有关形参和实参
例1
void fun( int x )
{
x = 5;
}
void main()
{
int a = 3;
fun( a );
}
对C语言有一定了解的人应该都知道,通过调用fun并不能把a的值改变为5.(如果这一点你都不明白,请不要继续往下阅读了)。因为C语言并不是真正的把a传入fun函数,只是复制了a的值传给局部变量x(值传递,形式参数)。
例2
void fun( int x[] )
{
x[1] = 1;
}
void main()
{
int a[2] = { 0, 0 };
fun( a );
printf( "%d", a[1] );
}
然而这段代码最后的输出却是1。为什么数组传入后函数里对x的改变就可以改变a的值呢?因为在C语言中,数组作为参数传递的时候,传入的是数组首地址(相当于传入一个指向数组的指针),而不是采用和普通整形变量一样的值传递(拷贝一份数值)。
验证
例1
#include <stdio.h>
#include <time.h>
int a[5] = {0};
int b[5000] = {0};
int c[500000] = {0};
void fun( int x[] )
{
return ;
}
void main()
{
int i, j;
time_t start_time, end_time; //记录起始时间、结束时间
//test 1 -----------------------------------------------------------------
start_time = clock();
for( i = 0; i < 10000; i++ )
for( j = 0; j < 500; j++ ) //循环5000000次
fun( a );
end_time = clock();
printf( "Array length : 5 Use time : %ld
", end_time - start_time );
//test 2 -----------------------------------------------------------------
start_time = clock();
for( i = 0; i < 10000; i++ )
for( j = 0; j < 500; j++ )
fun( b );
end_time = clock();
printf( "Array length : 5000 Use time : %ld
", end_time - start_time );
//test 3 -----------------------------------------------------------------
start_time = clock();
for( i = 0; i < 10000; i++ )
for( j = 0; j < 500; j++ )
fun( c );
end_time = clock();
printf( "Array length : 500000 Use time : %ld
", end_time - start_time );
}
上面的程序中定义了三个长度不同的数组abc,函数fun的功能很简单,传入一个数组,然后什么都不干直接返回。如果C语言采用值传递的方法,那么显而易见的test2和test3的运行的时间应该比test1大的多。让我们看看输出。

多运行几次,你会发现,三段程序的执行时间几乎一致。这成功的验证了我们的想法。同样的,你不妨试试定义成50000*50000的二维数组,程序的效率和你传入一个长度为5的数组是一样的。TRY IT!
例2
void fun( int x[100] )
{
printf("x size : %d
",sizeof(x) );
}
void main()
{
int a[100];
printf("a size : %d
",sizeof(a));
fun(a);
}

对于a的大小为400大家应该不陌生,4(int型)*100(数组长度)=400
但是同样的int x[100],x的大小就只有8(long int型,指针大小)。说明了并没有为x开辟100个单元空间用来存储参数,x只是一个指针。
`
例3
手头有数据结构课本的学弟学妹不妨翻到P220看一下Figure7.2。
函数的参数列表有两个 Element_Type A[]和int N。其中A[]是待排序的数组。然而额外传递了一个等于A长度的参数N。说明在参数传递的过程中,数组的长度信息丢失了,因此不得不通过int N传入。
一个问题
既然无论多大的数组,都只是传入首地址进函数,就产生了一个问题:数组的长度信息丢失了!就好比你只知道每个班级第一个同学的学号,而无法知道整个班级的人数。因此,你必须显式地定义一些参数的长度。
尝试定义这样一个函数
void fun( int x[][] )
{
return ;
}
编译器会丢给你一个ERROR。提示 array type has incomplete element type(数组类型含有不完整的元素类型)。因为,编译器不知道这个二维数组是多大的!
所以你只能写成
void fun( int x[][5] )
{
return ;
}
另一个问题
你可能要问,为什么第一个方括号里可以不用填写数字(即不需要告诉编译器你二维数组的行数),同时,以下的定义是合法的
void fun( int x[] )
{
return ;
}
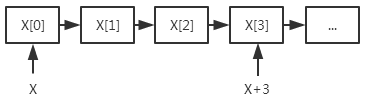
让我们了解一下数组是如何定位元素的。对于一维数组x[3],定位过程是 x(首地址)+3(偏移量),这个偏移量是我们给定的,可以是任意值(甚至允许你越界访问)
因为x是一个传入的已知的指针,因此对于编译器来说,信息已经足够。
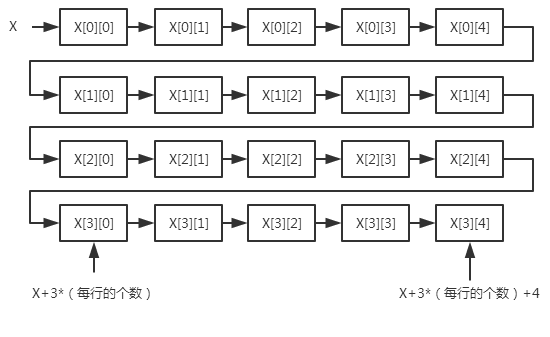
对于二维数组x[3][4],定位过程是x(数组首地址)+3(行数)* 每行数组的元素数 + 4(偏移量)
此处x已知,3和4已经给出。但是对于编译器来说,每行数组的元素数是未知的,因此必须显示给定。
欺骗编译器
兵法有云,知己知彼,百战不殆。我们既然知道了数组内部的存储方式,不妨来尝试“欺骗”一下编译器
int a[3][3] = {0};
void fun( int x[][4] ) //CHEAT!
{
x[1][1] = 1;
}
void main()
{
int i, j;
fun( a );
for( i = 0; i < 3; i++ ) //打印数组
{
for( j = 0; j < 3; j++ )
printf( "%d ", a[i][j] );
printf("
");
}
}
在这里,我们对编译器做了一个“欺骗”,我们欺骗它说,我们将传入一个每行长度为4的数组x进去。但是实际上传入的a是一个3行3列的数组。
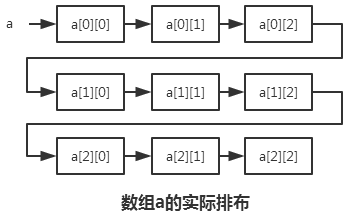
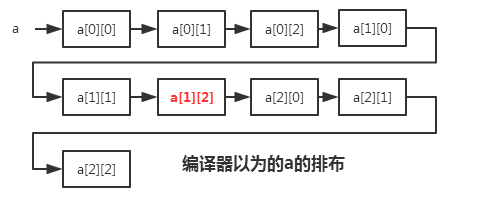
看看结果

当我们改变x[1][1]时。编译器傻傻得以为一行真的有四个元素
把a[0][0]到a[0][2]和a[1][0]当作了第一行的四个元素并跳过
把a[1][1]当作x[1][0],把a[1][2]当作了x[1][1]进行修改
总结
C语言中,数组作为参数,总是只能传入指针,这是C语言一个伟大的发明(他允许你通过函数操作任何一个大数组而不影响效率)。但是也带来了一些不便(你必须显式的指定数组长度,或者在函数的传入参数列表中加入一个变量传递数组长度信息)