持续完善中……
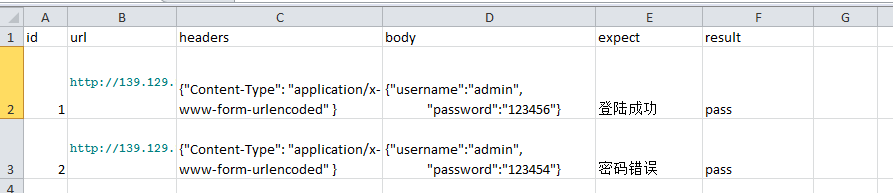
使用python2.7有写过一篇ddt,此处再用3.6写一次,这次把接口headers、url、body、expect、result都写到excle中
目录
1、模块准备
2、读写excle的类
3、使用ddt
1、模块准备
ddt数据驱动模块:
pip install ddt -i https://pypi.tuna.tsinghua.edu.cn/simple

xlrd读取excle模块:
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
openpyxl写excle模块:pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple

2、读写excle的类
读取excle:
- 打开workbook获取Book对象
xlrd.open_workbook(filename[, logfile, file_contents, ...]):打开excel文件
filename:需操作的文件名(包括文件路径和文件名称);
若filename不存在,则报错FileNotFoundError;
若filename存在,则返回值为xlrd.book.Book对象
- 获取Book对象中所有sheet名称
BookObject.sheet_names():获取所有sheet的名称,以列表方式显示
封装读取文件,返回字典对象:
import xlrd
import os
class ExcelUtil():
def __init__(self,exclePath,sheetName="Sheet1"):
self.data=xlrd.open_workbook(exclePath)
self.table=self.data.sheet_by_name(sheetName)
#获取第一行作为key值
self.keys=self.table.row_values(0)
#获取总行数
self.rowNum=self.table.nrows
#获取总列数
self.colNum=self.table.ncols
def dict_data(self):
if self.rowNum<=1:
print ("总行数小于1")
else:
r=[]
j=1
for i in list(range(self.rowNum-1)):
s={}
#从第二行取对应value值
s['rowNum']=i+2
values=self.table.row_values(j)
for x in list(range(self.colNum)):
s[self.keys[x]]=values[x]
r.append(s)
j+=1
return r
if __name__ =="__main__":
cur_path=os.path.abspath("") #获取脚本所在路径
report_path=os.path.join(cur_path,"data.xlsx")#将当前脚本和测试数据放在一个文件夹下
print(report_path)
data=ExcelUtil(report_path)
print(data.dict_data())
# print(data)
写excle:
根据行列找到单元格,然后将值写入单元格,并保存
from openpyxl import load_workbook
import openpyxl
class Write_excel(object):
def __init__(self,filename):
self.filename=filename
self.wb=load_workbook(self.filename)
self.ws=self.wb.active
def write(self,row_n,col_n,value):
self.ws.cell(row_n,col_n).value=value
self.wb.save(self.filename)
if __name__=="__main__":
m2="G:\api\jpress_api\common\data03.xlsx"
wt=Write_excel(m2)
wt.write(1,2,"test")
3、使用ddt
第一步:读取excle的第一行头部信息,data1是通过dict_data()函数获取到字典对象,形如:[{'rowNum': 2, 'id': 1.0, 'url': 'xx', 'headers': 'xxx','body':'xx'}]
通过字典取值方式得到str对象,然后通过eval()再转成dict传入post请求中
url=data1['url'] #url
body=eval(data1['body'])#body
headers=eval(data1['headers']) #headers
expect=data1['expect'] #期望值
注:使用eval函数将str转换成字典类型的值,当然也可以使用json.loads()来转换
第二步:用excle准备数据
第三步:使用ddt模块
ddt模块他会顺序取每一行数据进行执行,就算报错,它也会完成所有组别数据的遍历
import ddt
from common.readexcle import *
import unittest
from common.write_excle import *
import requests
#读取本地的测试数据
datapath="G:\api\jpress_api\common\data01.xlsx"
d=ExcelUtil(datapath)
testdata=d.dict_data() #读excle
wt=Write_excel(datapath) #写excle
@ddt.ddt
class Testme(unittest.TestCase):
def setUp(self):
self.requests=requests
#开始读取用例
@ddt.data(*testdata)
def test(self,data1):
id=data1['id']
url=data1['url'] #url
body=eval(data1['body'])#body
headers=eval(data1['headers']) #headers
expect=data1['expect'] #期望值
result=self.requests.post(url,body,headers=headers)
myresult=result.json()["message"]
#预期结果等于实际结果,则设置用例结果为pass,否则为fail
if myresult==expect:
data1['result']="pass"
else:
data1['result']="fail"
#将用例结果写回到excle中
wt.write(id+1,6,data1['result'])
self.assertEqual(expect,myresult) #实际结果等于预期结果
if __name__=="__main__":
unittest.main()
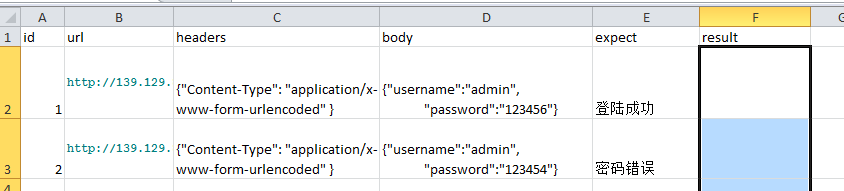
excle结果: