!mkdir '/content/gdrive/My Drive/conversation'
''' 将文本句子分解成单词,并构建词库 ''' path = '/content/gdrive/My Drive/conversation/' with open(path + 'question.txt', 'r') as fopen: text_question = fopen.read().lower().split(' ') with open(path + 'answer.txt', 'r') as fopen: text_answer = fopen.read().lower().split(' ') concat_question = ' '.join(text_question).split() vocabulary_size_question = len(list(set(concat_question))) data_question, count_question, dictionary_question, rev_dictionary_question = build_dataset(concat_question, vocabulary_size_question) print('vocab question size: %d' %(vocabulary_size_question)) #前4个单词有控制功能,具有含义的单词从编号4开始 print('Most common words:', count_question[4:10]) print('Sample data: ', data_question[:10], [rev_dictionary_question[i] for i in data_question[:10]]) path = '/content/gdrive/My Drive/conversation/' with open(path + 'question.txt', 'r') as fopen: text_question = fopen.read().lower().split(' ') with open(path + 'answer.txt', 'r') as fopen: text_answer = fopen.read().lower().split(' ') concat_answer = ' '.join(text_answer).split() vocabulary_size_answer = len(list(set(concat_answer))) data_answer, count_answer, dictionary_answer, rev_dictionary_answer = build_dataset(concat_answer, vocabulary_size_answer) print('vocab answer size: %d' %(vocabulary_size_answer)) #前4个单词有控制功能,具有含义的单词从编号4开始 print('Most common words:', count_answer[4:10]) print('Sample data: ', data_answer[:10], [rev_dictionary_answer[i] for i in data_answer[:10]]) l = [dictionary_question['how'], dictionary_question['are'], dictionary_question['you']] print(l) l = [dictionary_answer['i'],dictionary_answer['am'], dictionary_answer['fine']] print(l)

GO = dictionary_question['GO'] PAD = dictionary_question['PAD'] EOS = dictionary_question['EOS'] UNK = dictionary_question['UNK'] import tensorflow as tf
''' tf.strided_slice(input, begin, end, stride), 对向量进行切片begin表示切片的起始位置, end-1为切片的结束位置 ''' data = [1,2,3,4,5,6,7,8] #从下标0开始到下标为5的元素作为切片,每隔一个元素切一刀 x = tf.strided_slice(data, [0], [6], [1]) with tf.Session() as sess: print('begin: 0, end: 6, stride: 1: ', sess.run(x)) #从0开始到下标为5的元素范围内,每隔两个元素切一刀 x = tf.strided_slice(data, [0], [6], [2]) with tf.Session() as sess: print('begin: 0, end: 6, stride: 2: ', sess.run(x)) #end可以是负数,表示倒数第几个元素,例如-1表示最后一个元素,-2表示倒数第二个元素 x = tf.strided_slice(data, [2], [-2], [1]) with tf.Session() as sess: print('begin:2, end 6, stride: 1: ', sess.run(x))

''' tf.strided_slice如果对高维向量进行切片时,begin, end, stride要对应向量的维度, 如果我们想把最后一列从多维向量中去除,可以运行如下代码, ''' data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] batch_size = len(data[0]) print('batch_size: ', batch_size) x = tf.strided_slice(data, [0,0], [batch_size, -1], [1, 1]) with tf.Session() as sess: print('begin: [0, 0], end: [batch_size, -1], stride: [1,1]: ', sess.run(x))
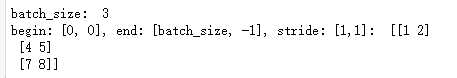
x = tf.concat([tf.fill([batch_size, 2], GO), data], 1) with tf.Session() as sess: print('concat and fill', sess.run(x))
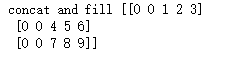
max_value = tf.reduce_max([1,3,2]) mask = tf.sequence_mask([1,3,2], max_value, dtype=tf.float32) with tf.Session() as sess: print('mask: ', sess.run(mask))

class sequence2sequence: def __init__(self, size_layer, num_layers, embedded_size, question_dict_size, answer_dict_size, learning_rate, batch_size): def cells(reuse = False): return tf.nn.rnn_cell.LSTMCell(size_layer, initializer=tf.orthogonal_initializer(), reuse = reuse) self.X = tf.placeholder(tf.int32, [None, None]) self.Y = tf.placeholder(tf.int32, [None, None]) self.X_seq_len = tf.placeholder(tf.int32, [None]) self.Y_seq_len = tf.placeholder(tf.int32, [None]) #构造图12-22所示的embedding层 with tf.variable_scope('encoder_embeddings'): #embedding层是二维矩阵,行数对应问题文本的单词格式,列数有程序指定 encoder_embeddings = tf.Variable(tf.random_uniform([question_dict_size, embedded_size], -1, 1)) #self.X包含句子每个单词的编号,网络根据编号从矩阵中挑选出对应的行 encoder_embedded = tf.nn.embedding_lookup(encoder_embeddings, self.X) #去掉最后一列,因为最后一个单词对应的是一个EOS控制符而不是有意义的单词 main = tf.strided_slice(self.X, [0,0], [batch_size, -1], [1, 1]) with tf.variable_scope('decoder_embeddings'): ''' 在main向量前面增加一列,用GO对应的值来填充,假设 main = [ [1,2,3], [4,5,6], [7,8,9]] 下面一行代码执行后,main会变成 main = [ [0,1,2,3], [0,4,5,6], [0,7,8,9]] ''' decoder_input = tf.concat([tf.fill([batch_size, 1], GO), main], 1) decoder_embeddings = tf.Variable(tf.random_uniform([answer_dict_size, embedded_size], -1, 1)) decoder_embedded = tf.nn.embedding_lookup(decoder_embeddings, decoder_input) with tf.variable_scope('encoder'): #将两个LSTM节点串联起来 rnn_cells = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)]) _, last_state = tf.nn.dynamic_rnn(rnn_cells, encoder_embedded, dtype = tf.float32) with tf.variable_scope('decoder'): rnn_cells_dec = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)]) #把encoder部分LSTM网络输出的最终状态当做decoder部分的LSTM网络的初始状态 outputs, _ = tf.nn.dynamic_rnn(rnn_cells_dec, decoder_embedded, initial_state = last_state, dtype = tf.float32) ''' 这里需要注意,假设self.X对应第一个句子是'how are your',self.Y对应的第一个句子是答案:'i am fine', 后者转换为编号后的向量[4,10, 106],由于每个句子对应向量含有50个分量, 那么不足50个单词的句子对应的向量会用控制符PAD的值进行填充,于是向量变为[4,6,106,1,1....1] 也就是后面47个分量用1来填充, 经过调用tf.sequence_mask后,会产生一个标志位向量[True, True, True, True,....True], 于是当向量输入到网络时,sequence_loss就会查看targets参数对应向量中的50个分量,其他分量 不看,由于答案文本中单词数可能很多,因此网络只考虑向量中对应的50个分量对应的节点进行更新,这样能有效 降低运算量 它在内部构造一个长度与answer_dict_size相同的内部向量,由于答案文本包含504个单词,因此 网络构造内部向量的长度为504,他把所有分量的值设置为0,根据填充后向量为[4,6,106,1,1....1], 它把下标为4,6,106,1这4个下标对应分量设置为1 然后与网络的输出层做差值运算,将运算结果反向传播后,使用梯度下降法调节参数,使得网络输出最后 结果中,下标为4,6,106,1这四个节点的值尽可能接近1,这意味着我们在调教网络看到输入语句是 'how are you'时,它懂得回答'i am fine' ''' with tf.variable_scope('logits'): self.logits = tf.layers.dense(outputs, answer_dict_size) print(self.logits) masks = tf.sequence_mask(self.Y_seq_len, tf.reduce_max(self.Y_seq_len), dtype = tf.float32) with tf.variable_scope('cost'): self.cost = tf.contrib.seq2seq.sequence_loss(logits = self.logits, targets = self.Y ,weights = masks) with tf.variable_scope('optimizer'): self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost)
#将单词转换为编号 def str_idx(corpus, dic): X = [] for i in corpus: ints = [] for k in i.split(): try: ints.append(dic[k]) except Exception as e: print(e) #2表示句子的结束 ints.append(2) X.append(ints) return X ''' 填充句子向量,当我们把句子单词转换为编号存储为向量时,规定向量的最大长度是50,如果句子单词不足50个 后面就用控制字符PAD填充,例如'how are you' 转换为编号时是11,10,4,填充后为11,10,4,1,1,1...1总共50个元素 ''' def pad_sentence_batch(sentence_batch, pad_int): padded_seqs = [] seq_lens = [] max_sentence_len = 50 for sentence in sentence_batch: padded_seqs.append(sentence + [pad_int] * (max_sentence_len - len(sentence))) seq_lens.append(50) return padded_seqs, seq_lens def check_accuracy(logits, Y): ''' logits是网络预测结果,Y是正确结果,我们将网络预测结果与正确结果的契合程度 作为网络预测准确性的判断 ''' acc = 0 for i in range(logits.shape[0]): internal_acc = 0 for k in range(len(Y[i])): if Y[i][k] == logits[i][k]: internal_acc += 1 acc += (internal_acc / len(Y[i])) return acc / logits.shape[0]
import tensorflow as tf import os #LSTM节点输出向量长度 size_layer = 128 #每个MultiRNNCell含有的LSTM节点个数 num_layers = 2 #一个单词对应的向量长度 embedded_size = 128 learning_rate = 0.001 batch_size = 32 epoch = 500 tf.reset_default_graph() sess = tf.InteractiveSession() model = sequence2sequence(size_layer, num_layers, embedded_size, vocabulary_size_question + 4, vocabulary_size_answer + 4, learning_rate, batch_size) sess.run(tf.global_variables_initializer()) saver = tf.train.Saver(tf.global_variables(), max_to_keep = 2) checkpoint_dir = os.path.abspath(os.path.join('/content/gdrive/My Drive/', 'checkpoints_chatbot')) checkpoint_prefix = os.path.join(checkpoint_dir, "model")
X = str_idx(text_question, dictionary_question) Y = str_idx(text_answer, dictionary_answer) for i in range(epoch): total_loss, total_accuracy = 0, 0 for k in range(0, (len(text_question) // batch_size) * batch_size, batch_size): batch_x, seq_x = pad_sentence_batch(X[k : k + batch_size], PAD) batch_y, seq_y = pad_sentence_batch(Y[k : k + batch_size], PAD) predicted, loss, _ = sess.run([tf.argmax(model.logits, 2), model.cost, model.optimizer], feed_dict = { model.X : batch_x, model.Y : batch_y, model.X_seq_len : seq_x, model.Y_seq_len : seq_y }) total_loss += loss total_accuracy += check_accuracy(predicted, batch_y) total_loss /= (len(text_question) // batch_size) total_accuracy /= (len(text_answer) // batch_size) print("epoch: %d, avg loss : %f, avg accuracy: %f" %(i+1, total_loss, total_accuracy)) path = saver.save(sess, checkpoint_prefix, global_step = i + 1)
import numpy as np import tensorflow as tf def predict(sentence, sess): X_in = [] for word in sentence.split(): try: X_in.append(dictionary_question[word]) except: X_in.append(PAD) pass test, seq_x = pad_sentence_batch([X_in], PAD) input_batch = np.zeros([batch_size,seq_x[0]]) input_batch[0] =test[0] log = sess.run(tf.argmax(model.logits,2), feed_dict={ model.X:input_batch, model.X_seq_len:seq_x, model.Y_seq_len:seq_x } ) result=' '.join(rev_dictionary_answer[i] for i in log[0]) return result with tf.Session() as sess: path = '/content/gdrive/My Drive/checkpoints_chatbot/model-498' saver = tf.train.import_meta_graph(path + '.meta') #将训练后存储成文件的网络参数重新加载 saver.restore(sess, path) print(predict('how are you ?', sess)) print(predict('where do you live?', sess)) print(predict('what is your name', sess))
