一、准备sql
# 创建部门表
create table dept (
id int primary key auto_increment,
name varchar(20)
);
insert into dept (name) values ('开发部'), (‘市场部’), ('财务部');
# 创建员工表
create table emp (
id int primary key auto_increment,
name varchar(10),
gender char(1), -- 性别
salary double, -- 工资
join_date date, -- 入职日期
dept_id int,
foreign key (dept_id) references dept(id) -- 外键,关联部门表(部门表外键)
);
insert into emp(name, gender, salary, join_date, dept_id) values('孙悟空','男',7200,'2013-02-24',1);
insert into emp(name, gender, salary, join_date, dept_id) values('猪八戒','男',3600,'2010-12-02',2);
insert into emp(name, gender, salary, join_date, dept_id) values('唐僧','男',9000,'2008-08-08',2);
insert into emp(name, gender, salary, join_date, dept_id) values('白骨精','女',5000,)
二、笛卡尔积
笛卡尔积:有两个集合A和B,取这两个集合所有组合的情况。
select * from dept, emp;

查询的数据有很大一部分是无用的数据,因此多表查询要消除无用的数据,也称消除无用的产生的笛卡尔积。
三、多表查询的分类
1.内连接查询
2.外连接查询
3.子查询
四、内连接查询
内连接查询分为两类,隐式内连接和显式内连接,这两种查询方式只是写法不同,但是查询出来的结果是相同的。
1.隐式内连接:使用where条件消除无用的数据
语法:select 字段列表 from 表名列表 where 条件
例如:查询所有的员工表信息及对应的部门信息。
select * from emp,dept where emp.dept_id = dept.id;
例如:查询员工表的姓名,性别及对应的部门表名称。
select a.name, a.gender, b.name from emp a, dept b where a.dept_id = b.id;
2.显式内连接
语法:select 字段列表 from 表名1 inner join 表名2 on 条件
例如:查询所有的员工表信息及对应的部门信息。
select * from emp [inner] join dept on emp.dept_id = dept.id;
例如:查询员工表的姓名,性别及对应的部门表名称。
select a.name, a.gender,b.name from emp a inner join dept b on a.dept_id = b.id;
elect a.name, a.gender,b.name from emp a join dept b on a.dept_id = b.id; -- inner 可以省略
3.内连接查询需要确定如下三个要素:
a. 从哪些表中查询
b. 条件是什么
c. 查询哪些字段
五、外连接查询
1.左外连接查询
语法:select 字段列表 from 表1 left [outer] join 表2 on 条件;
例如:查询所有员工信息,如果员工有部门,则显示部门名称,如果员工没有部门,则不显示部门名称。
a. 内连接
SQL语句:select t1.*, t2.name from emp t1, dept t2 where t1.dept_id = t2.id;
查询结果如下:
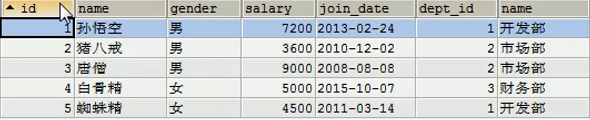
查询到的结果只有5条数据,没有新增的员工信息。因为新增的员工信息没有部门id,因此这条数据在此次查询中被排除掉了。
内连接查询到的结果是交集部分。
b. 左外连接
SQL语句:select t1.*, t2.name from emp t1 left join dept t2 on t1.dept_id = t2.id;
此SQL语句,emp为左表,dept为右表。
查询结果如下:

左外连接查询的结果是左表所有数据以及其交集部分。
c.右外连接
SQL语句:select t1.*, t2.name from emp t1 right join dept t2 on t1.dept_id = t2.id;
此SQL语句,emp为左表,dept为右表。
查询到的结果如下:
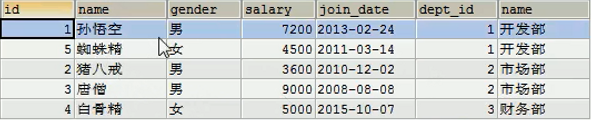
右外连接查询的结果是右表所有数据,以及左表中与右表有交集的数据。
2.右外连接查询
语法:select 字段列表 from 表1 right [outer] join 表2 on 条件;
例如:查询所有员工信息,如果员工有部门,则显示部门名称,如果员工没有部门,则不显示部门名称。
SQL语句:select * from dept t2 right join emp t1 on t1.dept_id = t2.id;
此SQL中,emp为右表,dept为左表,右外连接查询到的结果为emp的所有数据,以及dept表中与emp有交集的数据。
查询到的结果如下:

六、子查询
概念:查询中嵌套查询,称嵌套查询为子查询。
例如:查询工资最高的员工信息:
第一步:查询最高的工资是多少 9000
select max(salary) from emp;
第二部:查询员工信息,并且工资等于9000
select * from emp where salary = 9000;
得到如下结果:

根据以上分析的步骤,一条SQL就完成这个操作:
select * from emp where salary = (select max(salary) from emp);
得到如下结果:

七、子查询的结果是单行单列的情况
子查询结果可以作为条件,使用运算符去判断。
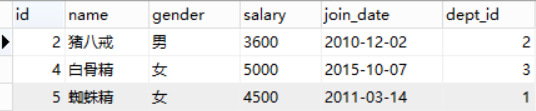
例如:查询员工工资小于平均工资的人
select * from emp where salary < (select avg(salary) from emp);
八、子查询的结果是多行单列的情况
子查询结果可以作为条件,使用运算符in去判断。
例如:查询‘财务部’和‘市场部’所有员工信息
select id from dept where name = '财务部' or name = '市场部';
select * from emp where dept_id = 3 or dept_id = 2;
select * from emp where dept_id in (3,2);
子查询语句
select * from emp where dept_id in (select id from dept where name = '财务部' or name = '市场部');
九、子查询的结果是多行多列的情况
子查询可以作为一张虚拟表,参与查询。
例如:查询员工入职日期是2011-11-11之后的员工信息和部门信息
子查询:
select * from dept t1, (select * from emp where join_date > '2011-11-11') t2 where t1.id = t2.dept_id;
内连接查询:
select * from emp t1, dept t2 where t1.dept_id = t2.id and t1.join_date > '2011-11-11';