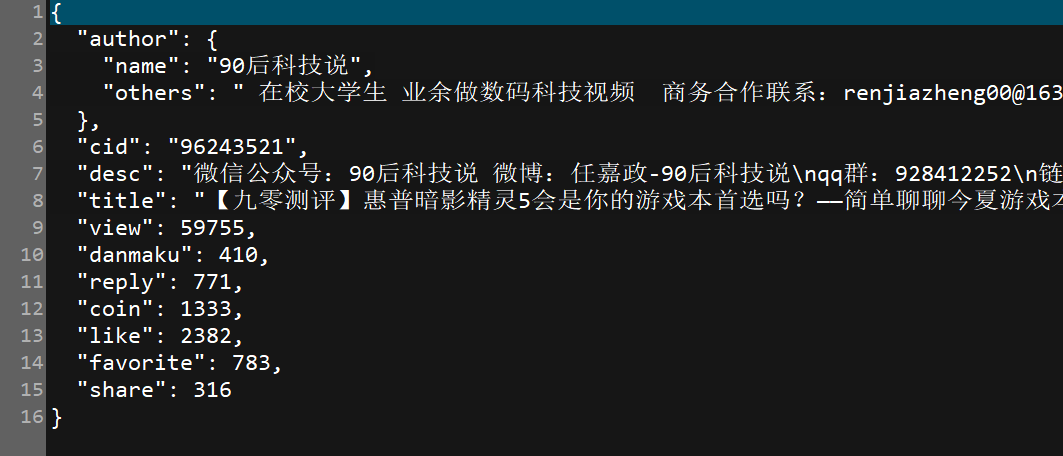
说明:
1.清晰度的选择要登录,暂时还没做,目前下载的视频清晰度都是默认的480P
2.进度条仿linux的,参考了一些博客修改了下,侵删
3.其他评论,弹幕之类的相关爬虫代码放在了https://github.com/teleJa/bilibili
4.判断sys.argv那个地方是因为一些爬虫调用了该文件,如果感觉不方面,直接传递视频番号进去就可以了
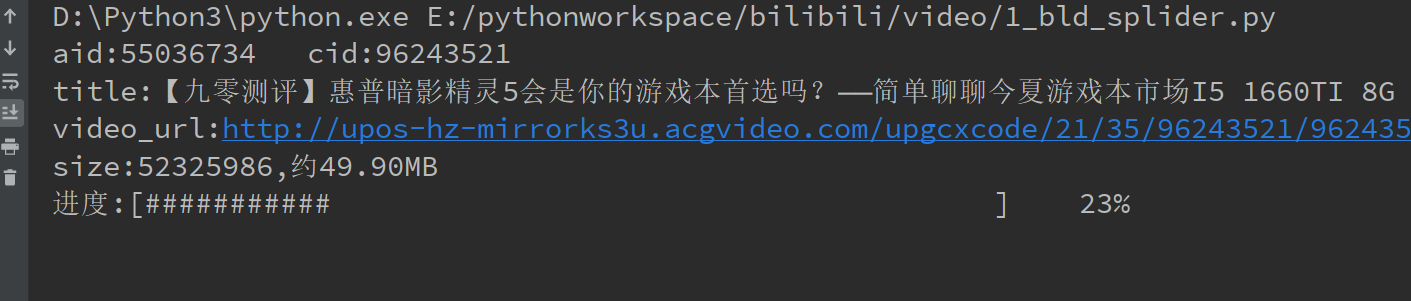
下载过程如图
直接上代码:
1 import requests
2 import re
3 import os
4 import json
5 import sys
6 import math
7 from lxml import etree
8
9
10 class BLDSplider:
11 regex_cid = re.compile(""cid":(.{8})")
12
13 def __init__(self, aid):
14 self.aid = aid
15
16 self.origin_url = "https://www.bilibili.com/video/av{}?from=search&seid=9346373599622336536".format(aid)
17 self.headers = {
18 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
19 }
20
21 self.url = "https://api.bilibili.com/x/player/playurl?avid={}&cid={}&qn=0&type=&otype=json"
22
23 def check_dir(self, author_name):
24 # 检查目录
25 self.parent_path = "e:/bilibili/" + author_name + "/" + str(self.aid) + "/"
26 if not os.path.exists(self.parent_path):
27 os.makedirs(self.parent_path)
28
29 self.video_name = self.parent_path + str(self.aid) + ".mp4"
30
31 def parse_url(self, item):
32 cid = item["cid"]
33 print("aid:%s cid:%s" % (str(self.aid), cid))
34 title = item["title"]
35 print("title:%s" % title)
36
37 self.headers["Referer"] = self.origin_url
38 # 视频
39 response = requests.get(self.url.format(self.aid, cid), headers=self.headers)
40 if response.status_code == 200:
41 result = json.loads(response.content.decode())
42 durl = result["data"]["durl"][0]
43 video_url = durl["url"]
44 print("video_url:%s" % video_url)
45 # 视频大小
46 size = durl["size"]
47 print("size:%s,约%2.2fMB" % (size, size / (1024 * 1024)))
48 video_response = requests.get(video_url, headers=self.headers, stream=True)
49 if video_response.status_code == 200:
50 with open(self.video_name, "wb") as file:
51 buffer = 1024
52 count = 0
53 while True:
54 if count + buffer <= size:
55 file.write(video_response.raw.read(buffer))
56 count += buffer
57 else:
58 file.write(video_response.raw.read(size % buffer))
59 count += size % buffer
60 file_size = os.path.getsize(self.video_name)
61 # print("
下载进度 %.2f %%" % (count * 100 / size), end="")
62
63 width = 50
64 percent = (count / size)
65 use_num = int(percent * width)
66 space_num = int(width - use_num)
67 percent = percent * 100
68 print('
进度:[%s%s] %d%%' % (use_num * '#', space_num * ' ', percent), file=sys.stdout,
69 flush=True, end="")
70 if size == count:
71 break
72 print("
")
73
74 # 获取视频相关参数
75 def get_video_info(self):
76 response = requests.get(self.origin_url, headers=self.headers)
77 item = dict()
78 if response.status_code == 200:
79 # author
80 html_element = etree.HTML(response.content.decode())
81 author = dict()
82 author_name = html_element.xpath(
83 "/html/body/div[@id='app']/div[@class='v-wrap']/div[@class='r-con']/div[@id='v_upinfo']//a[@report-id='name']/text()")[
84 0]
85 # 通常是微博,微信公众号等联系方式
86 author_others = html_element.xpath(
87 "/html/body/div[@id='app']/div[@class='v-wrap']/div[@class='r-con']/div[@id='v_upinfo']//div[@class='desc']/@title")[
88 0]
89 author["name"] = author_name
90 author["others"] = author_others
91 item["author"] = author
92
93 # cid
94 cid = BLDSplider.regex_cid.findall(response.content.decode())[0]
95 item["cid"] = cid
96 info_url = "https://api.bilibili.com/x/web-interface/view?aid={}&cid={}".format(self.aid, cid)
97 info_response = requests.get(info_url, headers=self.headers)
98 if info_response.status_code == 200:
99 data = json.loads(info_response.content.decode())["data"]
100 # 视频简介
101 desc = data["desc"]
102 item["desc"] = desc
103
104 # title
105 title = data["title"]
106 item["title"] = title
107
108 stat = data["stat"]
109 # 播放量
110 view = stat["view"]
111 item["view"] = view
112
113 # 弹幕
114 danmaku = stat["danmaku"]
115 item["danmaku"] = danmaku
116
117 # 评论
118 reply = stat["reply"]
119 item["reply"] = reply
120
121 # 硬币
122 coin = stat["coin"]
123 item["coin"] = coin
124
125 # 点赞
126 like = stat["like"]
127 item["like"] = like
128
129 # 收藏
130 favorite = stat["favorite"]
131 item["favorite"] = favorite
132
133 # 分享
134 share = stat["share"]
135 item["share"] = share
136 self.check_dir(item["author"]["name"])
137 # 视频参数
138 with open(self.parent_path + "video_info.txt", "w") as file:
139 file.write(json.dumps(item, ensure_ascii=False, indent=2))
140 return item
141
142 def run(self):
143 item = self.get_video_info()
144 self.parse_url(item)
145
146
147 def main():
148 # 55036734
149 aid = 55036734
150 if len(sys.argv) >= 2:
151 if sys.argv[1]:
152 aid = sys.argv[1]
153 splider = BLDSplider(aid)
154 splider.run()
155
156
157 if __name__ == '__main__':
158 main()