正则表达式是一种功强大而灵活的文本处理工具。一般来说,正则表达式就是以某种文本的方式来表述字符串,一次你可以说:“如果一个字符串会有这些东西,那么它就是我们要找的东西”。再好的东西如果使用不当依然会造成灾难性后果。
一天晚上突然收到同事反馈,其使用的一个正责表达式对收货人姓名处理时,输入某种字符不能正确保存,现象为服务端请求卡死,没有response返回给客户端;在测试环境重现该问题时通过jstack获取到的信息可以发现正则表达式在回溯处理,进一步通过RegexBuddy对该段正则表达式分析发现该该段正则表达式处理完成需要超过一百万次匹配如果有恶意用户发现该漏洞,对网站发起ReDoS(Regular expression Denial of Service)攻击(注:根据韩波同学意见修改),可能会引发灾难性的后果。
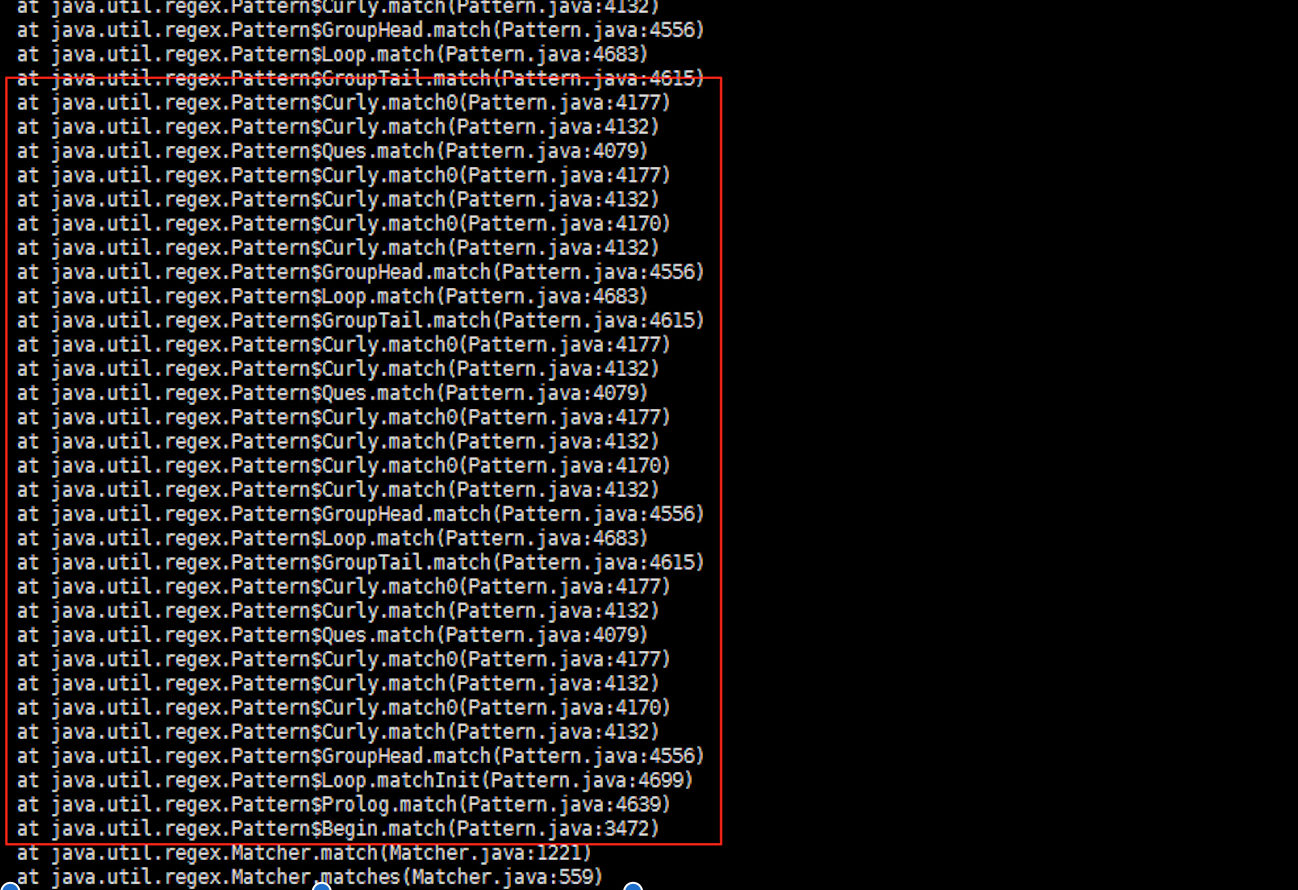
根源
从本质上讲,存在两种不同类型的正则表达式引擎:确定性有穷自动机 (DFA) 引擎和非确定性有穷自动机 (NFA) 引擎. DFA 对于文本串里的每一个字符只需扫描一次,比较快,但特性较少;NFA要翻来覆去吃字符、吐字符,速度慢,但是特性丰富,所以反而应用广泛,当今主要的正则表达式引擎.Java同样采用NFA。
^d+$
如果整个输入字符串仅包含数字字符,则这是一个相当简单的匹配正则表达式。^ 和 $ 字符分别表示字符串的开头和结尾,表达式 d 表示数字字符,+ 指示将有一个或多个字符匹配。我们使用 123456X 作为输入字符串测试此表达式,那么最终又是什么情况呢?同样通过RegexBuddy分析一下,可以发现NFA总共计算出了6个路径:123456、12345、1234、123、12 和 1;经过了20步处理才发现是不符合要求的。下面通过介绍正则表达式的匹配模式去分析一下该如何处理。
正则表达式匹配模式
- 贪婪型
- 勉强型
- 占有型
贪婪型
X?、X*、X+、X{n,}都是最大匹配,上面的例子就是一个贪婪型。
勉强型
X?、X*、X+、X{n,}都是最大匹配。好,加个?就成了Laziness匹配。例如X??、X*?、X+?、X{n,}?都最小匹配。上面的例子如果改为勉强型是不是可以解决问题呢?通过实验发现是解决不了问题的。从上下两幅图中还是可以发现两者的区别的。一个从最大处开始回溯,一个在最小处回溯。
占有型
与最大匹配不同,还有一种匹配形式:X?+、X*+、X++、X{n,}+等,成为完全匹配。它和最大匹配一样,一直匹配所有的字符,直到文本的最后,但它不由原路返回。也就是说,一口匹配,搞不定就算了,到也干脆,偶喜欢;发现解决问题的曙光了。
通过将表达式改为占有型的结果是
问题解决了,那么回过头来,再看开始的问题,如果将其改造为占有型不是就可以解决问题了吗?除了通过上述方式修改以为还可以通过固化分组的方式实现。
最终解决方案是:
^(?>[u4e00-u9fa5|A-Z]+\s*\.?\s*)+[u4e00-u9fa5|A-Z]$