前面几天元旦过high了,博客也停了一两天,哈哈,今天我们重新开始,今天我们介绍的是spark的原理
首先先说一个小贴士:
spark中,对于var count = 0,如果想使count自增,我们不能使用count++,而是我们要使用count = count + 1
接下来开始我们的正经事了,介绍spark的工作原理,先放上一张原理图
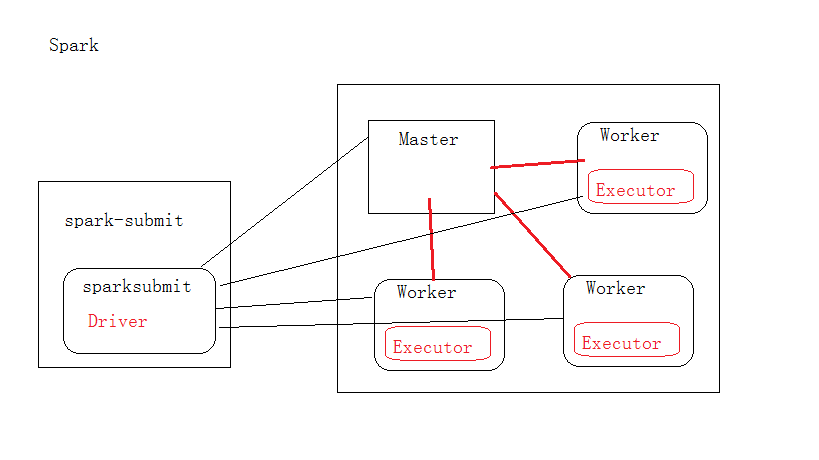
从这个图我们可以看出,当一个任务提交的时候,我们就可以调用调用Master,然后Master在找资源充沛的Worker,对于我们而言,如果我们写了一Spark的的程序,肯定里面有main方法,此时这个spark的程序就是一个spark-submit,而里面的main方法,我们就可以认为是一个SparkSubmit里面的Driver,一旦遇到Action,因为我们这里面分为Transformer以及Action,在前面的章节中已经介绍过这二者的区别了一旦遇到Action(此时我们可以简单的理解为这在执行collect),就把我们的任务提交到Master,然后Master申请资源,并决定在资源可用的机器上(Worker)启动一个Executor进程,则此后当Master接受到一个任务,并分配给资源可用的worker,其实是worker底下的Executor正在计算
在spark当中,一个任务叫做application,但是在hadoop中,一个任务叫做job
其中,我们可以这样理解,加入hdfs里面有200M缓存的规则,如果分为2个切片,则此时我们也是需要两个Excutor
来保存这两个block里面的内容,但是这个是不完整的,我们就会使用Driver会把这两个Excutor获取的数据进行汇总,
然后在经过Driver在对这个里面所有的Excutor进行广播,此时这个里面的Excutor的缓存了所有的数据
SPARK中的各个名词
spark程序:App
用于提交应用程序的:Driver
资源管理:Master
节点管理:Worker
执行真正的业务逻辑:spark-submit