转载自 huxihx,原文链接 Kafka producer介绍
Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer。本文着重讨论新版本producer的设计原理以及基本的使用方法。
目录
一、基本数据结构
1. ProducerRecord
2. RecordMetadata
二、工作流程
1. 基本设计特点
2. 关键参数
3. 内部原理
3.1 Step 1: 序列化+计算目标分区
3.2 Step 2: 追加写入消息缓冲区(accumulator)
3.3 Step 3: Sender线程预处理及消息发送
3.4 Step 4: Sender线程处理response
三、基本使用
新版本Producer
首先明确一下,新版本producer指的是o.a.k.clients.producer.KafkaProducer,而不是kafka.producer.Producer。如果你依然在使用后者,我们强烈建议你赶快升级到Kafka0.9以后的版本。
一、基本数据结构
新版本客户端(包含新版本producer和新版本consumer)重写了之前服务器端代码提供的很多数据结构以摆脱对服务器端代码的依赖。其中有一些是你理解新版本producer所必需的,它们包括(但不限于):
1. ProducerRecord
一个ProducerRecord表示一条待发送的消息记录,主要由5个字段构成:
- topic 所属topic
- partition 所属分区
- key 键值
- value 消息体
- timestamp 时间戳
ProducerRecord允许用户在创建消息对象的时候就直接指定要发送的分区,这样producer后续发送该消息时可以直接发送到指定分区,而不用先通过Partitioner计算目标分区了。另外,我们还可以直接指定消息的时间戳——但一定要慎重使用这个功能,因为它有可能会令时间戳索引机制失效(笔者曾经直接指定时间戳故意打乱发送顺序进行测试,比如先发送消息的时间戳大于后发送消息的时间戳,最后发现通过时间戳定位消息时会发生混乱。为此我还特意开了一个jira issue,不过被认为是"当前不被支持的用法")
2. RecordMetadata
该类表示Kafka服务器端返回给客户端的消息的元数据信息,包含以下内容:
- offset 该条消息的位移
- timestamp 消息时间戳
- topic + partition 所属topic的分区
- checksum 消息CRC32码
- serializedKeySize 序列化后的消息键字节数
- serializedValueSize 序列化后的消息体字节数
上面的元数据信息前3项信息是比较重要的,producer端可以使用这些信息做一些消息发送成功之后的处理,比如写入日志等。
二、工作流程
如果把Producer统一看成一个盒子,那么整个producer端的工作原理便如下图所示:
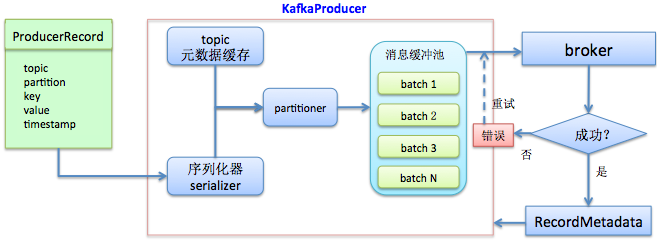
大体上来说,用户首先构建待发送的消息对象ProducerRecord,然后调用KafkaProducer#send方法进行发送。KafkaProducer接收到消息后首先对其进行序列化,然后结合本地缓存的元数据信息一起发送给partitioner去确定目标分区,最后追加写入到内存中的消息缓冲池(accumulator)。此时KafkaProducer#send方法成功返回。
KafkaProducer中还有一个专门的Sender IO线程负责将缓冲池中的消息分批次发送给对应的broker,完成真正的消息发送逻辑。
1. 基本设计特点
结合源代码,笔者认为新版本的producer从设计上来说具有以下几个特点(或者说是优势):
- 总共创建两个线程:执行KafkaPrducer#send逻辑的线程——我们称之为“用户主线程”;执行发送逻辑的IO线程——我们称之为“Sender线程”
- 不同于Scala老版本的producer,新版本producer完全异步发送消息,并提供了回调机制(callback)供用户判断消息是否成功发送
- batching机制——“分批发送“机制。每个批次(batch)中包含了若干个PRODUCE请求,因此具有更高的吞吐量
- 更加合理的默认分区策略:对于无key消息而言,Scala版本分区策略是一段时间内(默认是10分钟)将消息发往固定的目标分区,这容易造成消息分布的不均匀,而新版本的producer采用轮询的方式均匀地将消息分发到不同的分区
- 底层统一使用基于Selector的网络客户端实现,结合Java提供的Future实现完整地提供了更加健壮和优雅的生命周期管理。
其实,新版本producer的设计优势还有很多,诸如监控指标更加完善等这样的就不一一细说了。总之,新版本producer更加地健壮,性能更好~
2. 关键参数
新版本producer的参数有几十个之多,我们重点了解其中的6个就够了,它们是:
- batch.size 我把它列在了首位,因为该参数对于调优producer至关重要。之前提到过新版producer采用分批发送机制,该参数即控制一个batch的大小。默认是16KB
- acks 关乎到消息持久性(durability)的一个参数。高吞吐量和高持久性很多时候是相矛盾的,需要先明确我们的目标是什么? 高吞吐量?高持久性?亦或是中等?因此该参数也有对应的三个取值:0, -1和1
- linger.ms 减少网络IO,节省带宽之用。原理就是把原本需要多次发送的小batch,通过引入延时的方式合并成大batch发送,减少了网络传输的压力,从而提升吞吐量。当然,也会引入延时
- compression.type producer所使用的压缩器,目前支持gzip, snappy和lz4。压缩是在用户主线程完成的,通常都需要花费大量的CPU时间,但对于减少网络IO来说确实利器。生产环境中可以结合压力测试进行适当配置
- max.in.flight.requests.per.connection 关乎消息乱序的一个配置参数。它指定了Sender线程在单个Socket连接上能够发送未应答PRODUCE请求的最大请求数。适当增加此值通常会增大吞吐量,从而整体上提升producer的性能。不过笔者始终觉得其效果不如调节batch.size来得明显,所以请谨慎使用。另外如果开启了重试机制,配置该参数大于1可能造成消息发送的乱序(先发送A,然后发送B,但B却先行被broker接收)
- retries 重试机制,对于瞬时失败的消息发送,开启重试后KafkaProducer会尝试再次发送消息。对于有强烈无消息丢失需求的用户来说,开启重试机制是必选项。
3. 内部原理
上面的那张图中其实并没有深入展开producer的工作原理。这里笔者打算详细说说Producer内部到底是如何工作的,也就是梳理一下当用户调用KafkaProducer.send(ProducerRecord, Callback)时Kafka内部都发生了什么事情。
3.1 Step 1: 序列化+计算目标分区
这是KafkaProducer#send逻辑的第一步,即为待发送消息进行序列化并计算目标分区,如下图所示:

如上图所示,一条所属topic是"test",消息体是"message"的消息被序列化之后结合KafkaProducer缓存的元数据(比如该topic分区数信息等)共同传给后面的Partitioner实现类进行目标分区的计算。
3.2 Step 2: 追加写入消息缓冲区(accumulator)
producer创建时会创建一个默认32MB(由buffer.memory参数指定)的accumulator缓冲区,专门保存待发送的消息。除了之前在“关键参数”段落中提到的linger.ms和batch.size等参数之外,该数据结构中还包含了一个特别重要的集合信息:消息批次信息(batches)。该集合本质上是一个HashMap,里面分别保存了每个topic分区下的batch队列,即前面说的批次是按照topic分区进行分组的。这样发往不同分区的消息保存在对应分区下的batch队列中。举个简单的例子,假设消息M1, M2被发送到test的0分区但属于不同的batch,M3分送到test的1分区,那么batches中包含的信息就是:{"test-0" -> [batch1, batch2], "test-1" -> [batch3]}
单个topic分区下的batch队列中保存的是若干个消息批次。每个batch中最重要的3个组件包括:
- compressor: 负责执行追加写入操作
- batch缓冲区:由batch.size参数控制,消息被真正追加写入到的地方
- thunks:保存消息回调逻辑的集合
这一步的目的就是将待发送的消息写入消息缓冲池中,具体流程如下图所示:
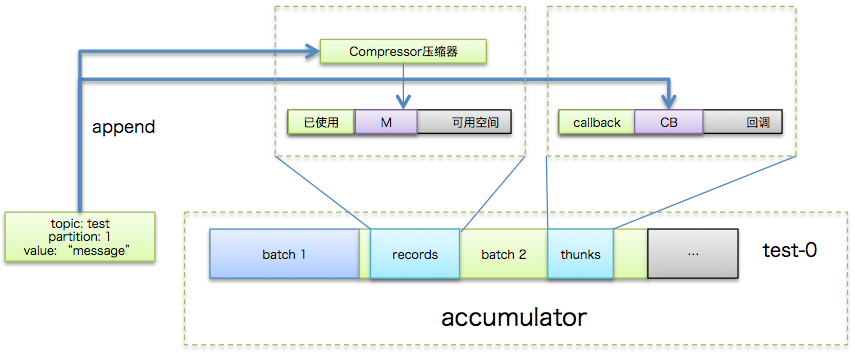
okay!这一步执行完毕之后理论上讲KafkaProducer.send方法就执行完毕了,用户主线程所做的事情就是等待Sender线程发送消息并执行返回结果了。
3.3 Step 3: Sender线程预处理及消息发送
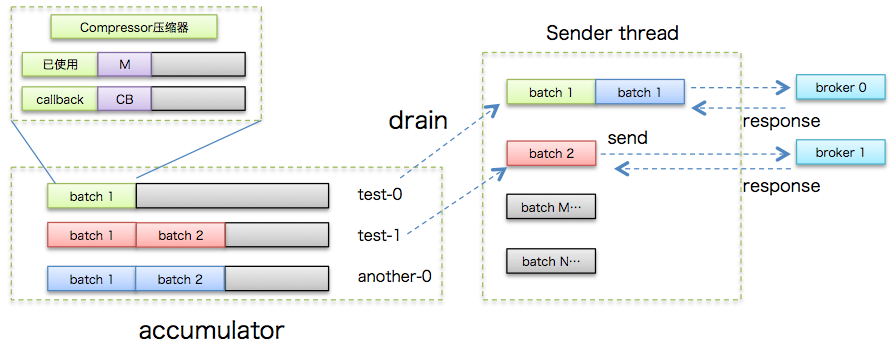
此时,该Sender线程登场了。严格来说,Sender线程自KafkaProducer创建后就一直都在运行着 。它的工作流程基本上是这样的:
- 不断轮询缓冲区寻找已做好发送准备的分区
- 将轮询获得的各个batch按照目标分区所在的leader broker进行分组
- 将分组后的batch通过底层创建的Socket连接发送给各个broker
- 等待服务器端发送response回来
为了说明上的方便,我还是基于图的方式来解释Sender线程的工作原理:
3.4 Step 4: Sender线程处理response
上图中Sender线程会发送PRODUCE请求给对应的broker,broker处理完毕之后发送对应的PRODUCE response。一旦Sender线程接收到response将依次(按照消息发送顺序)调用batch中的回调方法,如下图所示:

做完这一步,producer发送消息就可以算作是100%完成了。通过这4步我们可以看到新版本producer发送事件完全是异步过程。因此在调优producer前我们就需要搞清楚性能瓶颈到底是在用户主线程还是在Sender线程。具体的性能测试方法以及调优方法以后有机会的话我再写一篇出来和大家讨论。
三、基本使用
由于KafkaProducer是线程安全的,因此在使用上有两种基本的使用方法:
| 说明 | 优势 | 劣势 | |
|
单KafkaProducer实例 |
所有线程共享一个KafkaProducer实例 |
实现简单,性能好 |
1. 所有线程共用一个内存缓存池,可能需要较多的内存空间 |
| 多KafkaProducer实例 | 每个线程维护一个KafkaProducer实例 |
1. 每个用户线程拥有专属的KafkaProducer实例、缓冲区空间以及一组配置参数,支持细粒度化调优 |
较大的对象分配开销 |
总 结
最后简单总结一下,本文主要讨论了新版本producer的一些设计特点及基本的使用方法。再次强调一下,新版本的producer使用完全异步化的多线程处理方式,同时结合分批处理机制,极大地提升了整体的性能。由于目前Kafka社区早已不维护Scala版producer了,所以还在使用0.8.2.x版本的用户有条件的话尽量还是升级到最新的Kafka版本吧。