1 Scrapy 爬虫模拟登陆策略
前面学习了爬虫的很多知识,都是分析 HTML、json 数据,有很多的网站为了反爬虫,除了需要高可用代理 IP 地址池外,还需要登录,登录的时候不仅仅需要输入账户名和密码,而且有可能验证码,下面就介绍 Scrapy 爬虫模拟登陆的几种策略。
1.1 策略一:直接POST请求登录
前面介绍的爬虫 scrapy 的基本请求流程是 start_request 方法遍历 start_urls 列表,然后 make_requests_from_url方法,里面执行 Request 方法,请求 start_urls 里面的地址,使用的是 GET 方法,由于直接使用用户名和密码可以登录,使用 POST 方法进行登录。
例子:人人网登录
登录地址:http://www.renren.com/PLogin.do
案例步骤:
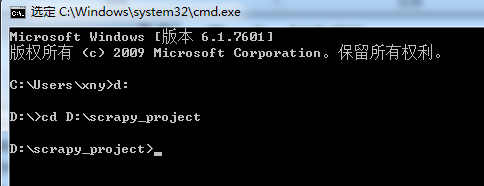
第一步:创建项目。
在 dos下切换到目录
D:scrapy_project
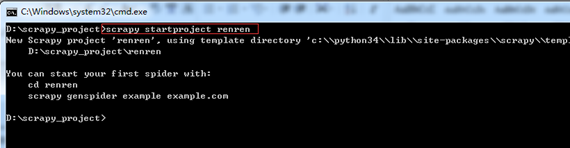
新建一个新的爬虫项目:scrapy startproject renren
第二步:创建爬虫。
在 dos下切换到目录。
D:scrapy_project enren enrenspiders
用命令 scrapy genspider renren1 " renren.com" 创建爬虫。
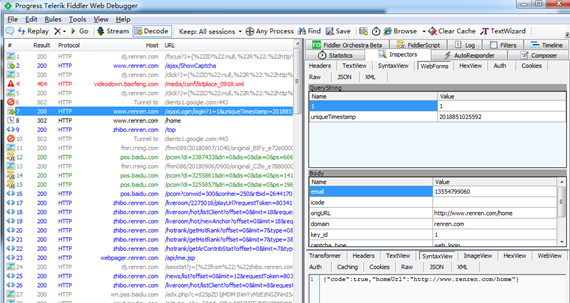
第三步: 通过浏览器登录人人网,使用 fiddler 抓包抓取登录 post 请求的 data。
第四步:编写爬虫文件。
import scrapy
# 登录只需要提供 post 数据就可以登录的,就可以用这种方法,
# 下面示例:post 数据是账户密码
class Renren1Spider(scrapy.Spider):
name = "renren1"
allowed_domains = ["renren.com"]
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'
# FormRequest 是 Scrapy 发送 POST 请求的方法
yield scrapy.FormRequest(
url = url,
formdata = {"email" : "13554799060", "password" : "xny123"},
callback = self.parse_page)
# 回调方法,对返回的 response 进行处理(把response.body保存到 xiao.html 中)
def parse_page(self, response):
with open("xiao.html", "wb") as filename:
filename.write(response.body)
第五步:修改 settings 文件。
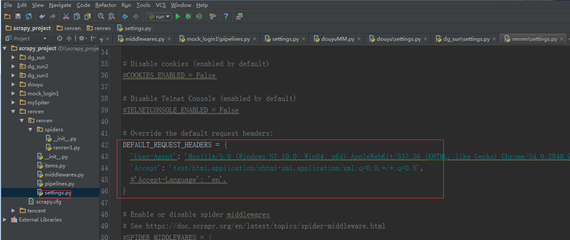
设置爬虫请求的默认头信息。
第六步:运行爬虫。
在 dos下切换到目录
D:scrapy_project enren enren 下
通过命令运行爬虫 :scrapy crawl renren1
第七步:查看结果。
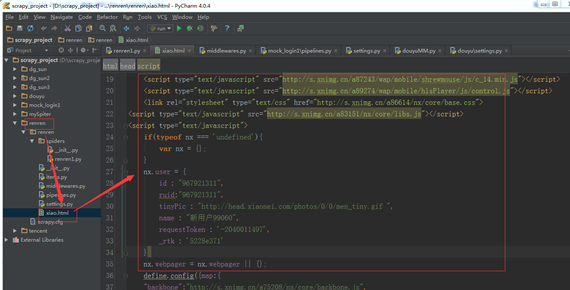
xiao.html 中显示的内容正是登录自己人人网之后的主页内容,说明登录成功。
1.2 策略二:标准的模拟登陆
标准的模拟登录方法:
1、首先发送登录页面的 get 请求,获取到页面里的登录必须的参数。
2、登录必须的参数和账户密码一起 post 到服务器,登录成功。
23.2.1 Cookie原理
HTTP 是无状态的面向连接的协议, 为了保持连接状态, 标准的模拟登陆案例引入了 Cookie 机制。
Cookie 是 http 消息头中的一种属性,包括:
.Cookie 名字(Name)Cookie 的值(Value)
.Cookie 的过期时间(Expires/Max-Age)
.Cookie 作用路径(Path)
.Cookie 所在域名(Domain),使用 Cookie 进行安全连接(Secure)。
前两个参数是 Cookie 应用的必要条件,另外,还包括 Cookie 大小( Size,不同浏览器对Cookie 个数及大小限制是有差异的 )。
23.2.2 模拟登陆
爬取的网站:github (https://github.com/login)
案例步骤:
第一步:爬取前分析。
打开 fiddler,接着我们打开 github 的登陆页面(https://github.com/login ),输入用户名、密码( 输入错误的密码 ),提交查看 fiddler 获取的信息,结果入下:
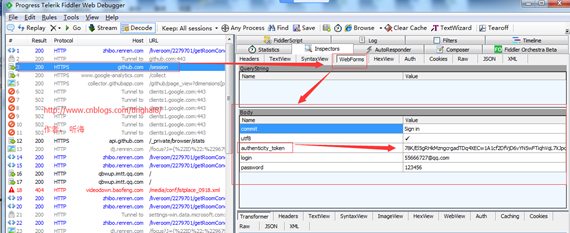
输入用户名和错误密码获取的 fiddler 结果:
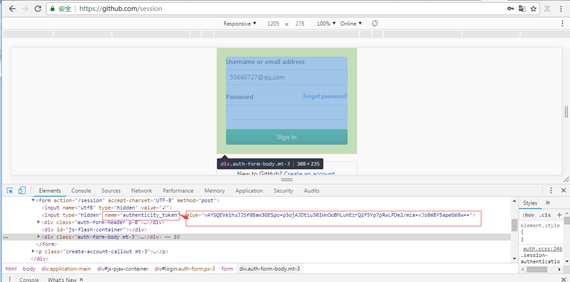
我们用 google 浏览器看源码也可以看到 form 提交时会加入 authenticity_token 参数一起,如下图:
第二步:创建项目。
在 dos下切换到目录
D:scrapy_project
新建一个新的爬虫项目:scrapy startproject github

第三步:创建爬虫。
在 dos下切换到目录。
D:scrapy_projectgithubgithubspiders
用命令 scrapy genspider gh "github.com" 创建爬虫。
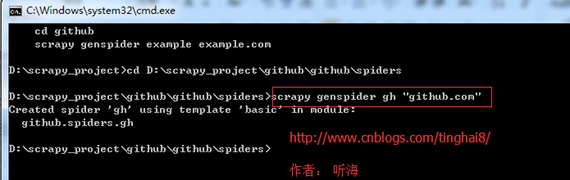
第四步: 开始前的准备工作。
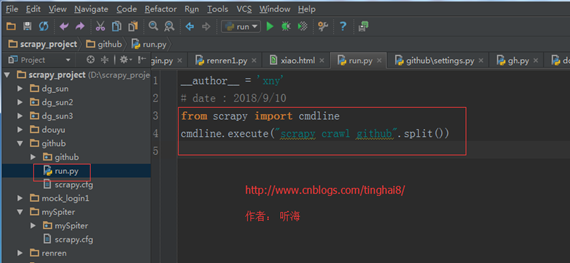
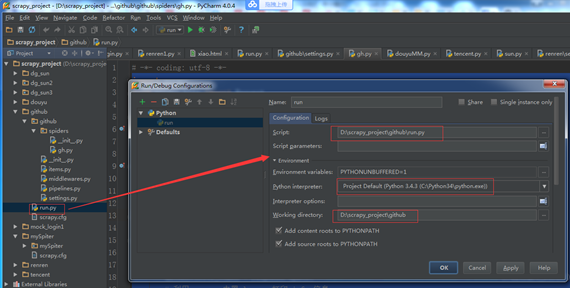
(一)、在 scrapy.cfg 同级目录下创建 pycharm 调试脚本 run.py,内容如下:
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl github".split())
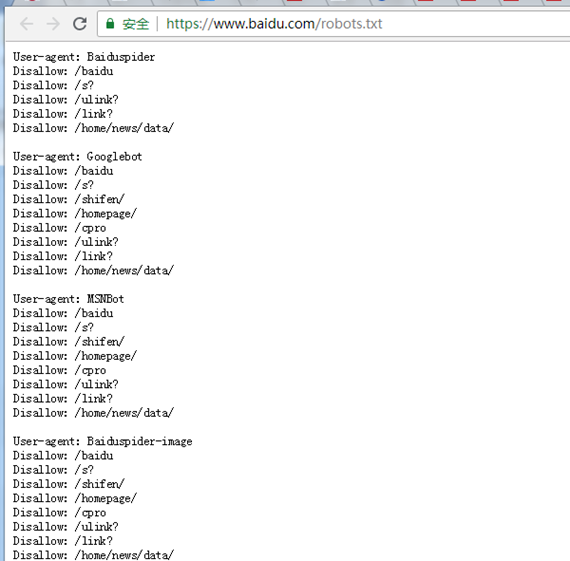
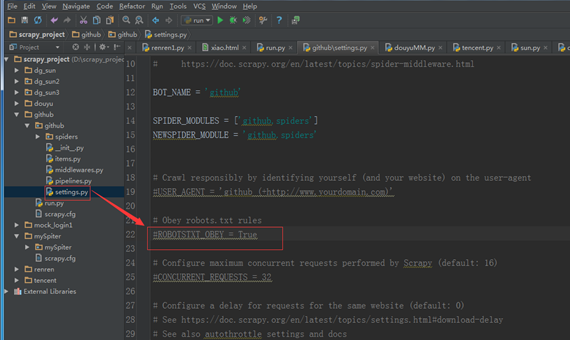
(二)修改 settings 中的 ROBOTSTXT_OBEY = True 参数为 False,因为默认为 True,就是要遵守 robots.txt 的规则, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在 Scrapy 启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。查看 robots.txt 可以直接网址后接 robots.txt 即可。
例如百度:https://www.baidu.com/robots.txt
修改 settings 文件。
(三)模拟登陆时,必须保证 settings.py 里的 COOKIES_ENABLED (Cookies中间件) 处于开启状态。
COOKIES_ENABLED = True
第五步:编写爬虫文件-获取 authenticity_token。
首先要打开登陆页面,获取 authenticity_token,代码如下:
import scrapy
class GithubSpider(scrapy.Spider):
name = 'gh'
allowed_domains = ['github.com']
def start_requests(self):
urls = ['https://github.com/login']
for url in urls:
# 重写 start_requests 方法,通过 meta 传入特殊 key cookiejar,爬取 url 作为参数传给回调函数
yield scrapy.Request(url, meta={'cookiejar': 1}, callback=self.github_login)
def github_login(self, response):
# 首先获取authenticity_token,这里可以借助scrapy shell ”url“来获取页面
# 然后从源码中获取到authenticity_token的值
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
# 利用 scrapy 内置 logger 打印 info 信息
self.logger.info('authenticity_token='+ authenticity_token)
pass
运行结果:
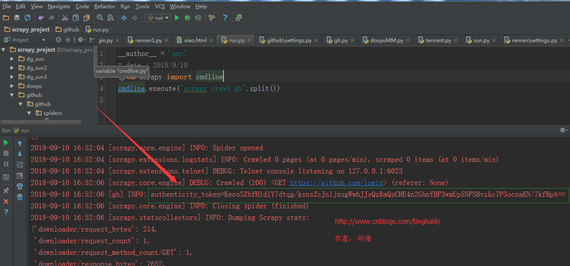
通过运行的结果,可以看到我们已经获取了 authenticity_token 的值,这一步重点要说明meta、cookiejar 和 logger。
【meta】:字典格式的元数据,可以传递给下一个函数 meta。
【cookiejar】:是 meta 的一个特殊的key,通过 cookiejar 参数可以支持多个会话对某网站进行爬取,可以对 cookie 做标记,1,2,3,4......这样 scrapy 就维持了多个会话;
【logger】:scrapy 为每个 spider 实例内置的日志记录器。
为了能使用同一个状态持续的爬取网站, 就需要保存cookie, 使用cookie保存状态, Scrapy 提供了 cookie 处理的中间件, 可以直接拿来使用,Scrapy 官方的文档中给出了下面的代码范例 :
for i, url in enumerate(urls):
yield scrapy.Request("http://www.example.com", meta={'cookiejar': i},
callback=self.parse_page)
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
第六步:修改爬虫文件- FormRequest(登录表单提交)
Scrapy 提供了 FormRequest 类,是 Request 类的扩展,专门用来进行 Form 表单提交。我们主要使用 FormRequest.from_response()方法来模拟简单登陆,通过FormRequest.from_response 提交后,交给回调函数处理。代码如下:
import scrapy
class GithubSpider(scrapy.Spider):
name = 'gh'
allowed_domains = ['github.com']
def start_requests(self):
urls = ['https://github.com/login']
for url in urls:
# 重写 start_requests 方法,通过 meta 传入特殊 key cookiejar,爬取 url 作为参数传给回调函数
yield scrapy.Request(url, meta={'cookiejar': 1}, callback=self.github_login)
def github_login(self, response):
# 首先获取authenticity_token,这里可以借助scrapy shell ”url“来获取页面
# 然后从源码中获取到authenticity_token的值
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
# 利用 scrapy 内置 logger 打印 info 信息
self.logger.info('authenticity_token='+ authenticity_token)
# url 可以从 fiddler 抓取中获取,dont_click 作用是如果是 True,表单数据将被提交,而不需要单击任何元素。
return scrapy.FormRequest.from_response(
response,
url='https://github.com/session',
meta = {'cookiejar': response.meta['cookiejar']},
headers = self.headers,
formdata = {'utf8':'?',
'authenticity_token': authenticity_token,
'login': 'xxxxxx@qq.com',
'password': 'xxxxxx'},
callback = self.github_after,
dont_click = True,
)
第七步:修改爬虫文件- 伪装头部。
为了更真实的模拟浏览器登陆网站,需要进行头部伪装, 在 scrapy 中 Request 和 FormRequest 初始化的时候都有一个 headers 字段, 可以自定义头部, 这样我们可以添加 headers 字段。
# 头信息直接从 fiddler 中复制出来
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "https: // github.com /",
"Content - Type": "application / x - www - form - urlencoded",
}
第八步:修改爬虫文件- 增加回调函数,主要是登陆成功之后,获取登录之后返回的页面(response)的元素进行断言,验证登录结果。
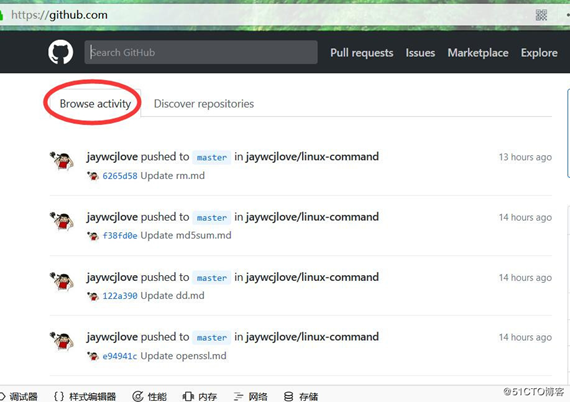
登录之后,主页如下:
# 回调函数
def github_after(self, response):
# 获取登录页面主页中的字符串'Browse activity'
list = response.xpath("//a[@class=‘tabnav-tab selected‘]/text()").extract()
# 如果含有字符串,则打印日志说明登录成功
if 'Browse activity' in list:
self.logger.info('我已经登录成功了,这是我获取的关键字:Browse activity')
else:
self.logger.error('登录失败')
第九步:整理完整的爬虫文件
import scrapy
class GithubSpider(scrapy.Spider):
name = 'gh'
allowed_domains = ['github.com']
# 头信息直接从 fiddler 中复制出来
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
"Referer": "https: // github.com /",
"Content - Type": "application / x - www - form - urlencoded",
}
def start_requests(self):
urls = ['https://github.com/login']
for url in urls:
# 重写 start_requests 方法,通过 meta 传入特殊 key cookiejar,爬取 url 作为参数传给回调函数
yield scrapy.Request(url, meta={'cookiejar': 1}, callback=self.github_login)
def github_login(self, response):
# 首先获取authenticity_token,这里可以借助scrapy shell ”url“来获取页面
# 然后从源码中获取到authenticity_token的值
authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first()
# 利用 scrapy 内置 logger 打印 info 信息
self.logger.info('authenticity_token='+ authenticity_token)
# url 可以从 fiddler 抓取中获取,dont_click 作用是如果是 True,表单数据将被提交,而不需要单击任何元素。
return scrapy.FormRequest.from_response(
response,
url='https://github.com/session',
meta = {'cookiejar': response.meta['cookiejar']},
headers = self.headers,
formdata = {'utf8':'?',
'authenticity_token': authenticity_token,
'login': '55666727@qq.com',
'password': 'xny8816056'},
callback = self.github_after,
dont_click = True,
)
# 回调函数
def github_after(self, response):
# 获取登录页面主页中的字符串'Browse activity'
list = response.xpath("//a[@class=‘tabnav-tab selected‘]/text()").extract()
# 如果含有字符串,则打印日志说明登录成功
if 'Browse activity' in list:
self.logger.info('我已经登录成功了,这是我获取的关键字:Browse activity')
else:
self.logger.error('登录失败')
第十步:查看运行的结果。
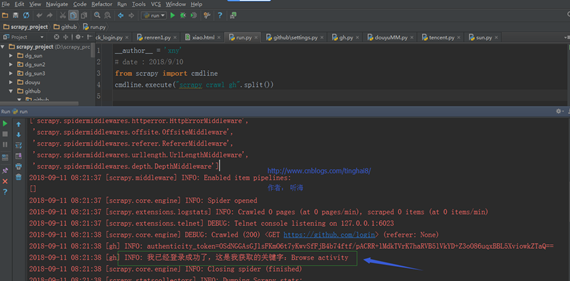
通过运行的结果说明登录成功。
1.3 策略三:直接使用保存登陆状态的 Cookie 模拟登陆
如果实在没办法了,可以用策略三这种方法模拟登录,虽然麻烦一点,但是成功率100%。
案例步骤:
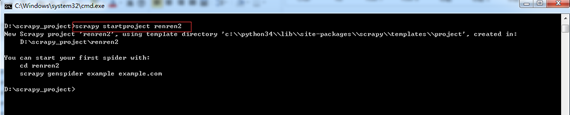
第一步:创建项目。
在 dos下切换到目录
D:scrapy_project
新建一个新的爬虫项目:scrapy startproject renren2
第二步:创建爬虫。
在 dos下切换到目录。
D:scrapy_project enren2 enren2spiders
用命令 scrapy genspider ren2 "renren.com" 创建爬虫。
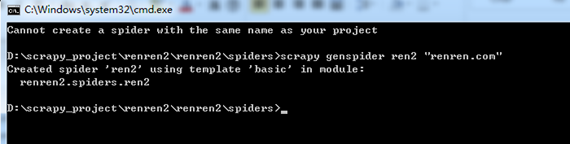
第三步: 通过浏览器登录人人网,使用 fiddler 抓包抓取登录后的Cookis。
第四步: 开始前的准备工作。
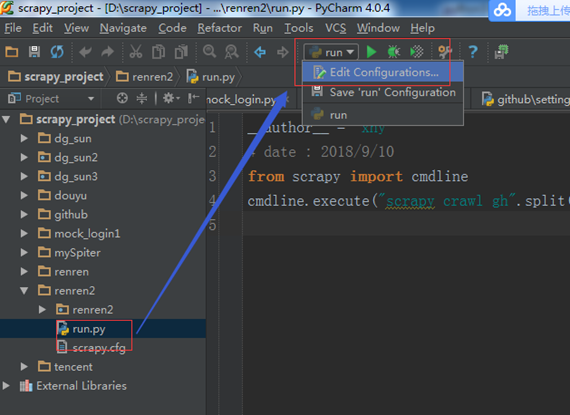
(一)、在 scrapy.cfg 同级目录下创建 pycharm 调试脚本 run.py,内容如下:
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl renren".split())
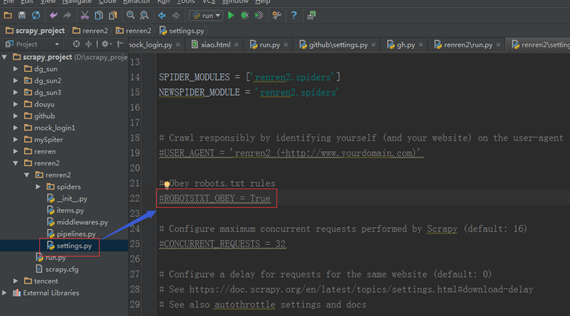
(二)修改 settings 中的 ROBOTSTXT_OBEY = True 参数为 False,因为默认为 True,就是要遵守 robots.txt 的规则, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在 Scrapy 启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。查看 robots.txt 可以直接网址后接 robots.txt 即可。
修改 settings 文件。
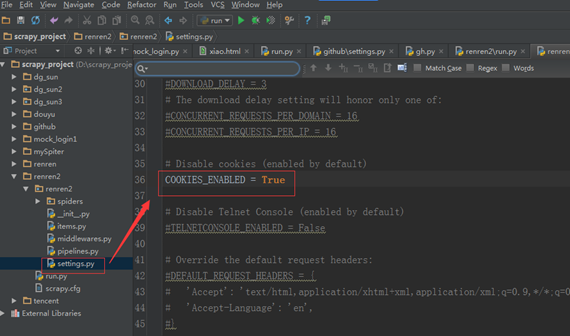
(三)模拟登陆时,必须保证 settings.py 里的 COOKIES_ENABLED ( Cookies 中间件) 处于开启状态。
COOKIES_ENABLED = True
第五步: 编写爬虫文件。
import scrapy
class RenrenSpider(scrapy.Spider):
name = "renren"
allowed_domains = ["renren.com"]
Cookies = {
"anonymid": "jlvxr345k9ondn",
"wp_fold": "0",
"depovince": "GW",
"jebecookies": "3af719cc-f819-4493-bcb6-c967fc59f04a|||||",
"_r01_": "1",
"JSESSIONID": "abcwnUubDsWO467i0mgxw",
"ick_login":"27af5597-30d7-469c-b7c4-184a6e335fcb",
"jebe_key":"d1f5682d-03b4-46cd-87c0-dc297525ed11%7Ccfcd208495d565ef66e7dff9f98764da%7C1536628574466%7C0%7C1536628572944",}
# 可以重写 Spider 类的 start_requests 方法,附带 Cookie 值,发送 POST 请求
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'
# FormRequest 是 Scrapy 发送 POST 请求的方法
yield scrapy.FormRequest(url, cookies = self.Cookies, callback = self.parse_page)
# 处理响应内容
def parse_page(self, response):
print("===========" + response.url)
with open("xiao2.html", "wb") as filename:
filename.write(response.body)
第六步: 运行程序,查看运行结果。
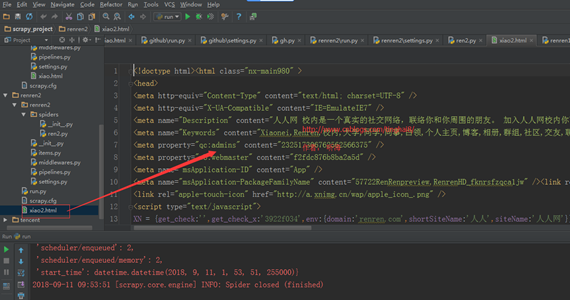
Xiao2.html 中显示的内容正是登录自己人人网之后的主页内容,说明登录成功。
----------------------------------
个人今日头条账号: 听海8 (上面上传了很多相关学习的视频以及我书里的文章,大家想看视频,可以关注我的今日头条)
