window环境下 使用python脚本爬取豆瓣
环境安装
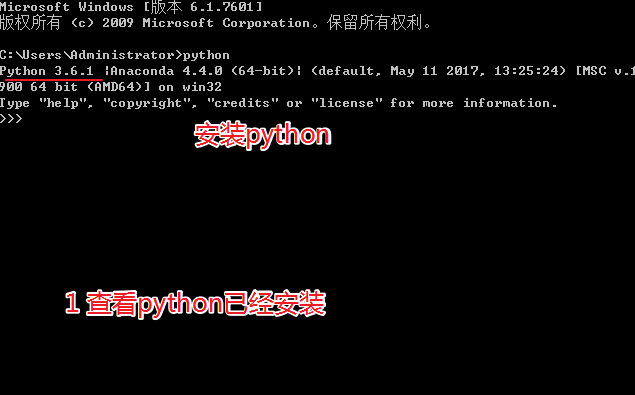
- python
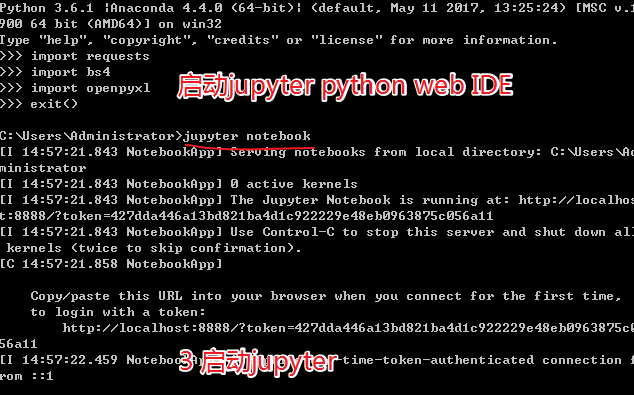
python开发环境 - jupyter
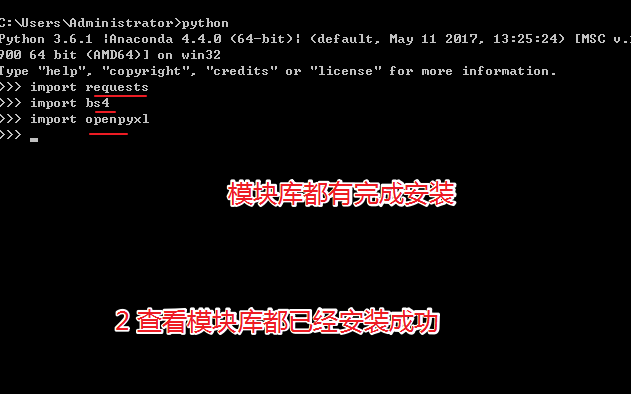
python web IDE - requests
python requests模块用于向web页面发起访问请求 - BeautifulSoup
Beautiful Soup是python的一个库,用于从html和xml文件中拉去数据 - openpyxl
openpyxl 是python的一个库, 用于读写excel文件 - infolite
chrome插件安装安装地址
图文操作
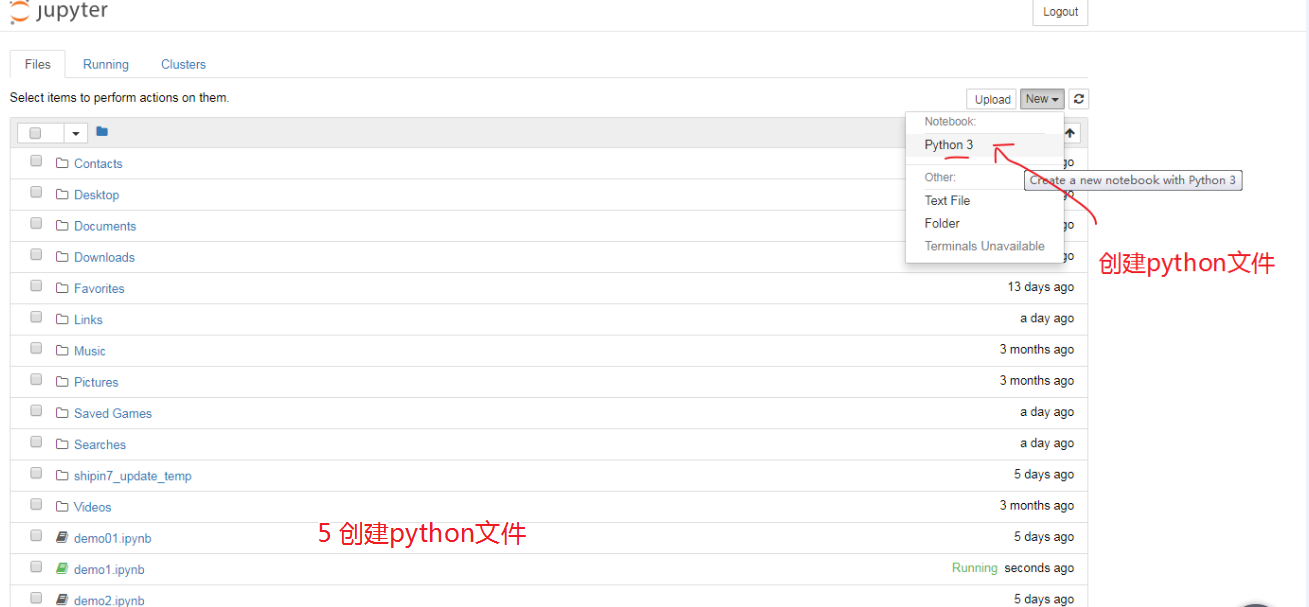
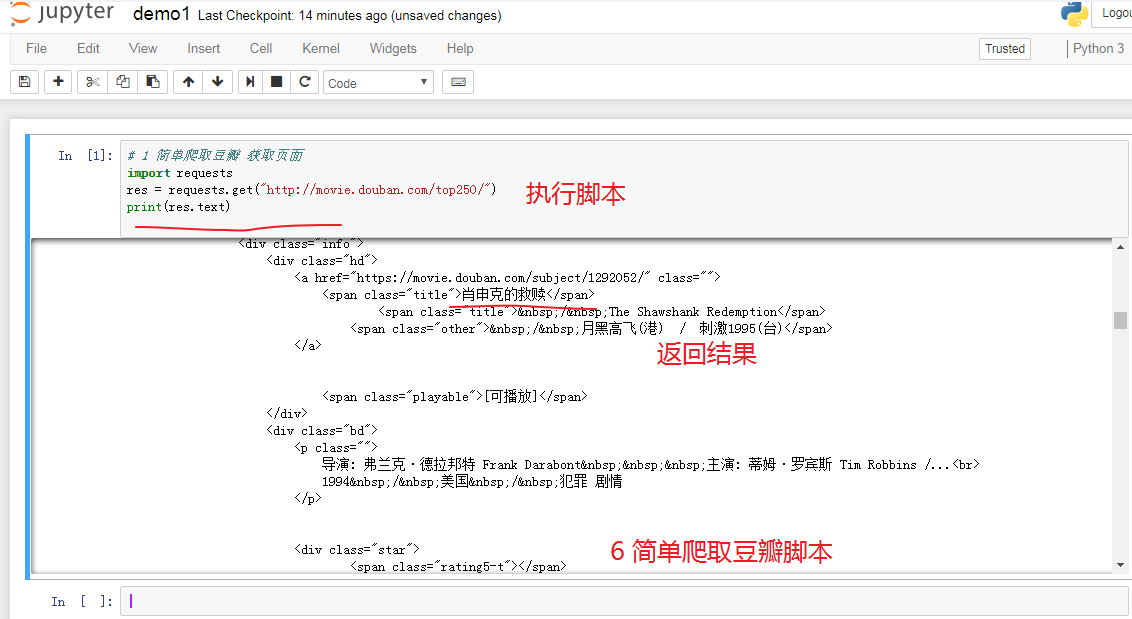
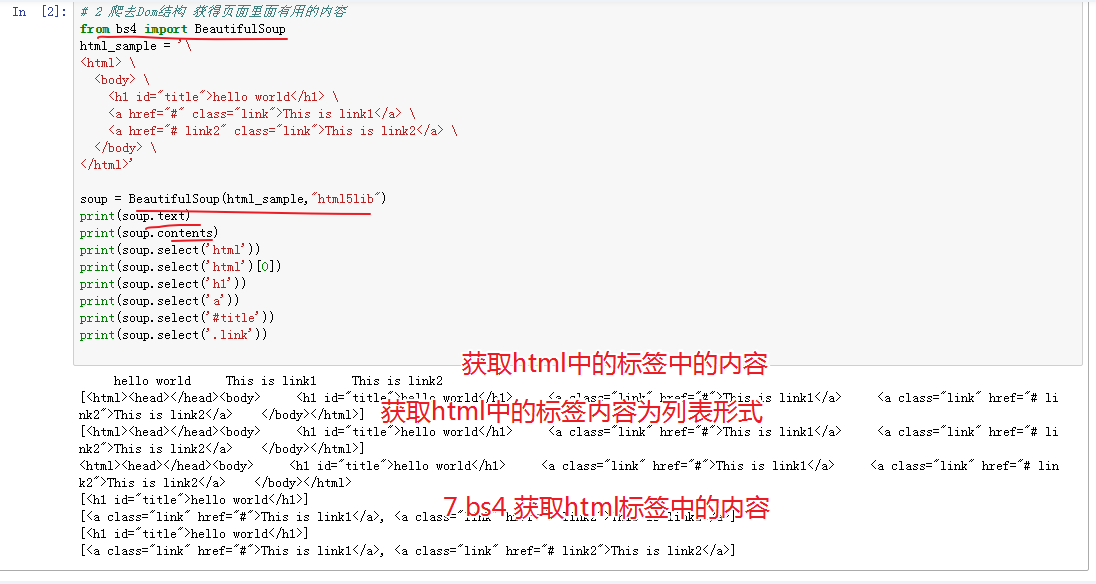
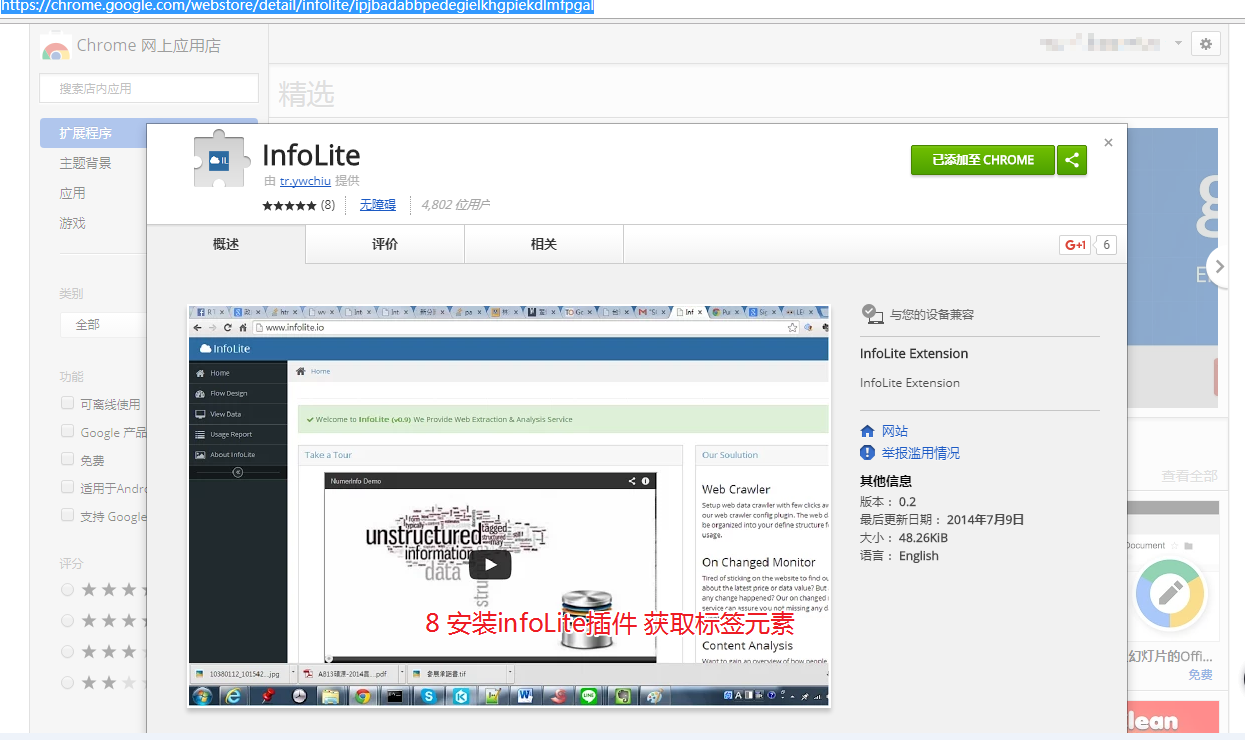
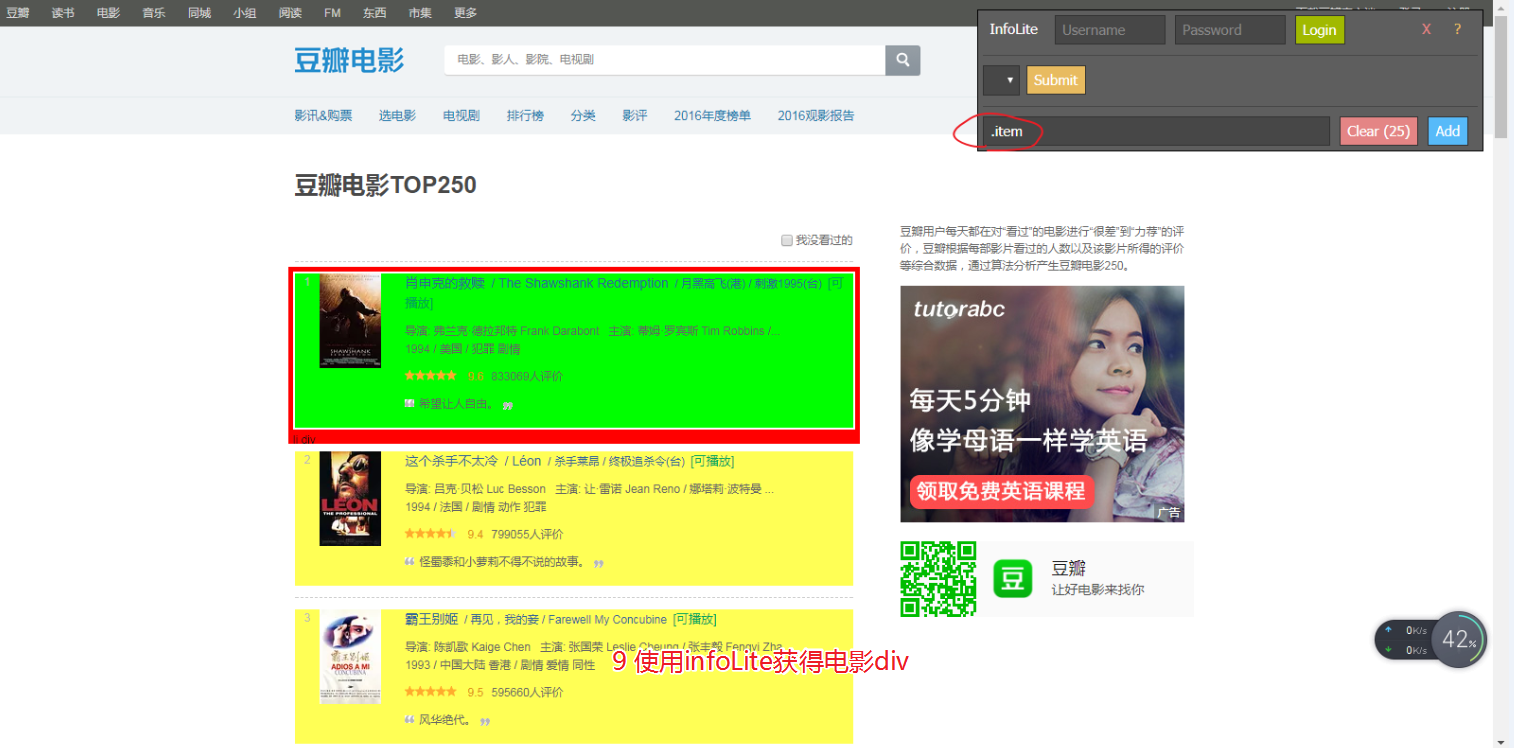
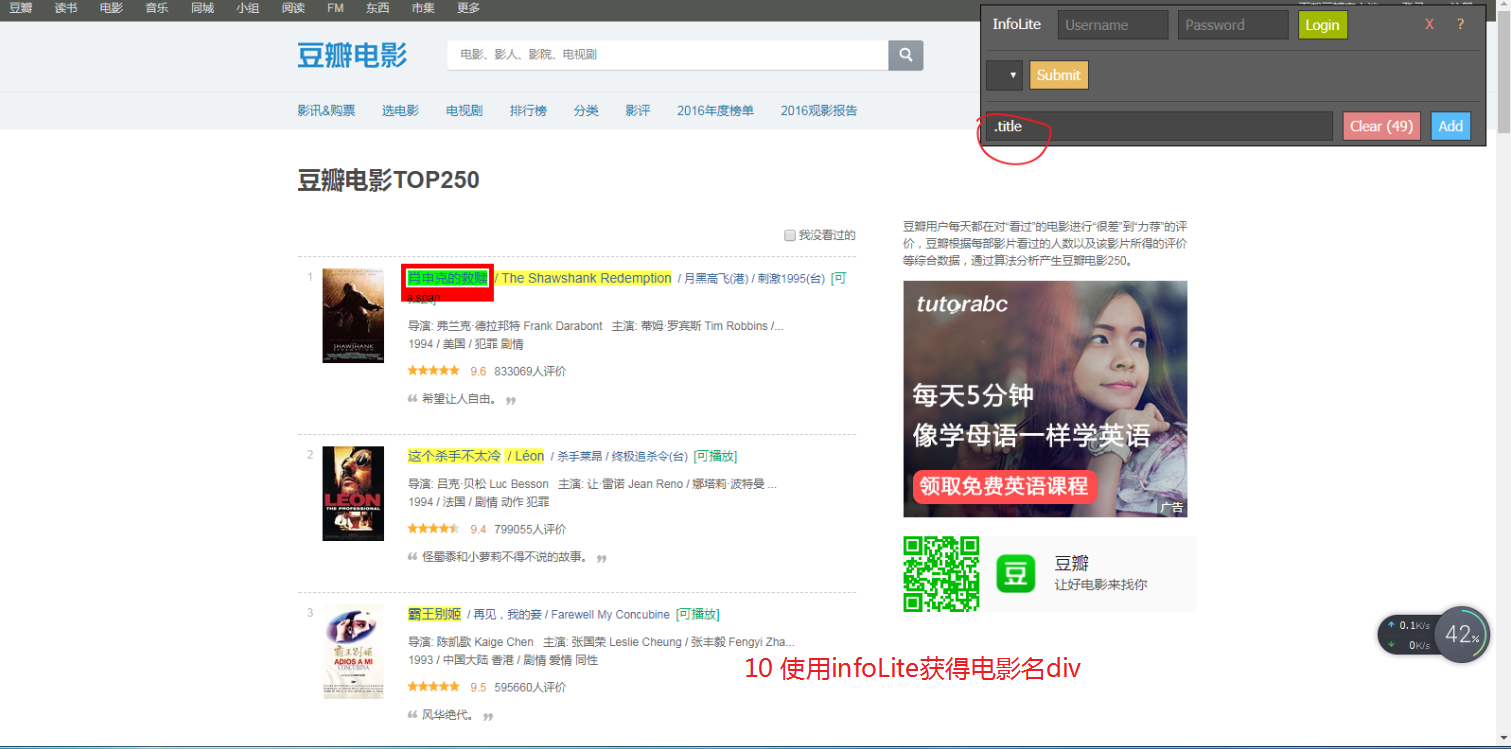

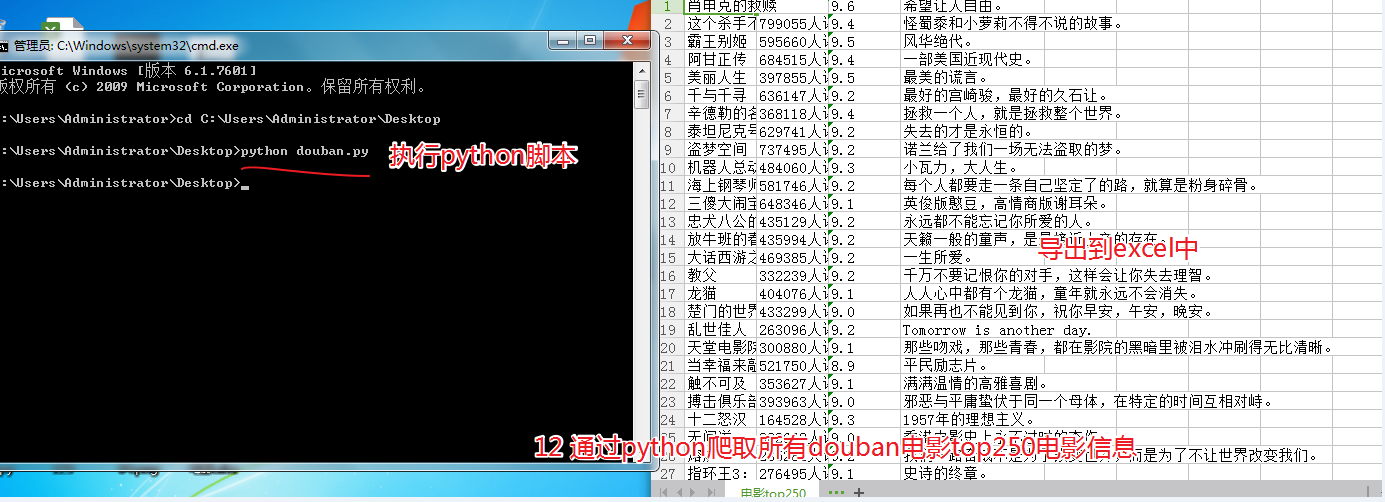
代码
# 1 简单爬取豆瓣 获取页面
import requests
res = requests.get("http://movie.douban.com/top250/")
print(res.text)
# 2 爬去Dom结构 获得页面里面有用的内容
from bs4 import BeautifulSoup
html_sample = '
<html>
<body>
<h1 id="title">hello world</h1>
<a href="#" class="link">This is link1</a>
<a href="# link2" class="link">This is link2</a>
</body>
</html>'
soup = BeautifulSoup(html_sample,"html5lib")
print(soup.text)
print(soup.contents)
print(soup.select('html'))
print(soup.select('html')[0])
print(soup.select('h1'))
print(soup.select('a'))
print(soup.select('#title'))
print(soup.select('.link'))
# 3上面两个实例结合
import requests
from bs4 import BeautifulSoup
res = requests.get("http://movie.douban.com/top250/")
soup = BeautifulSoup(res.text,"html5lib")
# soup = BeautifulSoup(res.text, 'html.parser')
for item in soup.select(".item"):
print(item.select(".title"))
#!/usr/bin/env python
# encoding=utf-8
import requests,re
import codecs
from bs4 import BeautifulSoup
from openpyxl import Workbook
wb = Workbook()
dest_filename = '电影.xlsx'
ws1 = wb.active
ws1.title = "电影top250"
DOWNLOAD_URL = 'http://movie.douban.com/top250/'
def download_page(url):
"""获取url地址页面内容"""
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content
return data
def get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] #名字
star_con = [] #评价人数
score = [] #评分
info_list = [] #短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() #电影名字
level_star = i.find('span',attrs={'class':'rating_num'}).get_text() #评分
star = i.find('div',attrs={'class':'star'})
star_num = star.find(text=re.compile('评价')) #评价
info = i.find('span',attrs={'class':'inq'}) #短评
if info: #判断是否有短评
info_list.append(info.get_text())
else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') #获取下一页
if page:
return name,star_con,score,info_list,DOWNLOAD_URL + page['href']
return name,star_con,score,info_list,None
def main():
url = DOWNLOAD_URL
name = []
star_con=[]
score = []
info = []
while url:
doc = download_page(url)
movie,star,level_num,info_list,url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score+level_num
info = info+ info_list
for (i,m,o,p) in zip(name,star_con,score,info):
col_A = 'A%s'%(name.index(i)+1)
col_B = 'B%s'%(name.index(i)+1)
col_C = 'C%s'%(name.index(i)+1)
col_D = 'D%s'%(name.index(i)+1)
ws1[col_A]=i
ws1[col_B] = m
ws1[col_C] = o
ws1[col_D] = p
wb.save(filename=dest_filename)
if __name__ == '__main__':
main()