1.登录页面需要有二维码:
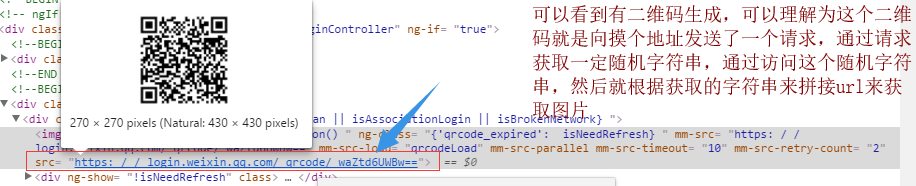
根据在network中查找,找到和他相关的内容

如果想要获取那些数据就要访问这个url

此url需要如何拼接,
登录渲染出二维码的flask代码
#encoding=utf-8 from flask import Flask,request,render_template,request,session,jsonify import time import re import requests app=Flask(__name__) app.debug=True app.secret_key='aa' @app.route('/login',methods=["GET","POST"]) def login(): if request.method=="GET": ctime= time.time() a=str(int(ctime*1000)) #微信登录页面是 #获取url url="https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%
2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_={0}".format(a) # print('*'*50,url) #通过访问此地址,获取返回值,在返回值中获取那个字段,拼接到 登录 login.html中的 img标签的 # src标签里表就能在页面中渲染出获取的二维码 ret=requests.get(url) ret1=ret.text #使用正则来吧数据取出来 c=re.findall('uuid = "(.*)";',ret1)[0] #当检查是否扫码的时候,会用到这个值,由于Flask是上下文管理的形式,能够保存的数据只有保存在session中, session["c"]=c return render_template('login.html',c=c,) else: pass
login.html初级代码
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> <style> </style> </head> <body> <div style=" 200px;margin: 0 auto"> <h3 style="text-align: center">微信登录</h3> <!--通过看微信网页版登录页面可以得知,二维码这个图片的src是这个值,只是最后的数据发生了变化--> <img id="img" style=" 200px;height: 200px" src="https://login.weixin.qq.com/qrcode/{{c}}" alt=""> </div> </body> </html>
继续:
功能一:我这个也页面需要实时的检测用户是否扫码
功能实现
参照微信扫码前后数据变化可以得知
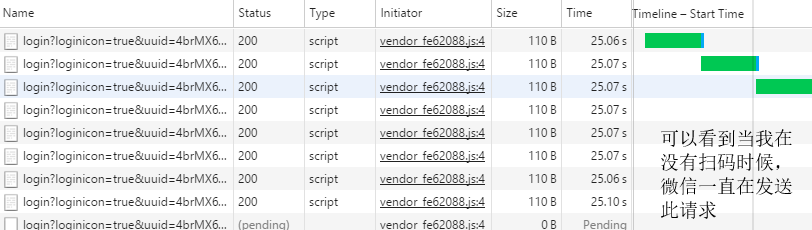
点进去看一下 :这里用到了一个长轮询的机制:优点:轮询和长轮询
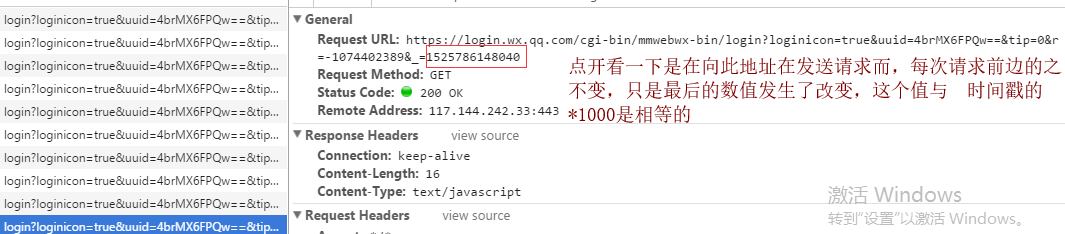
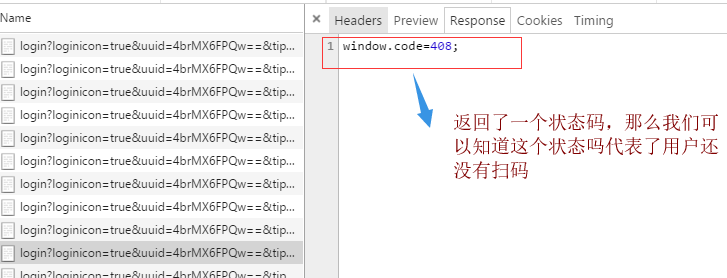
当用户扫码之但是没有在手机上确认登录的时候
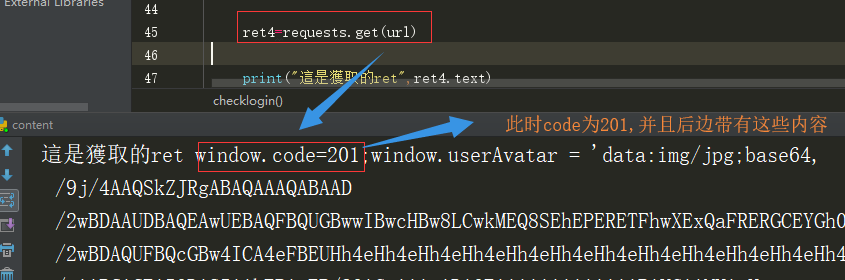
扫码之后,但是没有确认登录页面上显示的内容如下,将用户的头像替代了二维码

检查用户是否扫码,是否登录的代码

#encoding=utf-8 from flask import Flask,request,render_template,request,session,jsonify import time import re import requests app=Flask(__name__) app.debug=True app.secret_key='aa' @app.route('/login',methods=["GET","POST"]) def login(): if request.method=="GET": ctime= time.time() a=str(int(ctime*1000)) #微信登录页面是 #获取url url="https://login.wx.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=zh_CN&_={0}".format(a) # print('*'*50,url) #通过访问此地址,获取返回值,在返回值中获取那个字段,拼接到 登录 login.html中的 img标签的 # src标签里表就能在页面中渲染出获取的二维码 ret=requests.get(url) ret1=ret.text #使用正则来吧数据取出来 c=re.findall('uuid = "(.*)";',ret1)[0] #当检查是否扫码的时候,会用到这个值,由于Flask是上下文管理的形式,能够保存的数据只有保存在session中, session["c"]=c return render_template('login.html',c=c,) else: pass @app.route('/checklogin',methods=["GET","POST"]) def checklogin(): #这边创建一个字典:并将code的值默认设置为408,表示用户未扫码, response={"code":408} import time time.sleep(2) ctime = time.time() a = str(int(ctime * 1000)) #获取当前的时间戳的1000倍的值,这里注意要将内容转换成字符串类型用于拼接url c=session.get("c") # print("这是获取的ac",a,c) # URL:https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid=QcksT_RRig==&tip=0&r=-1055866945&_=1525769055588" url="https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid={0}&tip=0&r=-1055866945&_={1}".format(c,a) #去服务器端去访问并获取数据: 通过微信官网观察 # 如果没扫描,code为408 扫描未登录 code:201 扫描登录 code:200 # 而且这些数据是手机扫码手机将数据发送给服务端,然后服务端改变code ret4=requests.get(url) print("這是獲取的ret",ret4.text) if "code=201" in ret4.text: print('用戶已掃碼') #从发送会的数据中获取用户头像的url src=re.findall("userAvatar = '(.*)';",ret4.text) response["code"]=201 #将url保存在response中返回给客户端 response["src"]=src # return response elif "code=200" in ret4.text: response["code"] = 200 print(ret4.text) #当用户确定登录后,访问的地址 currenturl=re.findall('redirect_uri="(.*)";',ret4.text)[0]+"&fun=new&version=v2" ret5=requests.get(currenturl) print('這是ret5的内容',ret5) from bs4 import BeautifulSoup soup=BeautifulSoup(ret5.text,'html.parser') # soup.find(ret5.text,recursive) #从返回值中获取内容,将内容拼接到字典中去,用于渲染出用户登录后的初始数据 error=soup.find(name='error') print(error) items=error.find_all(recursive=False) print(items) dict1={} for item in items: dict1[item.name]=item.text print(dict1) #将字典内容写到session中去,在显示页面中显示用户的初始信息 session["dict1"]=dict1 print('登陸成功') else: print('用戶為掃碼') #返回一个json类型的数据(字典类型的) return jsonify(response) @app.route('/index',methods=["GET","POST"]) #渲染用户信息页面 def index(): d1=session.get('dict1') #通过视频可以知道渲染出数据需要将资格字典穿过去, dict = {"BaseRequest":{"Uin":d1.get("wxuin"), "Sid": d1.get("wxsid"), "Skey": d1.get("skey"), "DeviceID":"e108769709273733", }} #发送一个post请求,把内容传过去。 ret6=requests.post("https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=-1067834323&pass_ticket={0}".format(d1.get("pass_ticket")), json=dict, ) ret6.encoding=ret6.apparent_encoding import json dd=json.loads(ret6.text) print(dd) return render_template('index.html',data=dd.get('User')) if __name__ == '__main__': app.run()
lgoin html页面
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> <style> </style> </head> <body> <div style=" 200px;margin: 0 auto"> <h3 style="text-align: center">微信登录</h3> <!--通过看微信网页版登录页面可以得知,二维码这个图片的src是这个值,只是最后的数据发生了变化--> <img id="img" style=" 200px;height: 200px" src="https://login.weixin.qq.com/qrcode/{{c}}" alt=""> </div> <script src="../static/jquery-1.12.4.js"></script> <script> $(function () { checklogin(); }); function checklogin() { $.ajax({ url:'/checklogin', type:'GET', // 获取的数据类型为json格式,接受后不用再解码 dataType:'JSON', success:function (arg) { if(arg.code===201){ console.log(arg.src); $("#img").attr("src",arg.src); checklogin() }else if(arg.code===200){ location.href='/index' }else{checklogin()} } }) } </script> <!--https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid=wf4SqxD0tA==&tip=0&r=-1051590008&_=1525764953929--> </body> </html>
index页面
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> {{data.NickName}} </body> </html>