一.简介
Phoenix是HBase的开源SQL皮肤,可以理解为一个HBase的客户端工具。
好处
1)可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据
2)操作简单:DML命令以及通过DDL命令创建和操作表和版本化增量更改;
3)支持HBase二级索引创建。
二.安装
1)官网地址
2)Phoenix部署
(1)上传并解压tar包
[hadoop@hadoop102 module]$ tar -zxvf /opt/software/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module
[hadoop@hadoop102 module]$ mv apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz phoenix
(2)配置环境变量,soure一下
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
(3)复制server包并分发到各个节点的hbase/lib
[hadoop@hadoop102 module]$ cd /opt/module/phoenix/
[hadoop@hadoop102 module]$ cd /opt/module/phoenix/
[hadoop@hadoop102 phoenix]$ cp phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase/lib/
[hadoop@hadoop102 phoenix]$ xsync/opt/module/hbase/lib/
(4)配置文件
修改%Phoenix_HOME%/bin/hbase-site.xml ,然后分发各个HBase节点
<!-- 二级索引相关配置 -->
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name> <value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>false</value>
</property>
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<!-- 开启phoenix对hbase的表的映射 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
修改%HBASE_HOME%/conf/hbase-site.xml文件
<!-- 开启phoenix对hbase的表的映射 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
(5)启动zk,HDFS,Hbase,然后连接Phoenix
[hadoop@hadoop102 phoenix]$ bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
[hadoop@hadoop102 ~]$ sqlline.py hadoop102,hadoop103,hadoop104:2181
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/phoenix/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
20/07/17 18:10:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connected to: Phoenix (version 5.0)
Driver: PhoenixEmbeddedDriver (version 5.0)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
148/148 (100%) Done
Done
sqlline version 1.2.0
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104>
三.Phoenix Shell操作
语法操作可参考官网:https://phoenix.apache.org/language/index.html#
在phoenix中,默认情况下,库名,表名,字段名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
SCHEMA操作
Phoenix中将HBase的namespace叫做SCHEMA,想到于mysql中的库的概念。
1.创建schema
CREATE SCHEMA IF NOT EXISTS "库名"
2.使用schema
USE "库名"
默认表
USE DEFAULT
3.删除schema
DROP SCHEMA "库名" --前提表都删完。
表操作
创建一个新表。如果
HBase表和所引用的列族不存在,则将创建它们。在创建时,为了提高查询性能,如果没有明确定义任何列族,则将一个空键值作为默认列族
1.显示所有表
!table

2.创建表

Hbase中不存在表名相同的表,不然就成了映射HBase的表。
CREATE TABLE IF NOT EXISTS "student"(
id VARCHAR primary key,
name VARCHAR,
age VARCHAR);
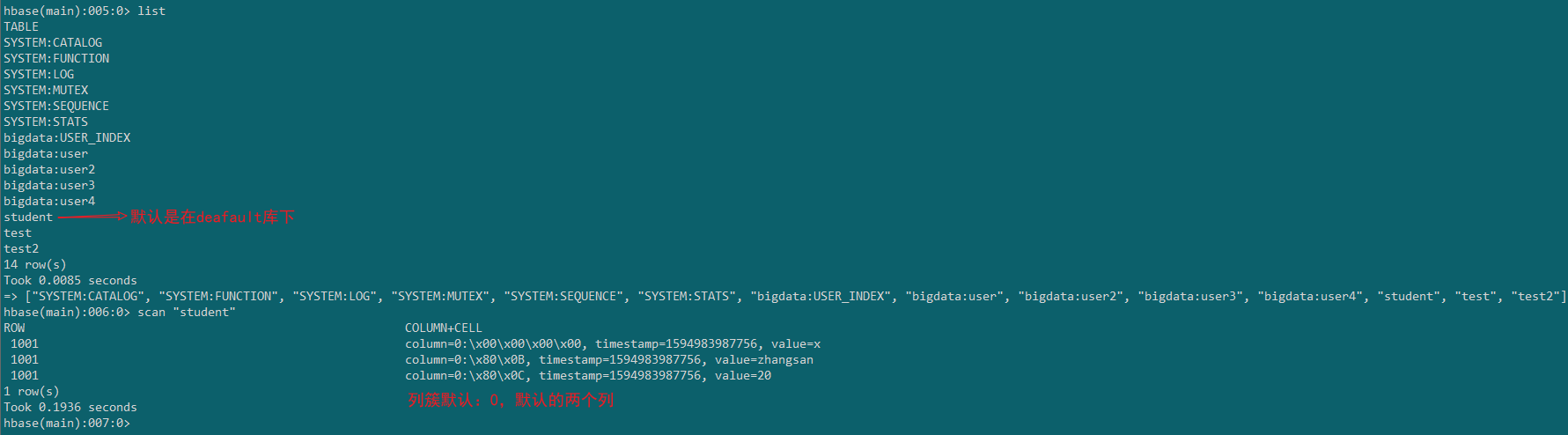
3.表数据的增删改查
upsert into "student" values('1001','zhangsan','20');
upsert into "student" values('1002','lisi','22');
select * from "student" ;
delete from "student" where id='1002';

注意:
1)upsert:表中的主键不存在就是插入,存在就是更新
2)where的字段值要加单引号 ' ', 字段名的小写是加双引号,别弄混了
对比Hbase中的表结构看一下
4.删除表
drop table student;
5.退出命名行
!quit
表映射
默认情况下,直接在Hbase中创建的表,通过phoenix是查看不到的。如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射
在Hbase中创建测试表:(命名空间:bigdata , 表名:map_test)
表结构
| info1 | info2 | |
|---|---|---|
| rowkey | name | address |
| 1001 | zhangsan | BeiJing |
| 1002 | lisi | ShenZhen |
$ cd /home/hadoop/hbase/bin
$ ./hbase shell 进入hbase命令行
hbase(main):008:0> create 'bigdata:map_test','info1','info2'
hbase(main):011:0> put 'bigdata:map_test','1001','info1:name','zhangsan'
hbase(main):012:0> put 'bigdata:map_test','1001','info1:address','BeiJing'
hbase(main):013:0> put 'bigdata:map_test','1002','info1:name','lisi'
hbase(main):014:0> put 'bigdata:map_test','1002','info2:address','ShenZhen'
#Scan验证一下
hbase(main):015:0> scan 'bigdata:map_test'
ROW COLUMN+CELL
1001 column=info1:address, timestamp=1594985273813, value=BeiJing
1001 column=info1:name, timestamp=1594985243947, value=zhangsan
1002 column=info1:name, timestamp=1594985290799, value=lisi
1002 column=info2:address, timestamp=1594985311918, value=ShenZhen
1.视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。
1)创建视图
create view"bigdata"."map_test"(
"empid" varchar primary key,
"info1"."name" varchar,
"info2"."adress"varchar);
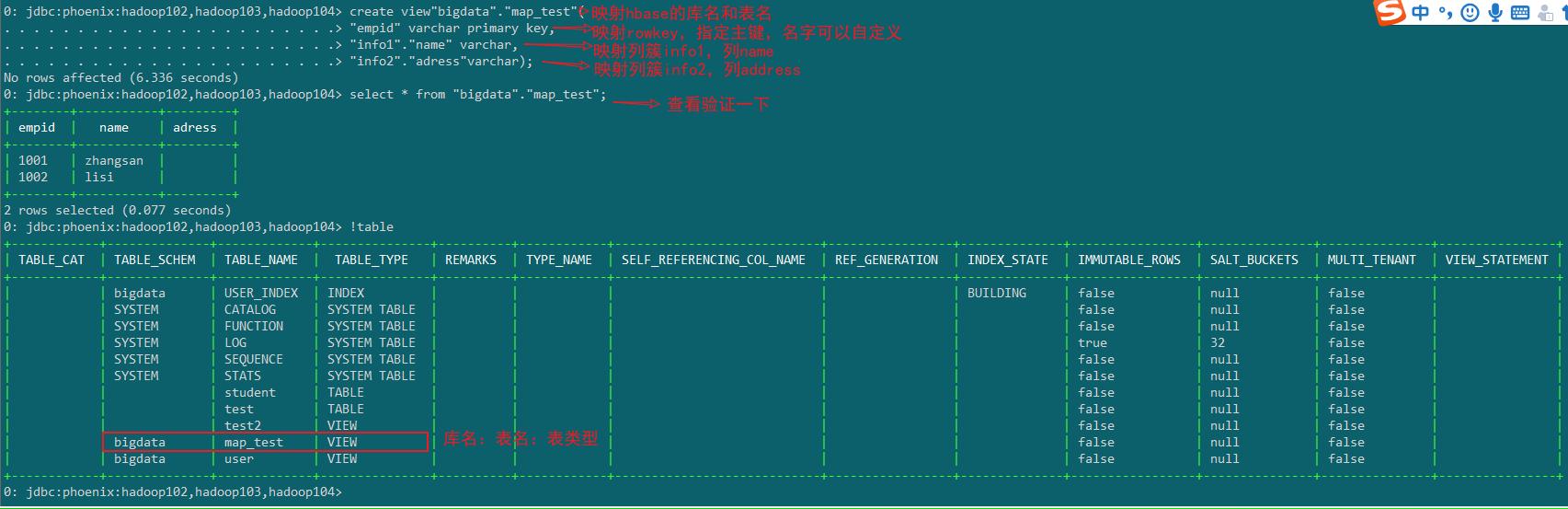
2)删除视图
drop view "bigdata"."map_test";
注意=:创建视图前,如果HBase不是在默认命名空间,需要在Phoenix创建对应的Schema。
2.表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
a)当HBase中不存在表时,可以直接使用create table指令创建需要的表,系统将会自动在Phoenix和HBase中创建表,并会根据指令内的参数对表结构进行初始化。
b)当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
注意后面加column_encoded_bytes=0,不然Phoenix用自己的编码列的值就无法查看。
错误示例

正确示例
比较坑,如果创建错了,重新映射的话,只能删除映射表,会把HBase的表也删 了。所以不要创建错......
create table "bigdata"."map_test"(
"empid" varchar primary key,
"info1"."name" varchar,
"info2"."adress"varchar)column_encoded_bytes=0;

四.Phoenix Java API 操作
pom依赖
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.0.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
操作Phoenix
package com.bigdata.phoenix;
import org.apache.phoenix.queryserver.client.Driver;
import org.apache.phoenix.queryserver.client.ThinClientUtil;
import org.junit.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class PhoenixDemo {
@Test
public void createTable() throws Exception{
//1、加载驱动
Class.forName("org.apache.phoenix.queryserver.client.Driver");
//2、获取连接
String url = ThinClientUtil.getConnectionUrl("hadoop102", 8765);
System.out.println(url);
Connection connection = DriverManager.getConnection(url);
//3、创建Statement对象
String sql = "create table xxx(" +
"id varchar primary key," +
"name varchar," +
"age varchar)COLUMN_ENCODED_BYTES=0";
PreparedStatement statement = connection.prepareStatement(sql);
//4、执行sql操作
statement.execute();
//5、关闭
statement.close();
connection.close();
}
/**
*
* @throws Exception
*/
@Test
public void insert() throws Exception{
//1、加载驱动
Class.forName("org.apache.phoenix.queryserver.client.Driver");
//2、获取连接
String url = ThinClientUtil.getConnectionUrl("hadoop102", 8765);
System.out.println(url);
Connection connection = DriverManager.getConnection(url);
//connection.setAutoCommit(true);
//3、获取statement对象
PreparedStatement statement = connection.prepareStatement("upsert into xxx values(?,?,?)");
//4、给参数赋值
statement.setString(1,"1001");
statement.setString(2,"zhangsan");
statement.setString(3,"20");
//5、执行插入
statement.execute();
connection.commit();
//6、关闭
statement.close();
connection.close();
}
@Test
public void query() throws Exception{
//1、加载驱动
Class.forName("org.apache.phoenix.queryserver.client.Driver");
//2、获取连接
String url = ThinClientUtil.getConnectionUrl("hadoop102", 8765);
System.out.println(url);
Connection connection = DriverManager.getConnection(url);
//connection.setAutoCommit(true);
//3、获取statement对象
PreparedStatement statement = connection.prepareStatement("select * from xxx");
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()){
String id = resultSet.getString("id");
String name = resultSet.getString("name");
String age = resultSet.getString("age");
System.out.println("id="+id+",name="+name+",age="+age);
}
statement.close();
connection.close();
}
}
五.二级索引
思考:为啥建立二级索引?
现在有一个map_test表
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> select * from "map_test";
+--------+-----------+------------+
| empid | name | adress |
+--------+-----------+------------+
| 1001 | zhangsan | BeiJing |
| 1002 | lisi | ShenZhen |
| 1003 | wangwu | GuangZhou |
+--------+-----------+------------+
对于Hbase,如果想精确定位到某行记录,唯一的办法就是通过rowkey查询。如果不通过rowkey查找数据,就必须逐行比较每一行的值,对于较大的表,全表扫描的代价是不可接受的。
没建立索引前:
当我们针对某一列的值进行查询的话,如name=“zhangsan”,没建立二级索引之前只能全表扫描过滤。

建立索引后:
那么我们可以针对map_test表建议对应得索引表。
create index "map_test_index" on "bigdata"."map_test" ("info1"."name");
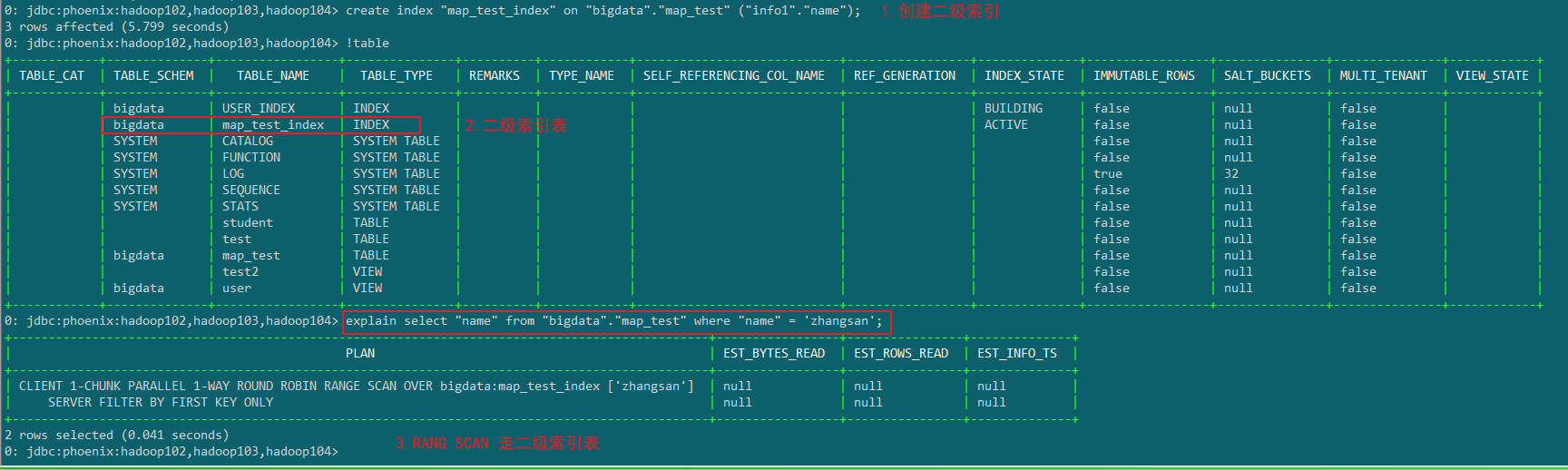
全局索引
Global Index是默认的索引格式,创建全局索引时,会在HBase中建立一张新表。也就是说索引数据和数据表是存放在不同的表中的,因此全局索引适用于多读少写的业务场景。
写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。

1)创建单个字段的全局索引
CREATE INDEX my_index ON my_table (my_col);
示例:
create index "map_test_index" on "bigdata"."map_test" ("info1"."name");
2)创建携带其他字段的全局索引
CREATE INDEX my_index ON my_table (v1) INCLUDE (v2);
示例:
create index "map_test_index" on "bigdata"."map_test" ("info1"."name") include ("info2"."adress");
3)删除索引表
示例:
drop index map_test_index on "bigdata"."map_test";
去Hbase中看一下

可以发现创建了两张表,索引表的的rowkey=索引字段的值+原表的rowkey,Value是inclue的列值
本地索引
Local Index适用于写操作频繁的场景。
索引数据和数据表的数据是存放在同一张表中(且是同一个Region),避免了在写操作的时候往不同服务器的索引表中写索引带来的额外开销。查询的字段不是索引字段索引表也会被使用,这会带来查询速度的提升。

创建:local关键字
create index "map_test_index" on "bigdata"."map_test" ("info1"."name");
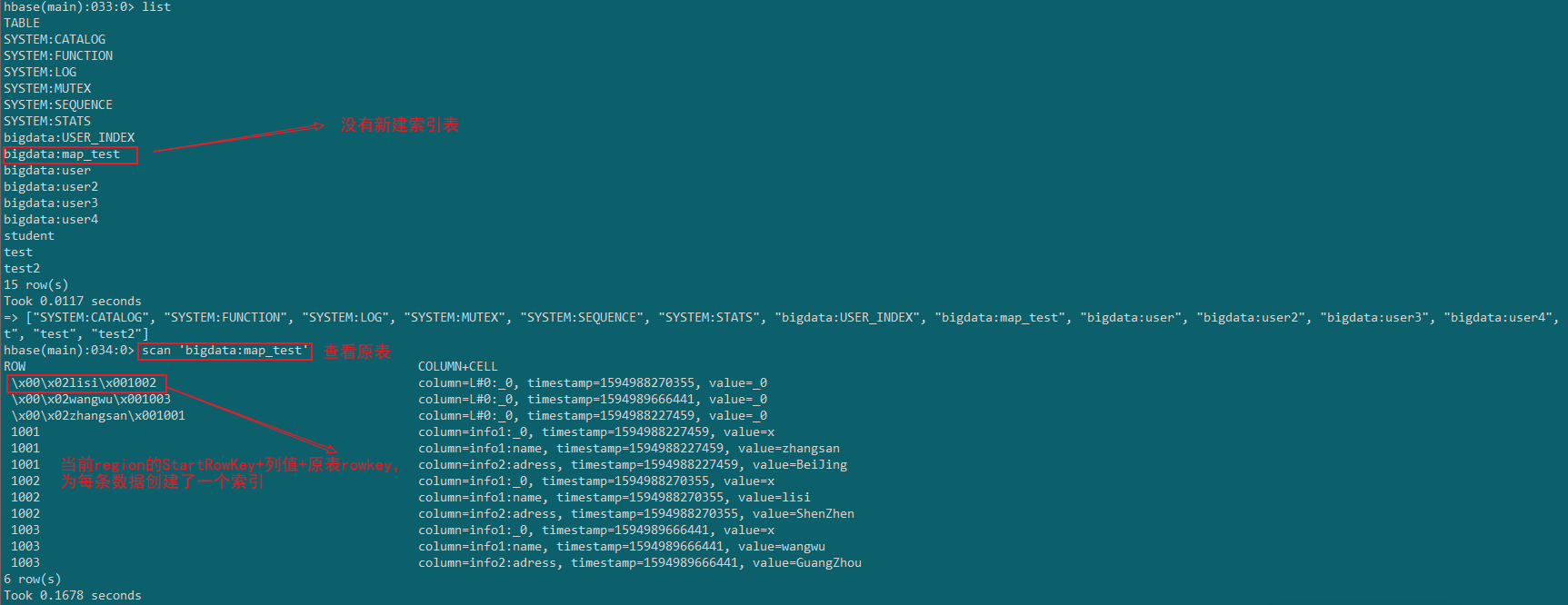
去Hbase中看一下
可以发现在Hbase中并没有单独的创一个索引表,在原表中为每条数据增加一个索引。
总结:
二级索引其实可以理解就是在原表的基础上,再建立一张索引表,索引包的rowkey=索引字段+原表rowkey。当查询的列值的时候,会先走索引表找到列值对应得原表中的rowkey,然后根据rowkey再去原表中查对应得数据。