1.GPU
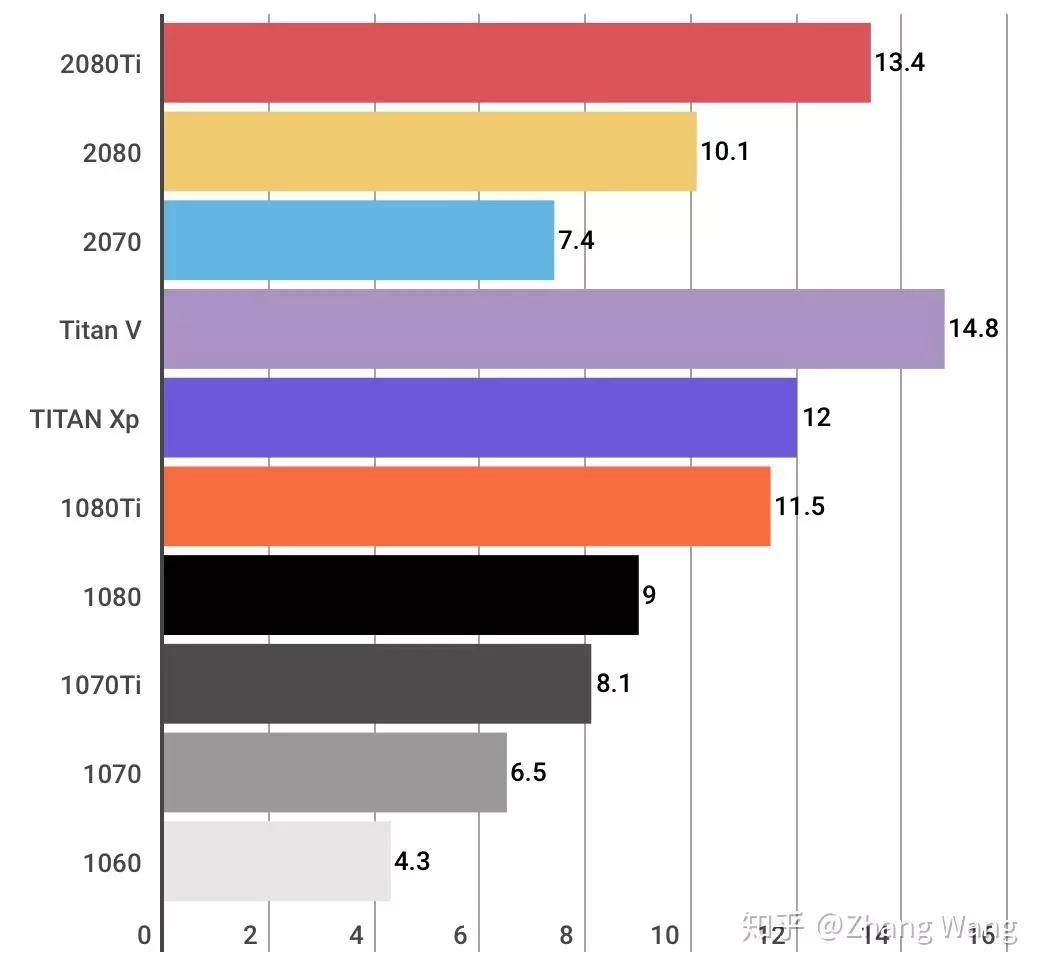
TFLOPS(teraFLOPS FLoating-point Operations Per Second每秒浮点运算次数)单精度也就是运算性能,决定了运算速度,首选1080ti、2080ti、Titan V,不过性能最强的titan V的价格是2080ti的三倍
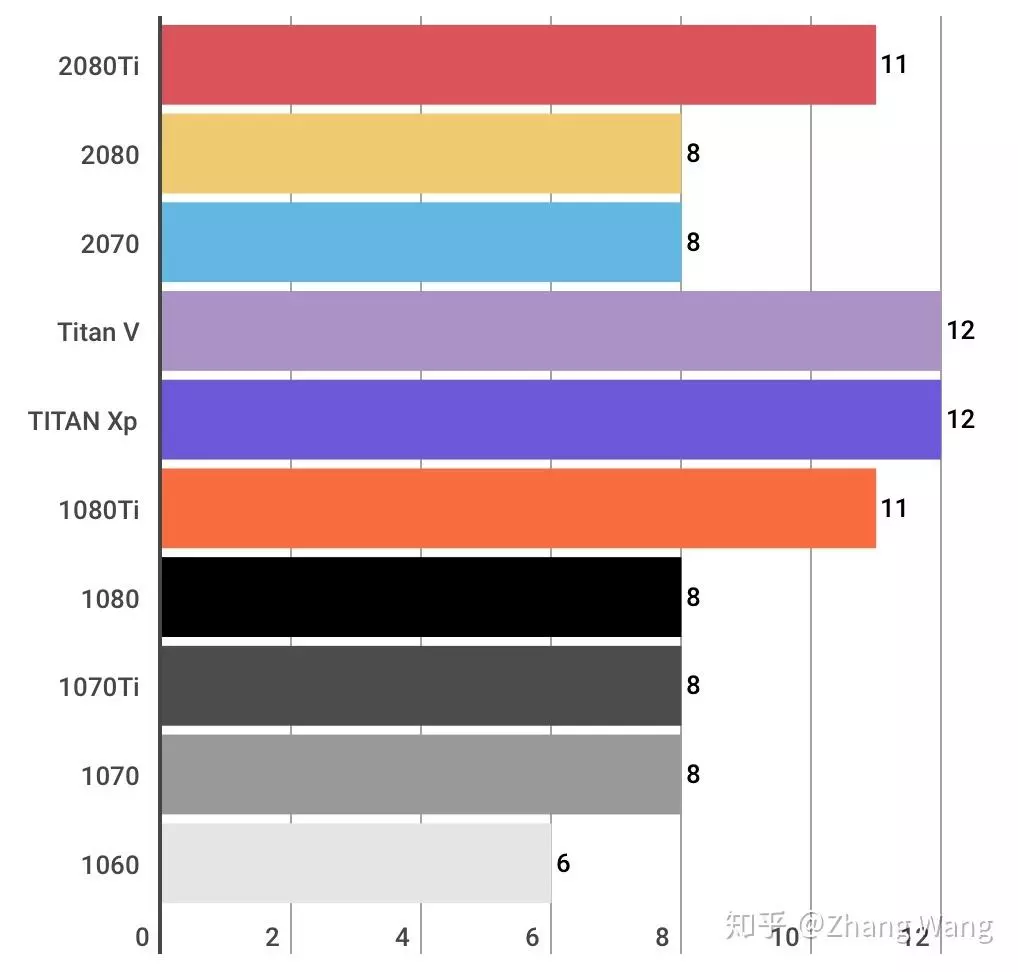
VRAM(显存):显存大小决定了我们的网络模型能不能执行,大型的卷积神经网络会使用超过8G以上的显存,因此购买具有大显存的显卡才能够保证大多数卷积神经网络模型能够顺利执行。
其中1080ti具有11G显存,能胜任较大的网络模型,性能也比较强,售价大约5000元一张具有最高的性价比。
2080ti是最新的显卡,同样拥有11G显存,但速度是1080TI的1.5倍,售价大约9000元。
Titan V具有12G显存,可以说能够执行绝大多数网络,并且速度是最快的,由于是面向商用,所以其价格也非常感人,约25000元一块。
这三款较为适合深度学习图像处理任务,能完成大多数网络,可以根据预算自由选择。8G显存和6G显存的1080和1060也不失为信价比之选,但是考虑到显存的限制,还是尽量购买具有11G以上的显存的显卡。
2.CUDA和cuDNN
CUDA(ComputeUnified Device Architecture)是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。也就是说CUDA只能在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。CUDA的主要作用是链接 GPU 和 应用程序,方便用户通过 CUDA 的 API 调度 GPU 进行计算。
cuDNN(CUDA Deep Neural Network library)是NVIDIA基于CUDA打造的针对深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。它能将模型训练的计算优化之后,再通过 CUDA 调用 GPU 进行运算。当然你也可直接使用CUDA,而不通过 cuDNN ,但运算效率会低好多。
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN相当于工具,比如扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
从官方安装指南可以看出,只要把cuDNN文件复制到CUDA的对应文件夹里就可以,即是所谓插入式设计,把cuDNN数据库添加CUDA里,cuDNN是CUDA的扩展计算库,不会对CUDA造成其他影响。
3.查询当前显卡最新的驱动版本
https://www.nvidia.com/Download/index.aspx
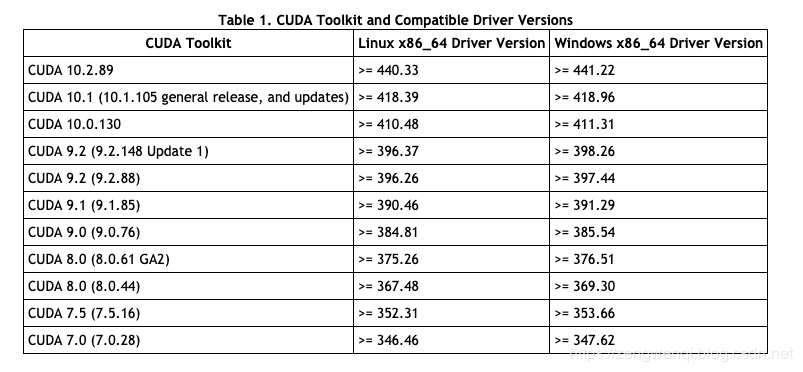
4.显卡驱动版本与CUDA版本对应关系
5.查询显卡的算力(GPU Compute Capability)
https://developer.nvidia.com/cuda-gpus
6.查看CUDA和cuDNN版本
Linux
nvcc --version
或
nvcc -V
如果 nvcc 没有安装,采用下面的方法:
cat /usr/local/cuda/version.txt cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
Windows
nvcc --version
或者进入 CUDA 的安装目录查看:
C:Program FilesNVIDIA GPU Computing ToolkitCUDA
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv9.0includecudnn.h
如下所示,cuDNN 版本为 7.2.1 :
