在研究前辈们写的代码,总是搞不明白。word文中引文的索引和引文列表中的索引对应关系是什么呢?是如何对应上的?我冥思苦想,昨天又系统地看了下代码,才所有悟,所以记录下我的探索过程。
如下图所示:

图1

图2
图1,是word文中引文,图2是题录引文列表,红色的是索引,这两个索引是要一一对应的。
这段代码实现的功能:过滤掉bib_List的重复项,然后初始化内存题录表。
1 //bib_List 是题录列表,Globals.BibTableAccessor._dictBibs是内存题录列表字典,用来存储word文档的题录列表。 2 for (int i = 0; i < bib_List.Count; i++) 3 { 4 if (!bib.Contains(bib_List[i])) 5 { 6 bib.Add(bib_List[i]); 7 } 8 } 9 Globals.BibTableAccessor._dictBibs[Globals.MemoryDataKey] = bib;
1 Int32 i_BIndex=1; 2 for (int i = 0; i < bib_List.Count; i++) 3 { 4 //初始化格式化内存表记录 5 MemoryData memData = new MemoryData(); 6 memData.BPhysicsID = i_BIndex; 7 if (existBibs.ContainsKey(bib_List[i].BibliographyId)) 8 { 9 //若有重复处理 10 } 11 else 12 { 13 memData.BLogicID = i_BIndex; 14 i_BIndex++; 15 } 16 }
图1中的索引是根据 memData.BLogicID生成的,我们再看看引文列表的索引是根据什么生成的?
1 if (Globals.BibTableAccessor._dictBibs.ContainsKey(Globals.MemoryDataKey)) 2 { 3 List<Bibliography> unquieBibliographies = this.GetUniqueBibliographies(Globals.BibTableAccessor._dictBibs[Globals.MemoryDataKey]); 4 this.CreateaReferencesList(cache, unquieBibliographies, journalStyle, wordStyle); 5 }
从上面的代码可以看到 unquieBibliographies 这个来源正是内存中的题录表,第4行代码,正是实现引文列表的,它的内部实现是循环内存题录表,然后根据循环的i变量来生成引文列表索引。
到这里,我就想,文中引文索引和引文列表的索引,都是和内存题录表的存储顺序相关。那如果内存题录表在第二次使用的时候,它的顺序会不会变化?于是一个大胆的想法产生了:这个内存题录表,在c#中是一个泛型List,那List的存储在不排序的情况下到底会不会变呢?List是不是按我们Add的顺序存储,然后就不变呢?
为了揭开这些问题的答案,我偷偷地看了下List底层到底是怎么实现的?
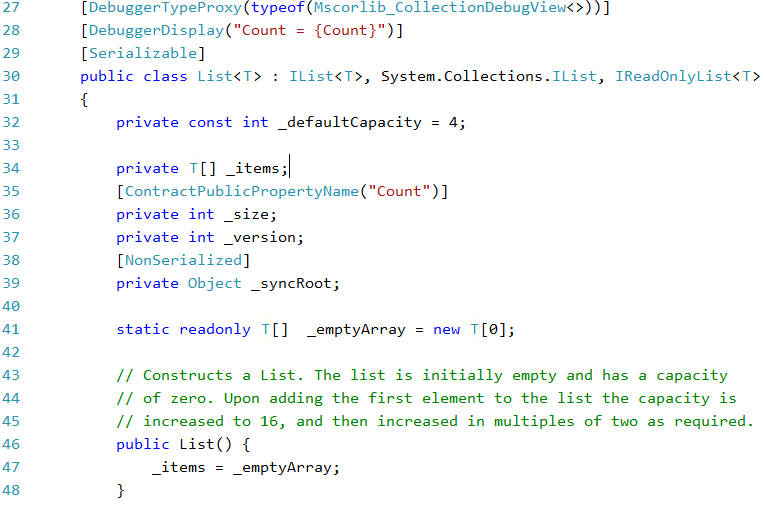
看到构造函数里面,原来是构造了一个空的数组,默认容量是4。难怪以前比较厉害的同学,告诫我们给List适当地初始容量,这样会提供List效率。当时,一脸懵逼,为什么呢?现在看了代码才明白,
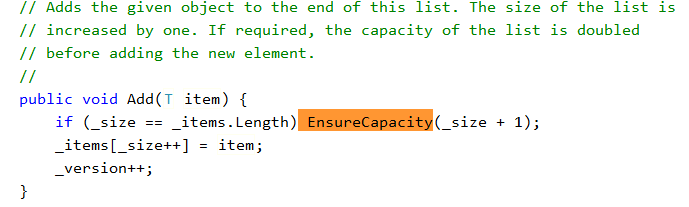
当我们Add一个元素的时候,判断如果当前数组大小和元素的个数相等时,这时候要扩容,按照2倍的规则扩容的:
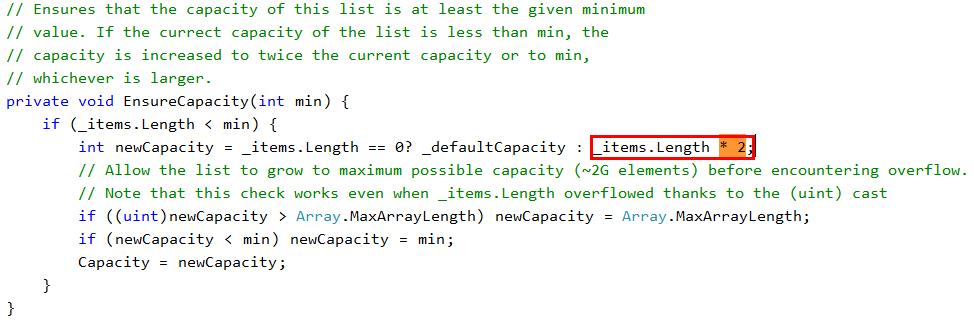
其实,我觉得执行这个扩容代码倒不耗费什么性能。真正耗费性能的,应该是不断地向内存申请存储空间,我觉得这个事情应该耗费性能。按照我的想法,就算申请存储空间也不耗费性能,那微软会怎么做呢?是在原来数组的基础上扩展容量,还是新实例化了一个数组,把原来的数组元素拷贝过去?
我们继续研究代码,此刻我是一边写,一边研究,还没有吃中午饭。
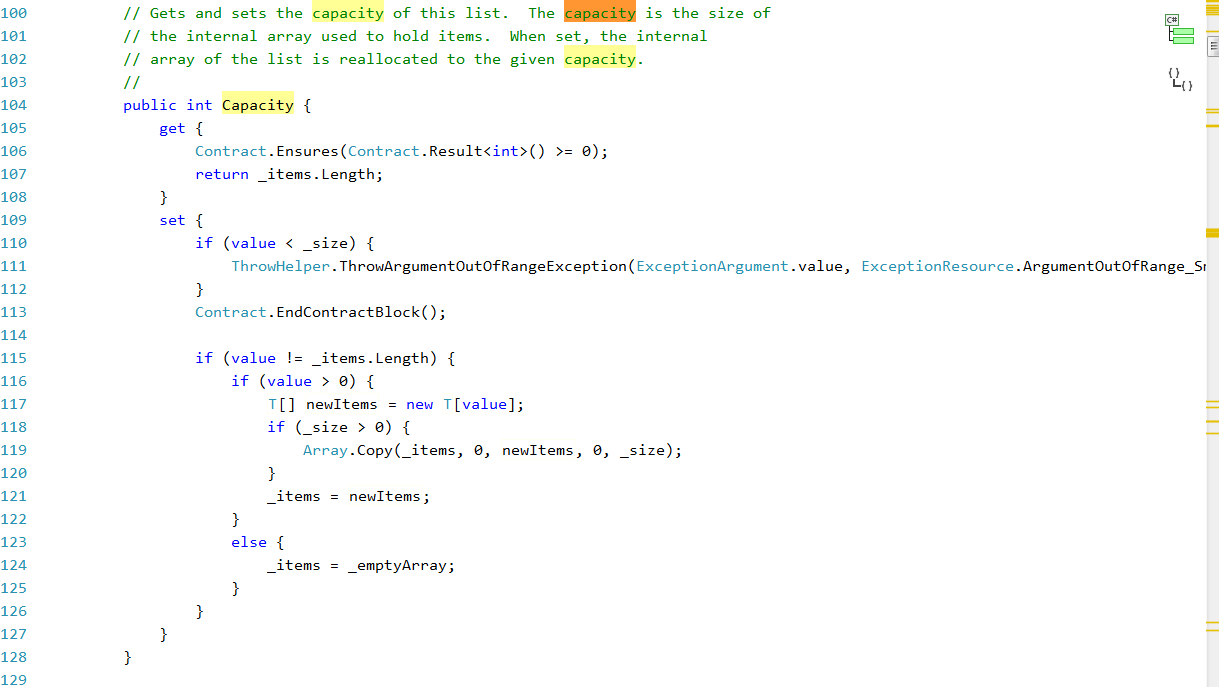
看到这里的代码,我觉得一阵欣喜,微软的做法,就是新构造了一个数组,把元素拷贝过去。那为什么不在原来的基础上扩容呢?我想了想,所谓数组,就是一组连续的存储空间,那微软要在原来的基础上扩展,何谈容易呢?万一这段空间周边没有空间呢?那就干脆把这样的困难的事情交给操作系统完成好了。