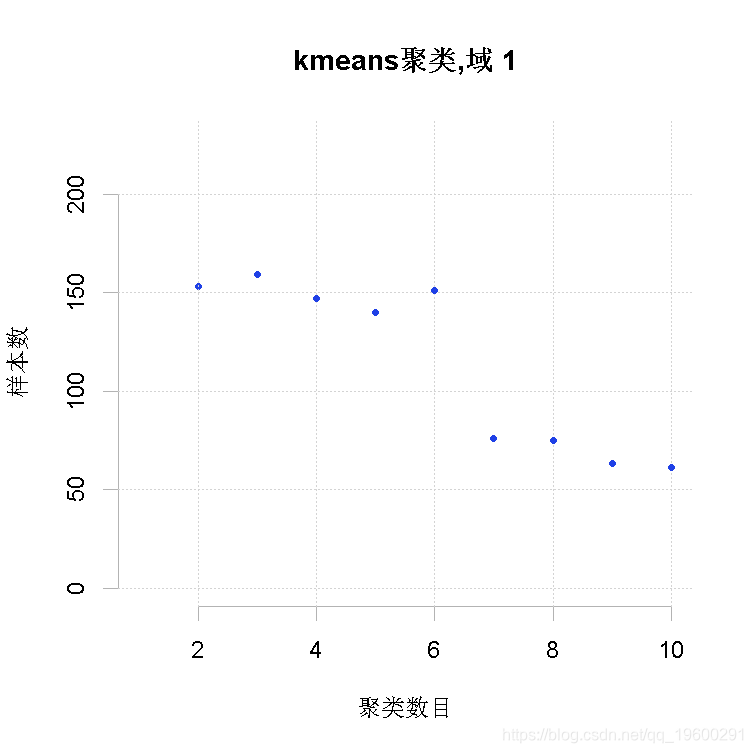
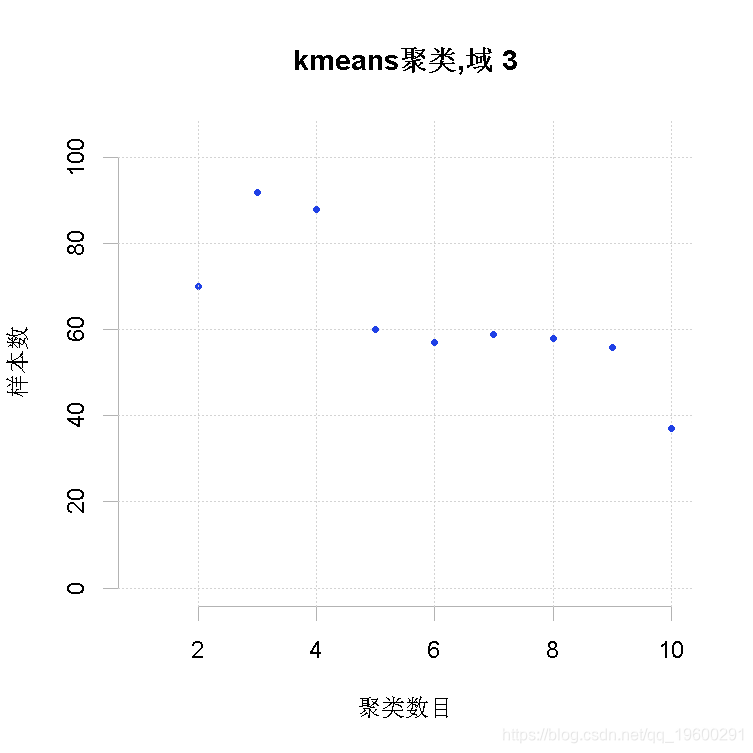
同样在这种情况下,我们想生成一个初始解决方案。
-
Kmeans2(frame=frame3,
-
maxclusters = 10)
-
apply(sugge,
-
value,
-
FUN=function(x) length(unique(x)))
-
![]()
请注意,这一次我们调用了一个不同的函数,它需要的不是阶层数据框架,而是直接的框架数据框架。此外,我们需要一个中间步骤为优化准备建议。
我们现在能够用连续方法进行优化步骤。

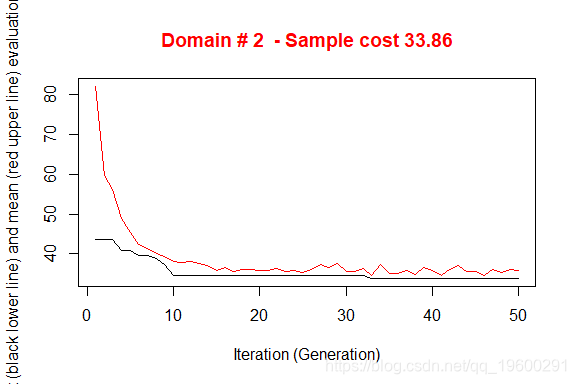
这个解决方案需要的总样本量是迄今为止我们制作的解决方案中最好的,所以我们决定选择这个方案。
分析
分层结构
执行的结果包含在由三个元素组成的 "解决方案 "列表中。
- indices: 指数向量,表示每个原子层属于哪个集合层(如果使用的是原子法)或者框架中的每个单元属于哪个集合层(如果使用的是连续法)。
- framenew: 更新的初始框架,对每个单元而言,表明每个单元所属的最佳层。
- aggr_strata: 包含优化层信息的数据框.
当分层变量为连续类型,并且使用了连续(或空间)方法时,有可能获得关于优化的分层结构的详细信息。
-
summaryStrata(framenew,
-
-
progress=FALSE)
-

对于每个优化的分层,报告了单位总数以及抽样率。还列出了分层变量的范围,描述各层的特点。
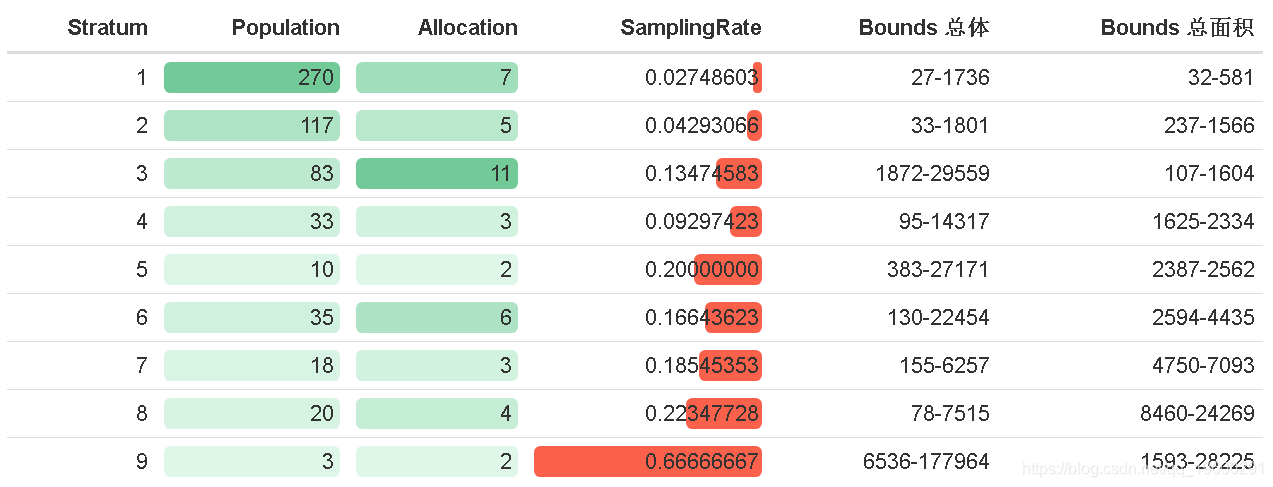
如果分层变量的数量有限,就像我们的情况一样,可以通过选择一对变量和每个时间段的一个域来可视化分层。
-
plot(framenew,
-
vars = c("X1","X2"),
-
labels = c("总体","总面积"))

通过模拟进行评估
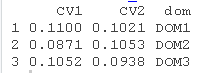
为了对找到的解决方案的质量有信心,我们运行一个模拟,基于从已确定为最佳分层的框架中选择所需数量的样本。用户可以指出要抽取的样本数量。
-
Solution(
-
nsampl = 200)
对于每个抽取的样本,都会计算与Y有关的估计值。它们的平均数和标准差也计算出来,得出每个领域中与每个变量相关的CV和相对偏差。
-
coeff_var
-
-
rel_bias
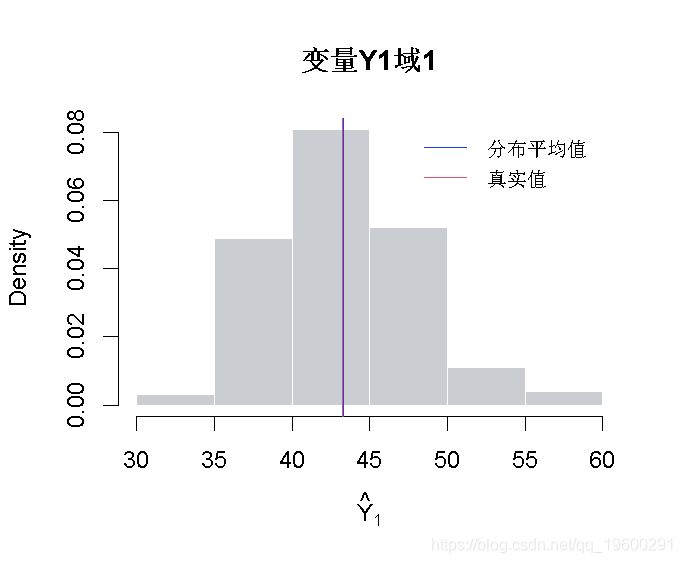
还可以分析所选域中每个相关变量的估计值的抽样分布。
-
-
hist(eval3 )
-
-
abline(v = mean(eval3$es )
-
abline(v = mean(frame3$Y )
最终样本大小的调整
在优化步骤之后,最终的样本量是最终分层中单位分配的结果。这种分配是为了使精度约束得到满足。实际上,可能会出现三种情况:
- 产生的样本量是可以接受的;
- 所得的样本量太多,也就是说,超过预算;
- 产生的样本量太少,可用的预算允许增加单位的数量。
在第一种情况下,不需要变化。在第二种情况下,有必要减少单位数,在每个分层中平均采用相同的减少率。在第三种情况下,我们着手增加样本量,在每个分层中应用相同的增加率。这个增加/减少的过程是反复进行的,因为通过应用相同的比率,我们可以发现在某些层没有足够的单位可以增加或减少。可以获得理想的最终样本量。
让我们假设最终获得的样本量(106)是超过预算。我们可以通过执行以下代码来减少它。
adjustSize(size=75,strata)
相反,如果我们想增加抽样样本规模,因为预算允许。

希望的样本量和实际调整后的样本量之间的差异取决于优化方案中的分层数量。考虑到在每个分层中进行调整时,要考虑到当前样本量与期望样本量之间的相对差异:这将产生一个用实数表示的分配,必须四舍五入,同时要考虑到分层中最小单位数的要求(默认为2)。层数越多,对最终调整后的样本量的影响就越大。
一旦增加(或减少)样本量,我们可以检查新的预期CV是多少。通过第二次调整,即增加了总的样本量,我们得到。
CV(adjusted)

即大大降低了期望CV。
样本选择
一旦获得最佳分层,就可以从优化版的框架中选择样本,同时考虑到最佳分层。
-
Sample(new3,
-
strata3,
-

在每个分层中进行简单的随机抽样。
一个变体是系统抽样 。唯一的区别是在每个分层中选择单位的方法,即通过执行以下步骤:
- 通过考虑分层中采样率的倒数确定选择区间;通过选择该区间中的一个值确定起点。
- 通过选择与上述数值相对应的单位作为第一个单位,然后选择所有加入选择区间而被分割的单位,进行选择。
如果与选择框架的特定排序相关联,这种选择方法是有用的,其中排序变量可以被视为额外的分层变量。例如,我们可以考虑市政当局的工业区(Airind)可能很重要。
Sample(variable = c("工业区"))

"全取 "分层抽样
作为优化步骤的输入,与适当的抽样分层一起,也可以提供 "全取 "分层。这些层不会像适当的层那样被优化,但是它们将有助于确定最佳分层,因为它们可以使较少的抽样层单位数量来满足精度约束。
为了正确执行优化和进一步的步骤,有必要对整个输入进行预处理。要执行的第一步是对要普查的单位和要抽样的单位进行两分法,以建立两个不同的框架。例如,我们要确保所有总人口超过10,000的城市都将被纳入抽样范围。因此,我们以这种方式划分抽样框架。
-
#----从框架中选择要进行普查的单位
-
nrow(which(X1 > 10000)
-
-
#----选择要从框架中取样的单位
-
#(对前者的补充)
-
nrow(rame3[-ind,])
![]()
![]()
这样,我们将所有人口超过10,000的单位定义为要进行普查。在这个过程结束时,样本将包含所有这些单位。
我们现在运行优化步骤,将待普查单位的指示包括在内。
-
set.seed(1234)
-
Strata(method = "continuous",
-
)

最受欢迎的见解
1.使用R语言进行METROPLIS-IN-GIBBS采样和MCMC运行
3.R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
4.R语言BUGS JAGS贝叶斯分析 马尔科夫链蒙特卡洛方法(MCMC)采样
5.R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
7.R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数