爬取百度百科1000个页面的数据
1. 准备工作:
确定目标 => 分析目标(URL格式, 数据格式, 网页编码) => 编写代码 => 执行爬虫
1.1 链接分析:
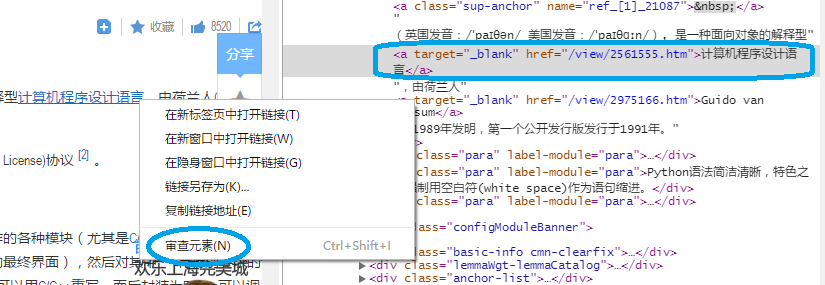
进入百度百科“Python”词条页面:http://baike.baidu.com/view/21087.htm => 在链接位置右键后,点击审查元素,
href="/view/2561555.htm" 是一个不完整的url, 在代码中需要拼接成完整的 baike.baidu.com/view/2561555.htm 才能进行后续的访问。
1.2 标题分析:
在标题位置右键后,点击审查元素。可看到标题内容在<dd class> 下的 <h1> 子标签中。

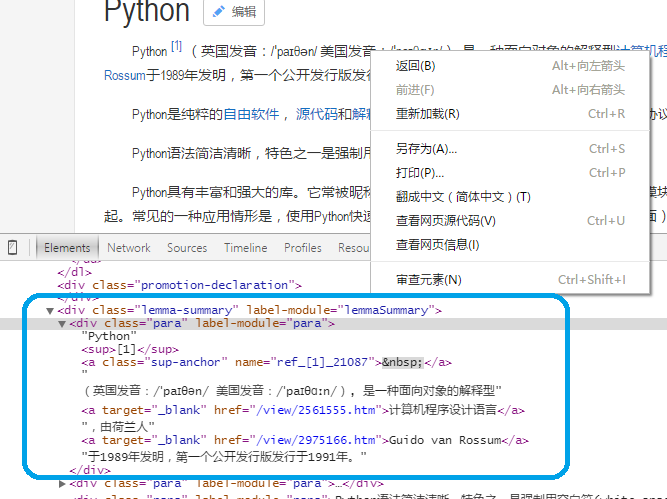
1.3 简介分析:
在简介位置右键后,点击审查元素。可看到简介内容在<class="lemma-summary"> 下。
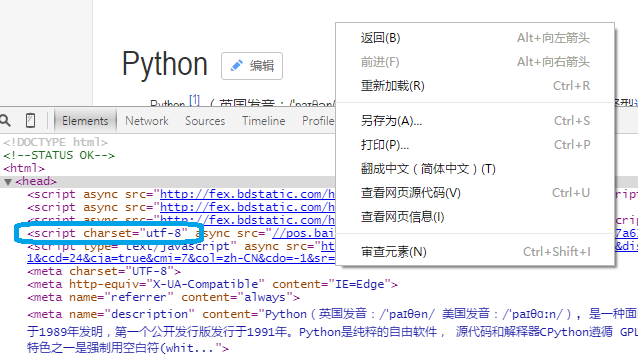
1.4 查看编码方式:
在空白位置右键后,点击审查元素。可看到编码方式在 script charset = “utf-8”
1.5 分析目标汇总:
a. 目标:百度百科Python词条相关词条网页 - 标题和简介
b. 入口页:http://baike.baidu.com/view/21087.htm
c. URL格式:词条页面URL:/view/125370.htm
d. 数据格式:
- 标题:<dd class="lemmaWgt-lemmaTitle-title"><h1>***</h1></dd>
- 简介:<div class= "lemma-summary">***<div>
e. 页面编码:UTF-8
2. 实例代码
2.1 调度程序:spyder_main.py


# -*- coding: utf-8 -*- """ Created on Tue Feb 14 13:34:27 2017 @author: Wayne """ from baike_spyder import url_manager,html_downloader,html_parser,html_outputer class SpyderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): count = 1 self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() #print "craw %d : %s" %(count, new_url) # wrong #print "craw %d : %s" %(count, new_url) # right print "craw %d : %s" %(count, new_url) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 1000: break count = count + 1 except Exception as e: print count print "craw failed" print e self.outputer.output_html() if __name__ == '__main__': root_url = "http://baike.baidu.com/view/286617.htm" obj_spyder = SpyderMain() obj_spyder.craw(root_url)
2.2 URL管理器:url_manager.py
# -*- coding: utf-8 -*- """ Created on Tue Feb 14 13:36:20 2017 @author: Wayne """ class UrlManager(object): def __init__(self): self.new_urls = set() # 创建一个待爬取的url集合 self.old_urls = set() # 创建一个已爬取的url集合 def add_new_url(self, url): # 向管理器中添加一个url if url is None: return if url not in self.new_urls and url not in self.old_urls: # 既不在待爬取的集合,也不在已爬取的集合 self.new_urls.add(url) # 用来待爬取 def add_new_urls(self, urls): # 向管理器中添加批量url if urls is None or len(urls)==0: return for url in urls: self.add_new_url(url) # 调用add_new_url方法进行单个的添加 def has_new_url(self): # 判断管理器中是否有新的待爬取url return len(self.new_urls)!=0 def get_new_url(self): # 从管理器中获取一个新的待爬取url new_url = self.new_urls.pop() # 从待爬取url集合中取一个url,并把这个url从集合中移除 self.old_urls.add(new_url) # 把这个url添加到已爬取的url集合中 return new_url
2.3 HTML下载器:html_downloader.py
# -*- coding: utf-8 -*- """ Created on Tue Feb 14 13:35:38 2017 @author: Wayne """ import urllib2 class HtmlDownloader(object): def download(self, url): if url is None: return None response = urllib2.urlopen(url) if response.getcode() != 200: return None return response.read()
2.4 HTML解析器:html_parser.py
# -*- coding: utf-8 -*- """ Created on Tue Feb 14 13:36:07 2017 @author: Wayne """ from bs4 import BeautifulSoup import re import urlparse class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() links = soup.find_all('a', href=re.compile(r"/view/d+.htm")) # 得到所有词条的url for link in links: new_url = link['href'] # 获取链接 new_full_url = urlparse.urljoin(page_url, new_url) # 把new_url按照和paga_url合并成一个完整的url new_urls.add(new_full_url) return new_urls def _get_new_data(self, page_url, soup): res_data = {} res_data['url'] = page_url title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1") res_data['title'] = title_node.get_text() summary_node = soup.find('div', class_="lemma-summary") res_data['summary'] = summary_node.get_text() return res_data def parse(self, page_url, html_cont): if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8') new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls, new_data
2.5 HTML输出器:html_outputer.py
# -*- coding: utf-8 -*- """ Created on Tue Feb 14 13:35:56 2017 @author: Wayne """ class HtmlOutputer(object): def __init__(self): # 建立列表存放数据 self.datas = [] def collect_data(self, data): # 收集数据 if data is None: return self.datas.append(data) def output_html(self): fout = open('output.html', 'w') fout.write("<html>") fout.write("<head><meta http-equiv="content-type" content="text/html;charset=utf-8"></head>") fout.write("<body>") fout.write("<table>") for data in self.datas: fout.write("<tr>") fout.write("<td>%s</td>" % data['url']) fout.write("<td>%s</td>" % data['title'].encode('UTF-8')) fout.write("<td>%s</td>" % data['summary'].encode('UTF-8')) fout.write("</tr>") fout.write("</table>") fout.write("</body>") fout.write("</html>") fout.close()
3. 课程总结
