1.创建数据库

![]()
说明:hive的表存放位置模式是由hive-site.xml当中的一个属性指定的,在这个文件中还规定了文件的访问权限
创建指定路径的数据库

设置数据库键值对信息

2.删除数据库

这个命令只能删除空数据库,强制删除数据库连带下面的表一起删除可以在后面加一个参数:cascade
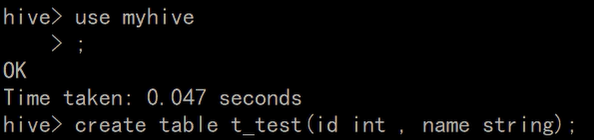
3.创建表
建表语法:

external:创建一个外部表。在删除外部表时只删除元数据不删除表中的数据。
comment:注释,默认不能使用英文
partitioned by:表示使用分区,一个表可以使用多个分区,每一个分区单独存在一个目录下
clustered by:分桶。类似于MapReduce的分区
sorted by:指定排序字段和排序规则
row format:指定表文件字段分隔符
storted as:指定表文件的存储格式。
textfile:默认格式;存储方式为行存储;磁盘开销大 数据解析开销大;但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
sequencefile:二进制文件,以<key,value>的形式序列化到文件中;存储方式:行存储;可分割 压缩;一般选择block压缩; 优势是文件和Hadoop api中的 mapfile是相互兼容的
refile:存储方式:数据按行分块 每块按照列存储;压缩快 快速列存取;读记录尽量涉及到的block最少;读取需要的列只需要读取每个row group 的头部定义;读取全量数据的操作 性能可能比sequencefile没有明显的优势
location:指定表文件的存储路径