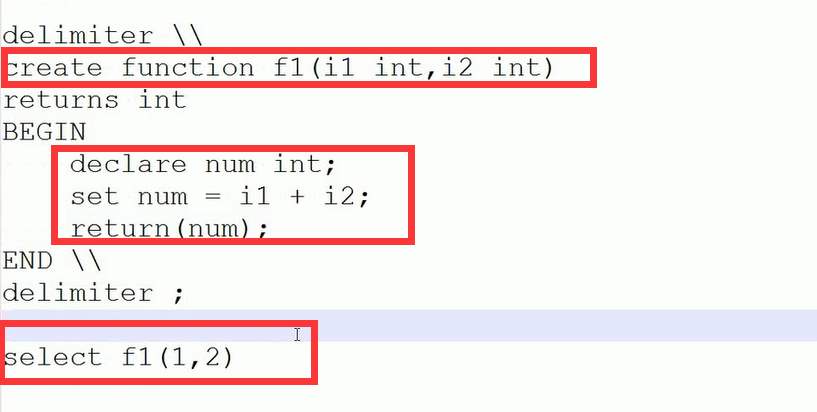
delimiter \ create PROCEDURE p1( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; DELETE from tb1; insert into tb2(name)values('seven'); COMMIT; -- SUCCESS set p_return_code = 0; END\ delimiter ;
set @i =0;
call p1(@i);select @i; #事物执行的结果也是 和存储一样的。mysql 内置函数
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: '12,332.1000' INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5); -> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4); -> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6); -> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3); -> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3); -> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2); -> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar '); -> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx'); -> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx'); -> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz'); -> 'barx' 部分内置函数

更正下 删除普通的索引
drop index id_score_num on score;
1、普通索引
create index 索引名称 on 表(列名)
2、唯一索引
create unique index
3、主键索引
- 不能重复,不能null
4、组合索引
name,pwd
- 普通组合索引:
无约束
name,pwd
- 联合唯一索引:
有约束,两列数据同时不相同,才能插入,不然报错
name,pwd
查找:最左匹配
select * from tb1 where name = 'alex'
select * from tb1 where name = 'alex' and pwd='123'
select * from tb1 where pwd='123' # 不会走索引
查找:最左匹配
name,pwd,email
select * xx where name ='alex'
select * xx where pwd ='alex'
select * xx where email ='alex'
select * xx where name='alex' and pwd='xx'
select * from tb where nid=1
# 先去索引中找,
# 在去数据表找
select nid from tb where nid < 10
# 先去索引中找
-- 情况应用上索引,并且不用去数据表中操作,覆盖索引0
-- 只需要在索引表中就能获取到数据时,
2、合并索引
nid name(单独索引) email(单独索引) pwd
select * from tb where name='alex'
select * from tb where email='alex3714@163.com'
select * from tb where name='alex' or email='alex3714@163.com'
nid name(组) email(合) pwd
# 最左前缀
select * from tb where name='alex'
select * from tb where email='alex3714@163.com' ########无法满足########
select * from tb where name='alex' or email='alex3714@163.com'
用户表:
nid username(组) password(合)
1 alex 123
2 shaogbing 123
select * from tb where username='xx' and password='xx'
select * from tb where username='xx'
# select * from tb where password='xx'
--> 组合和合并索引取舍?业务需求来决定
3、执行计划 - 相对比较准确表达出当前SQL运行状况
是否走索引,不走索引
explain SQL语句
1、explain SQL语句
type: ALL - 全数据表扫描
type: index - 全索引表扫面
2、limit
select * from tb1 where email='123'
select * from tb1 where email='123' limit 1;
-----SQL: ALL、Index,都是有优化的余地 -------
4、如何命中索引
nid name ctime
2016-9-10 11:59
当前时间:
2016/9/10
select * from tb1 where conv(ctime,'.,..') = time;
# 转船
select * from tb1 where ctime = 转(2016/9/10)=> 2016-9-10
5、分页
limit x,m : 表x+m
where nid>10000 直接跳过 钱10000条数,继续往下扫
每页:10条
1 2 3 4 ... 18 19 20 21
1 17 31 45
16 29 42 90
-- nid排列可能中断的
---------- 方式: 上一页下一页 ----------
1、当用查看页面时,第一页 limit 0,10: nid: 1 - 16
2、第一页 limit 10,10: nid: 17 - 36
3、第一页 limit 100000,10: nid: 17 - 36
2、第一页 where nid>16 limit 10: nid: 17 - 36
3、第一页 where nid>36 limit 10: nid: 170 - 360