来源:yq.aliyun.com/articles/278034
一、需求
一个朋友接到一个需求,从大数据平台收到一个数据写入在20亿+,需要快速地加载到MySQL中,供第二天业务展示使用。
二、实现再分析
对于单表20亿, 在MySQL运维,说真的这块目前涉及得比较少,也基本没什么经验,但对于InnoDB单表Insert 如果内存大于数据情况下,可以维持在10万-15万行写入。 但很多时间我们接受的项目还是数据超过内存的。 这里使用XeLabs TokuDB做一个测试。
三、XeLabs TokuDB介绍
项目地址: https://github.com/XeLabs/tokudb
相对官方TokuDB的优化:
-
内置了jemalloc 内存分配
-
引入更多的内置的TokuDB性能指标
-
支持Xtrabackup备份
-
引入ZSTD压缩算法
-
支持TokuDB的binloggroupcommit特性
四、测试表
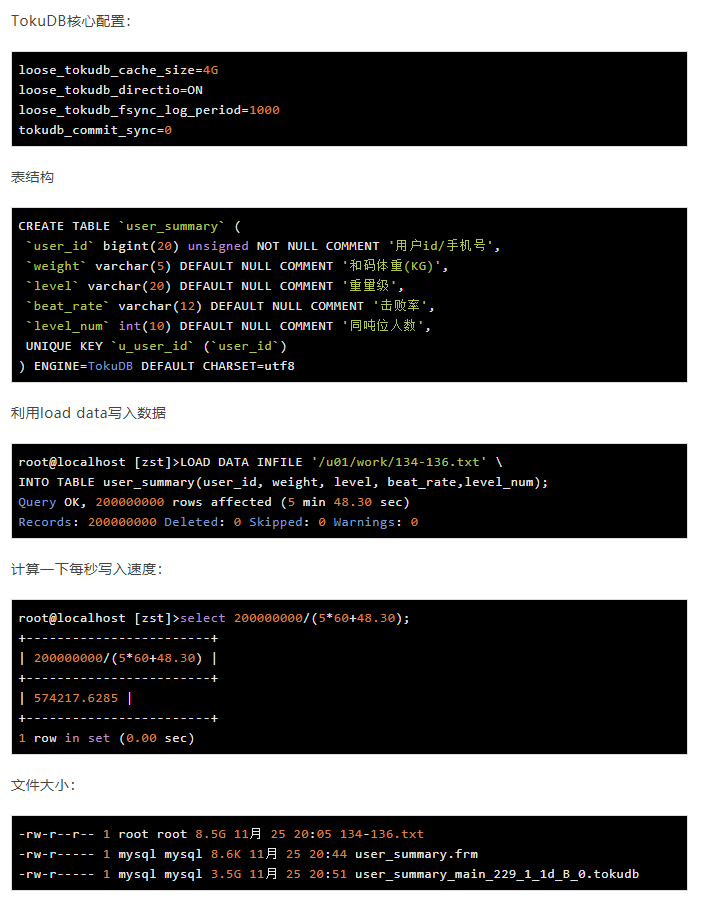
实际文件8.5G,写入TokuDB大小3.5G,只是接近于一半多点的压缩量。 对于20亿数据写入,实际测试在58分钟多点就可以完成。可以满足实际需求,另外对于磁盘IO比较好的机器(SSD类盘,云上的云盘),如果内存和数据差不多情况,这量级数据量测试在Innodb里需要添加自增列,可以在3个小多一点完成。 从最佳实战上来看,Innodb和TokuDB都写入同样的数据,InnoDB需要花大概是TokuDB3-4倍时间。文件大小区别,同样20亿数据:

文件大小在5倍大小的区别。
测试结论:
利用TokuDB在某云环境中8核8G内存,500G高速云盘环境,多次测试可以轻松实现57万每秒的写入量。
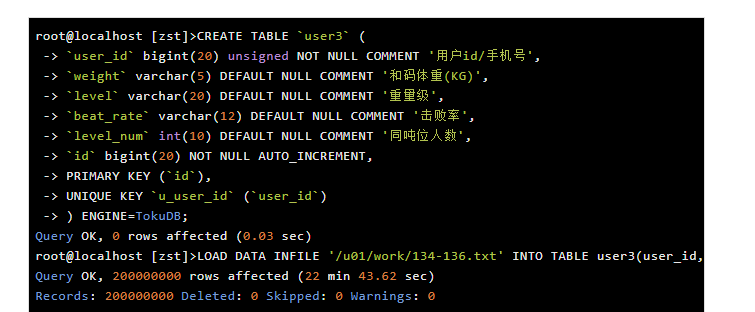
另外测试几种场景也供大家参考: 如果在TokuDB中使用带自增的主键,主键无值让MySQL内部产生写入速度,下降比较明显,同样写入2亿数据,带有自建主键:
MySQL每秒57万的写入,带你飞
同样的数据写入在主键自增无值产生时,不能使用TokuDB的 Bulk loader data特性,相当于转换为了单条的Insert实现,所以效果上慢太多。
关于TokuDB Bulk Loader前提要求,这个表是空表,对于自增列,如自增列有值的情况下,也可以使用。 建议实际使用中,如果自增列有值的情况下,可以考虑去除自增属性,改成唯一索引,这样减少自增的一些处理逻辑,让TokuDB能跑地更快一点。 另外在Bulk Loader处理中为了追求更快速的写入,压缩方面并不是很好。
关于TokuDB Bulk Loader :
https://github.com/percona/PerconaFT/wiki/TokuFT-Bulk-Loader
五、测试环境说明
测试使用CentOS7环境,编译的XeLabs TokuDB版本
百度云地址:
https://pan.baidu.com/s/1S6O48fcHmMXYPy9KXi6ObA
提取码:tav4