Grafana是最漂亮的web监控平台,也可以看历史,可以展示所有的东西。
jmeter原生监控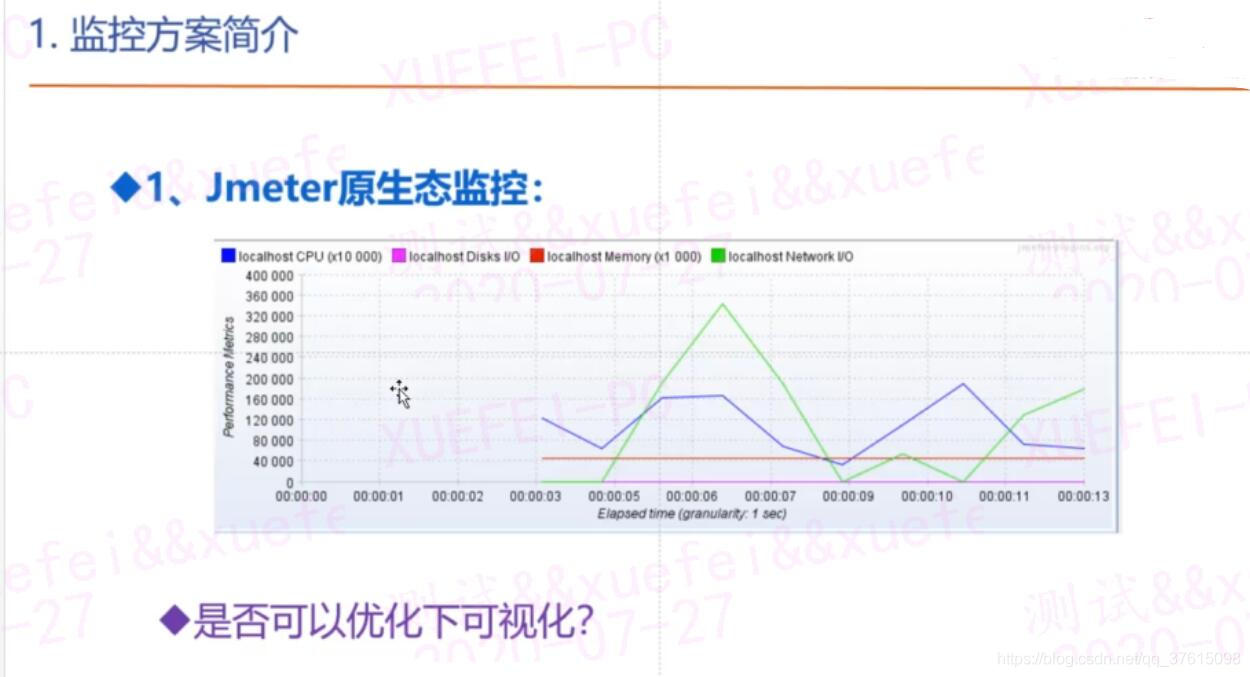
有点丑,以下为优化方案
方案简介
InfluxDB是一个时序数据库。go语言开发的。(时序数据库:就是几时几秒里面有什么值)
jemter把数据给InfluxDB,InfluxDB再把数据给Grafana。InfluxDB是他们的中间人
要做两件事:
-
1.先把jmeter和InfluxDB配起来,性能测试的数据,有jmeter写到influxDB里面
-
2.Grafana也把这个InfluxDB配起来。才能出图
需要下载的资源
1.mysql-connector-java-5.1.47-bin.jar 用于 JDBC 连接
2.JMeter-InfluxDB-Writer-plugin-1.2.jar 存储时序数据
3.jmeter-load-test_rev5.json 用于 Grafana 数据可视化
为便于下载,所需文件存储于网盘中
链接:https://pan.baidu.com/s/111F5KRMg2azSchS412G4iQ 密码:wa6v
第一步:
将jar放在lib\ext目录下面
将JMeter-InfluxDB-Writer-1.0.jar拷贝到D:\Jmeter工具\apache-jmeter-5.1.1\lib\ext目录下:
打开jemter,有一个后端监控器。因为jar包放进去了。多了一个InfluxDB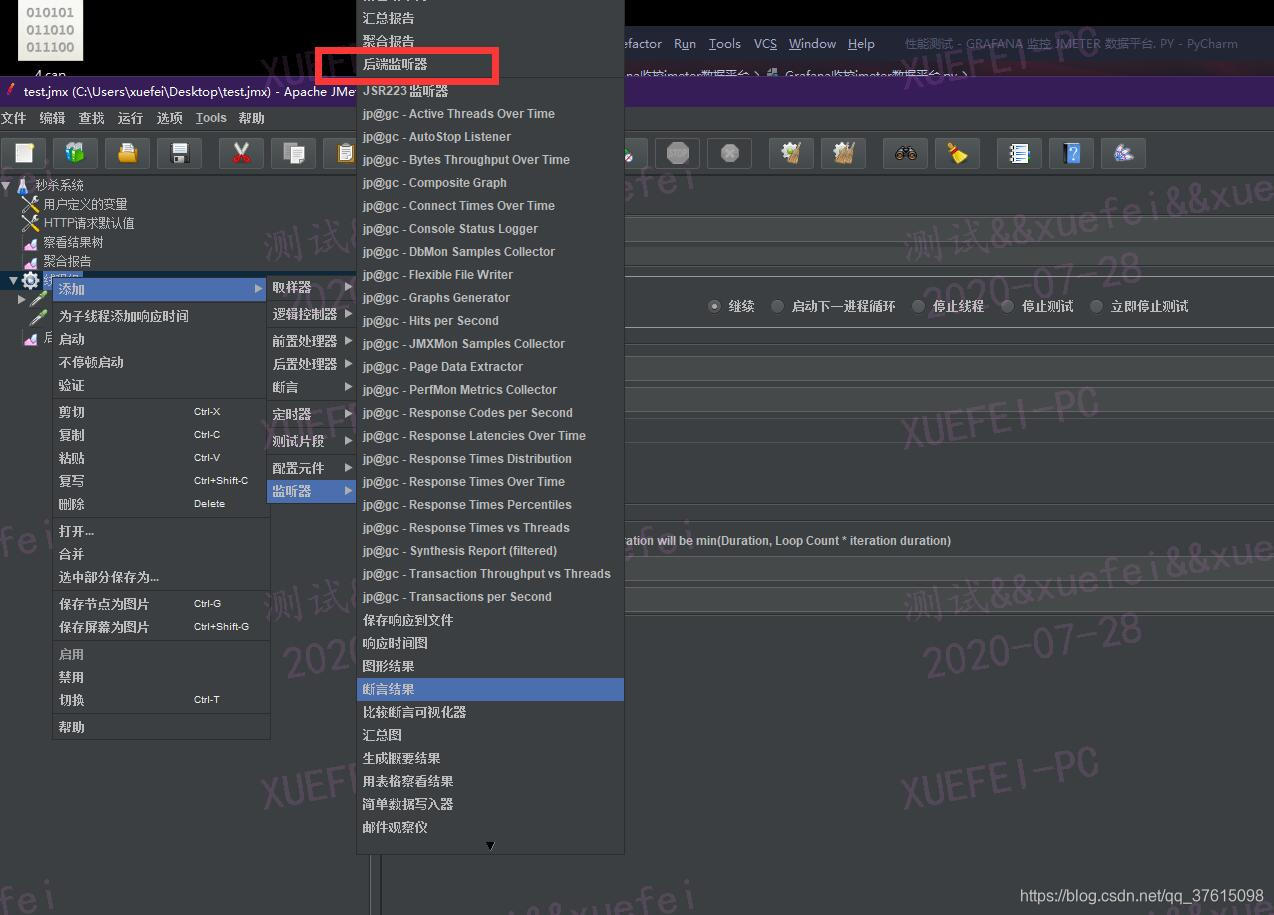
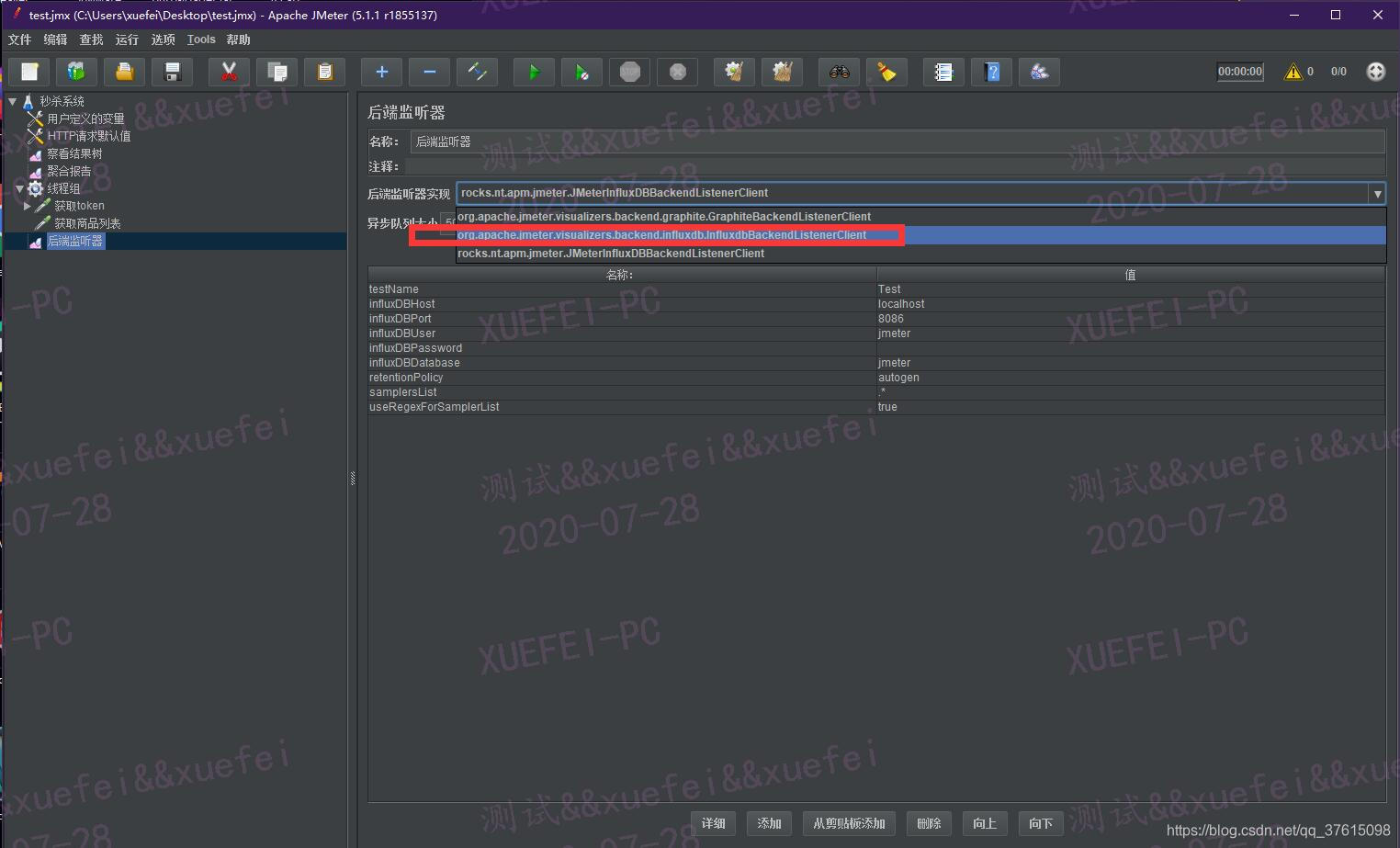
现在还不能跑,因为依赖一个条件。InfluxDB虽然jmeter有插件了。但是InfluxDB本身还没有在运行
第二步:
安装influxdb使用的Red Hat和CentOS用户可以安装InfluxDB最新的稳定版本 yum包管理器:
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL \$releasever
baseurl = https://repos.influxdata.com/rhel/\$releasever/\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF或者如果你的操作系统是使用systemd(CentOS 7 +,RHEL 7 +):
sudo yum install influxdb
sudo systemctl start influxdb
找到InfluxDB配置文件(/etc/influxdb/influxdb.conf)
vi /etc/influxdb/influxdb.conf
influxdb.conf中的大多数设置都被注释掉了;所有注释掉的设置将确定为内部默认值。如果配置文件中的任何未注释的设置都会覆盖内部默认值。
请注意,本地配置文件不需要包含每个配置设置。
如果你无法找到配置文件,可以使用InfluxDB显示配置命令
influxd config
Jmeter使用graphite协议去写入数据到InfluxDB,因此,需要在InfluxDB配置文件启用它,如下图所示:
[[graphite]]
enabled = true
bind-address = ":2003"
database = "jmeter"
retention-policy = ""
protocol = "tcp"
batch-size = 5000
batch-pending = 10
batch-timeout = "1s"
consistency-level = "one"
separator = "."
udp-read-buffer = 0
修改后,使用以下命令加载InfluxDB启动
有两种方法可以使用配置文件启动InfluxDB:
1.使用以下-config选项将进程指向正确的配置文件
influxd -config /etc/influxdb/influxdb.conf
2.将环境变量设置为INFLUXDBCONFIGPATH配置文件的路径并启动
echo $INFLUXDB_CONFIG_PATH
/etc/influxdb/influxdb.conf
influxd
InfluxDB操作
[root@zuozewei ~]# influx #登录数据库
Connected to http://localhost:8086 version 1.6.2
InfluxDB shell version: 1.6.2
> show databases #查看所有数据库
name: databases
name
----
_internal
> CREATE DATABASE "jmeter" #创建数据库
> use jmeter #切换数据库
Using database jmeter
> CREATE USER "admin" WITH PASSWORD 'admin' WITH ALL PRIVILEGES # 创建管理员权限的用户
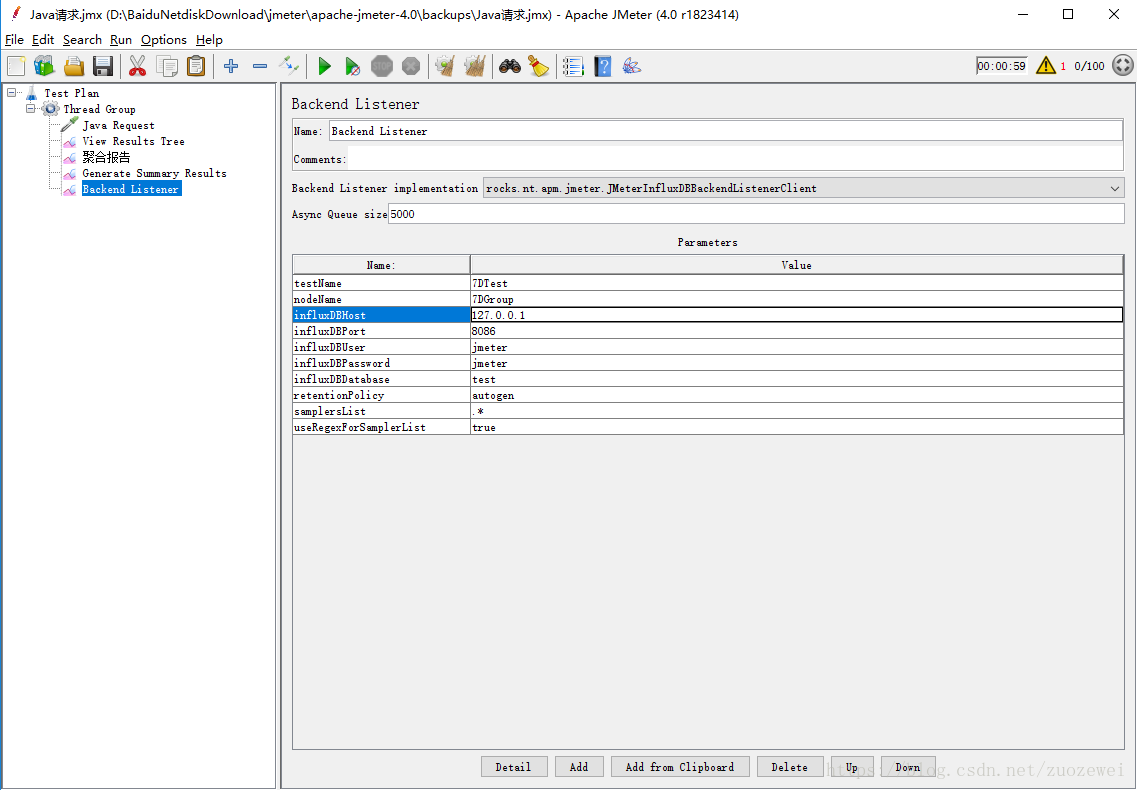
jmeter 添加监听器 Backend Listener 验证数据是否能写入到 influxdb
jmeter4.0
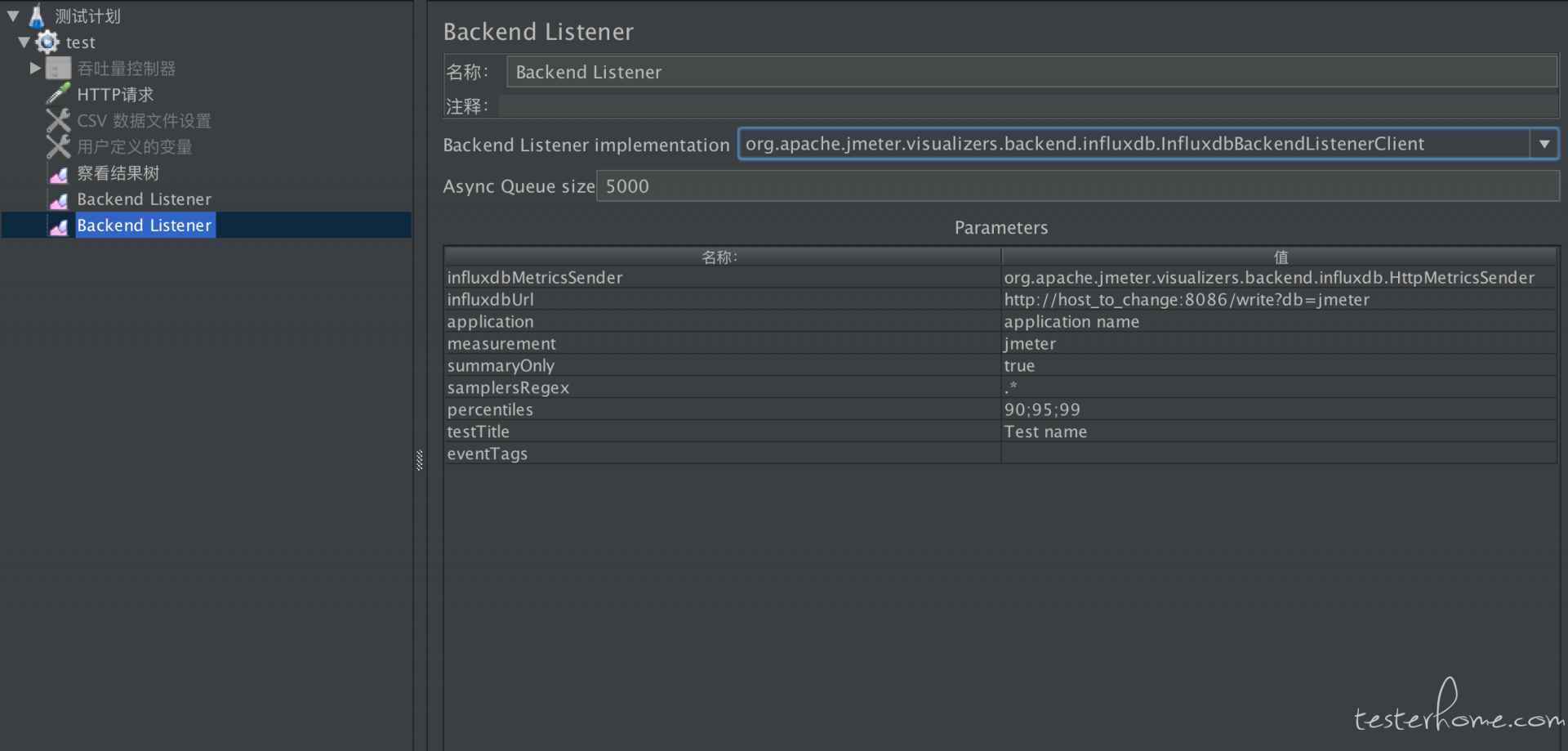
influxdbUrl :http://host_to_change:8086/write?db=jmeter
#host_to_change写安装influxdb服务的ip 端口如修改填写修改后的端口 db前面创建的数据库:jmeter
application :随便写后面grafana会用到
添加请求运行
回到 influx 终端:选择数据库
> use jmeter
执行 sql 语句查看刚刚的请求数据是否有插入,如有说明配置成功
> select * from jmeter第三步:
Grafana&InfluxDB集成
什么是Grafana?
Grafana是一个开源软件,拥有丰富的指标仪表盘和图形编辑器,适用Graphite, Elasticsearch, OpenTSDB, Prometheus,InfluxDB。简单点说就是一套开源WEB可视化平台。
官网地址:https://grafana.com/
1、安装启动
下载安装
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.2.0-1.x86_64.rpm
sudo yum localinstall grafana-4.2.0-1.x86_64.rpm
启动
service grafana-server start
Starting grafana-server (via systemctl): [ OK ]
使用浏览器打开 http://IP:3000/login,访问Grafana主页

创建InfluxDB数据源
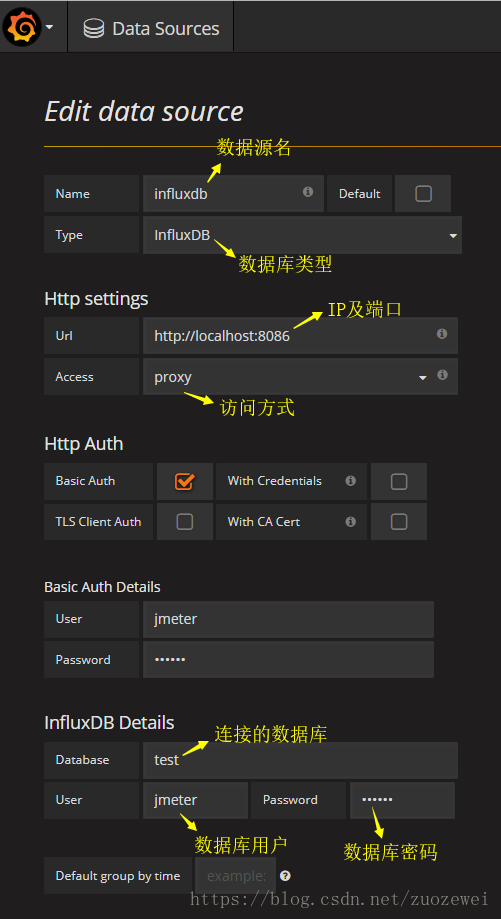
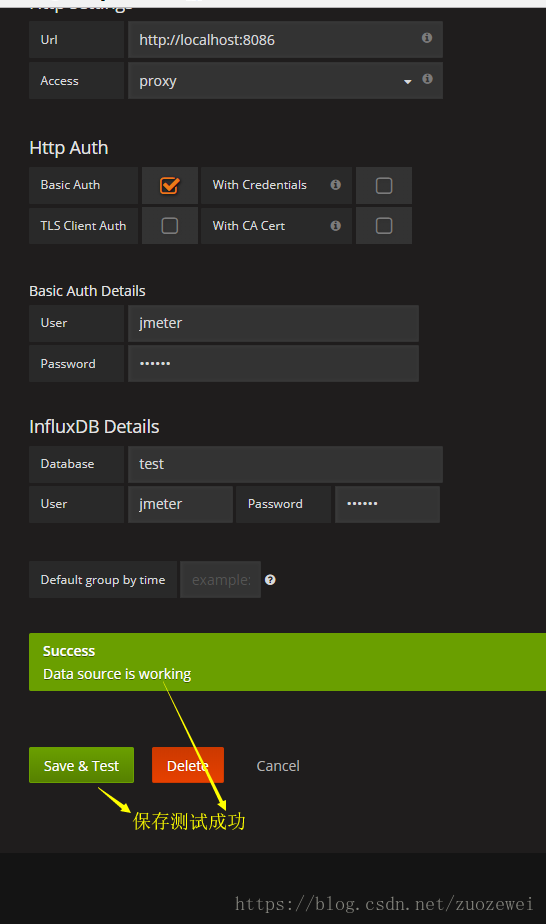
单击save&test,确保可以连接上InfluxDB
创建dashboard

添加Graph面板
数据绑定
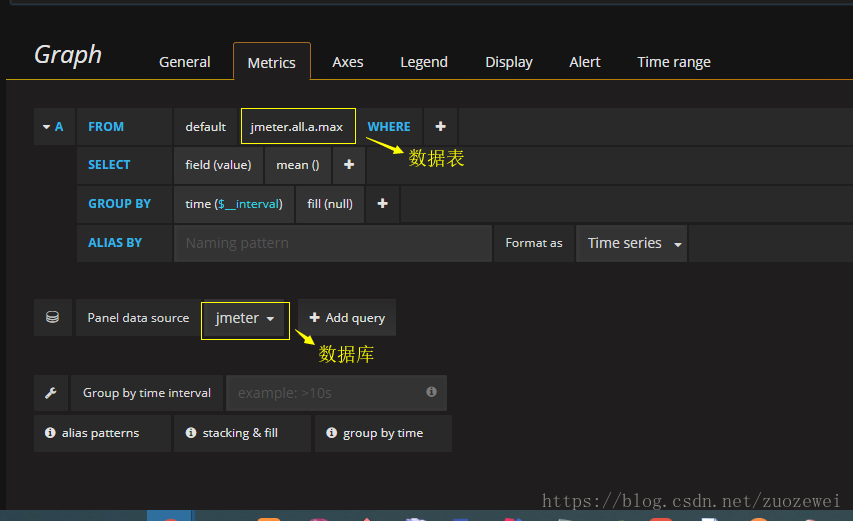
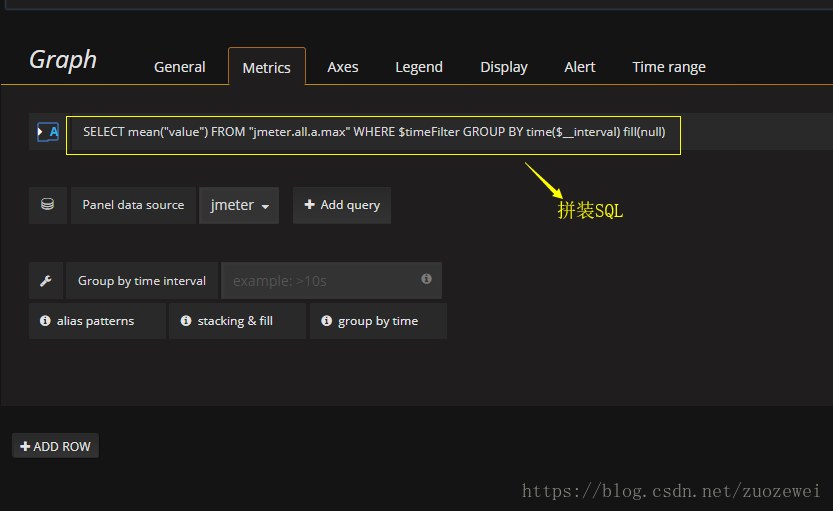
线程数/用户相关指标
test.minAT-Min active threads:最小活跃线程数
test.maxAT-Max active threads:最大活跃线程数
test.meanAT-Mean active threads:活跃线程数
test.startedT-Started threads:启动线程数
test.endedT-Finished threads:结束线程数
响应时间指标
.ok.count:采样器的成功响应数
.h.count:每秒点击数
.ok.min:采样器成功最短响应时间
.ok.max:采样器成功最长响应时间
.ok.avg:采样器成功平均响应时间
.ok.pct:采样器成功响应百分比
.ko.count:采样器失败响应数
.ko.min:采样器失败的响应最短时间
.ko.max:采样称失败最长响应时间
.ko.avg:采样器失败平均响应时间
.ko.pct:采样器失败响应百分比
.a.count:采样器响应数(ok.count和ko.count的总和)
.a.min:采样器最小响应时间(ok.count和ko.count的最小值)
.a.max:采样器最大响应时间(ok.count和ko.count的最大值)
.a.avg:采样器平均响应时间(ok.count和ko.count的平均值)
.a.pct:采样器响应百分比(根据和失败样本的总数计算)
Backend Listener的默认百分位设置为“90;95;99”,即百分位数为90%,95%和99%。
Graphite使用点(“.”)去拆分的元素,这可能与十进制百分位值混淆。JMeter转换任何此类值,用下划线(“ - ”)替换点(“.”)。例如,“99.9 ”变为“99_9 ”
默认情况下,JMeter发送在samplerName“all”下累计的所有采样器的指标。 如果配置了 BackendListenerSamplersList,那么JMeter还会发送匹配样本名称的指标,前提是配置 summaryOnly=true
压测中的效果
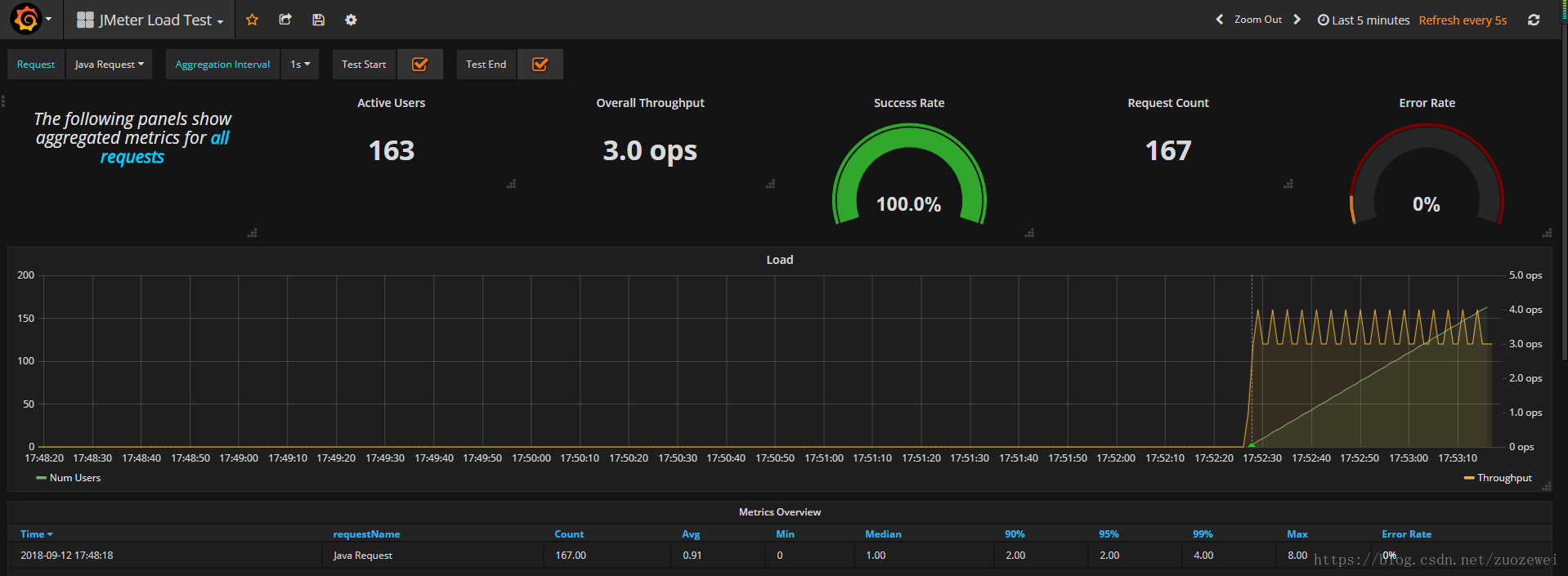
第四步:
导入Dashboard模版
如果让大家去设计一个好看的Dashboard,估计大家都不太想从零开始自己设计,其实Grafana官网提供丰富的模版的库,大家可以自己上去找,然后进行二次扩展。
官网模版库:https://grafana.com/dashboards
搜索看板模版
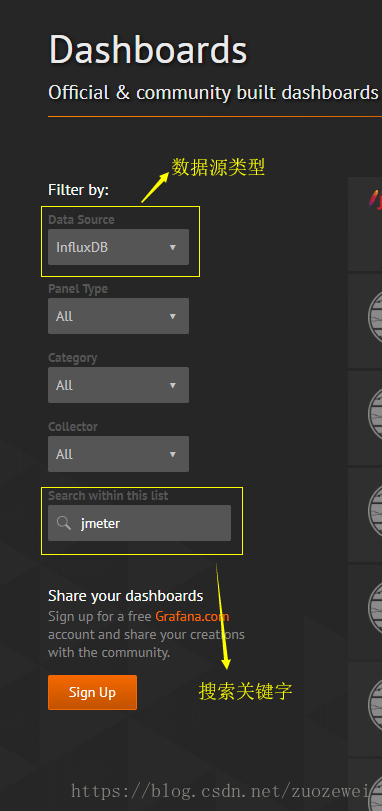
此处,我选择下载这个下载量3000+的模版

下模版JSON文件
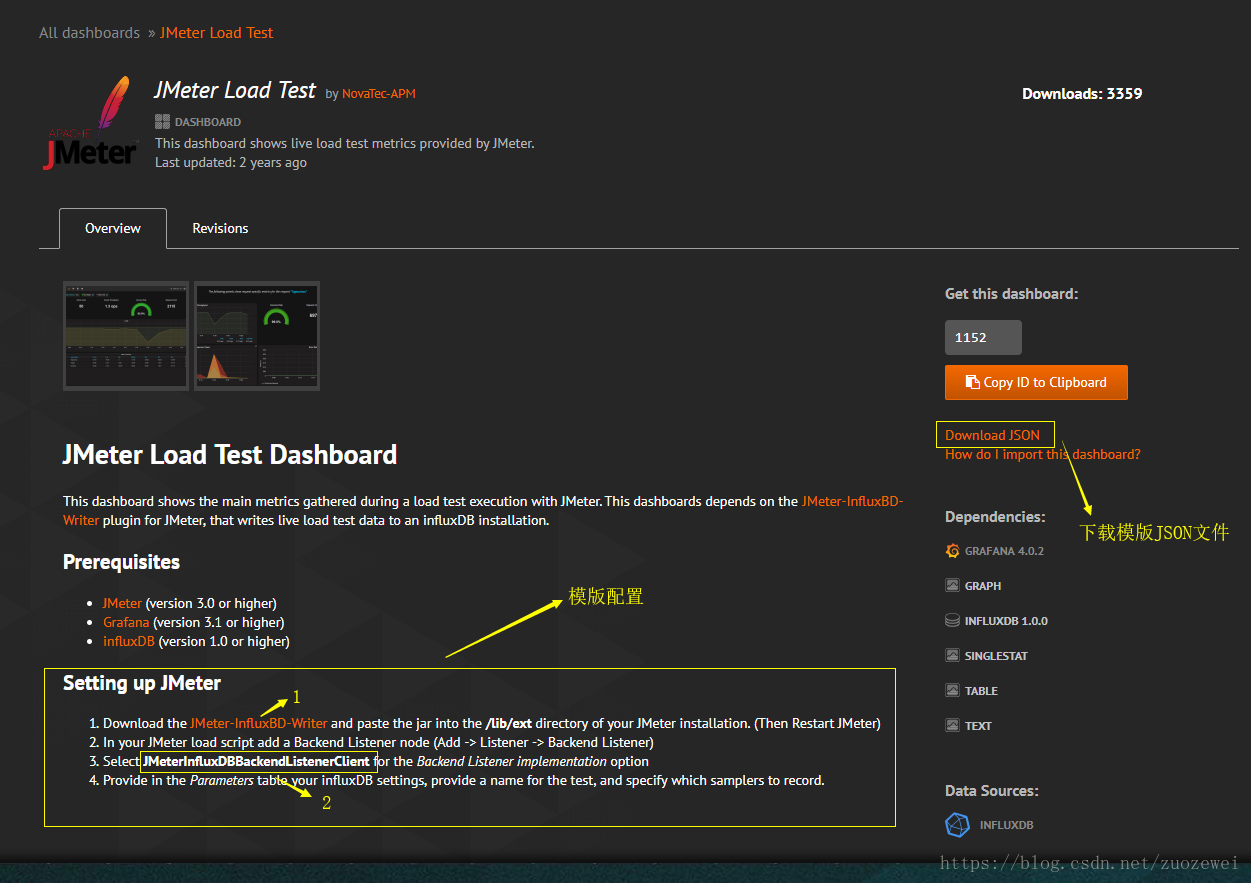
导入模版
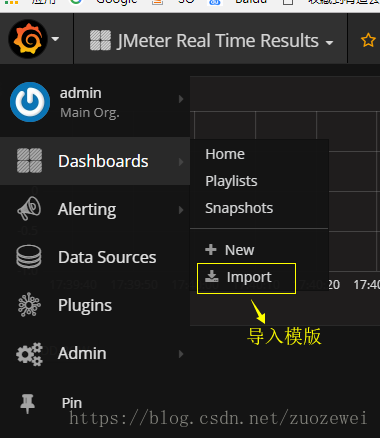

选择数据源

JMeter Backend Listener设置
压测期间的动画效果
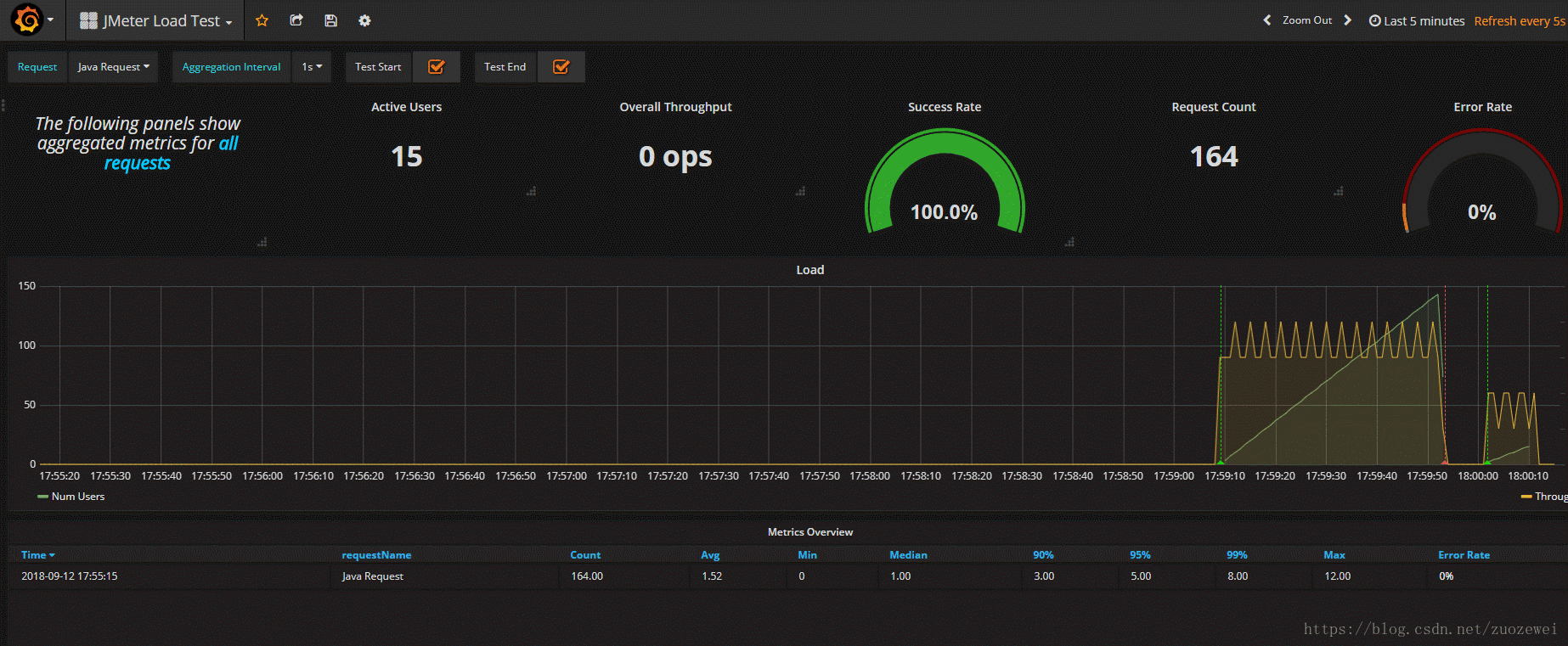
至此,我初步打造的压测可视化实时监控大功告成~