微服务的架构问题
服务之间互相依赖,可能会由于系统负载过高,突发流量或者网络等各种异常情况 导致服务不可用。
主要解决思想是面向失败编程,简而言之就是方案1的时候因为有些服务出错了。这时候可以有方案2
提高微服务的容错方案
- 限流
不管流量有多大,通过的话都只能通过一个“漏斗”,从而实现限流,常见的算法有令牌桶算法,漏桶算法 - 熔断
相当于一个保险丝,防止整个系统遭到破坏
比如说,订单服务要调用风控服务来看看这个人是不是在薅羊毛,但是风控服务卡死了,这个时候订单服务也要被拖垮了,就会有熔断,来不去访问风控服务了,有可能会隔一段时间再去访问来防止订单服务被拖垮 - 降级
比如订单服务和风控服务,风控服务是不太必要的,就是把那些不太重要的服务在系统压力很大的时候先去掉 - 隔离
服务和资源隔离开,比如风控服务当很卡的时候,也不会占用计算机的内存(还有其他资源),会留一部分给订单服务
容错的话在主要是用Sentiel
Sentiel
分布式系统的流量卫兵,下面是他的一些概念
- 资源:是 Sentinel 中的核心概念之一,可以是java程序中任何内容,可以是服务或者方法甚至代码,总结起来就是我们要保护的东西
- 规则:定义怎样的方式保护资源,主要包括流控规则、熔断降级规则等
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo、Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
- 引入依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- 下载Sentinel jar包,这里我们是要启动控制台(默认的只能单机部署)
- 启动这个jar包
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.0.jar
可以自己更改端口 - 然后访问
http://localhost:8080/#/login
默认账号密码都是sentinel
- 然后在服务模块的application.yml配置
spring:
sentinel:
transport:
dashboard: 127.0.0.1:8080
port: 9999
port是通信端口,不同服务不能一样,然后启动服务
6. 然后设置流量控制进行测试
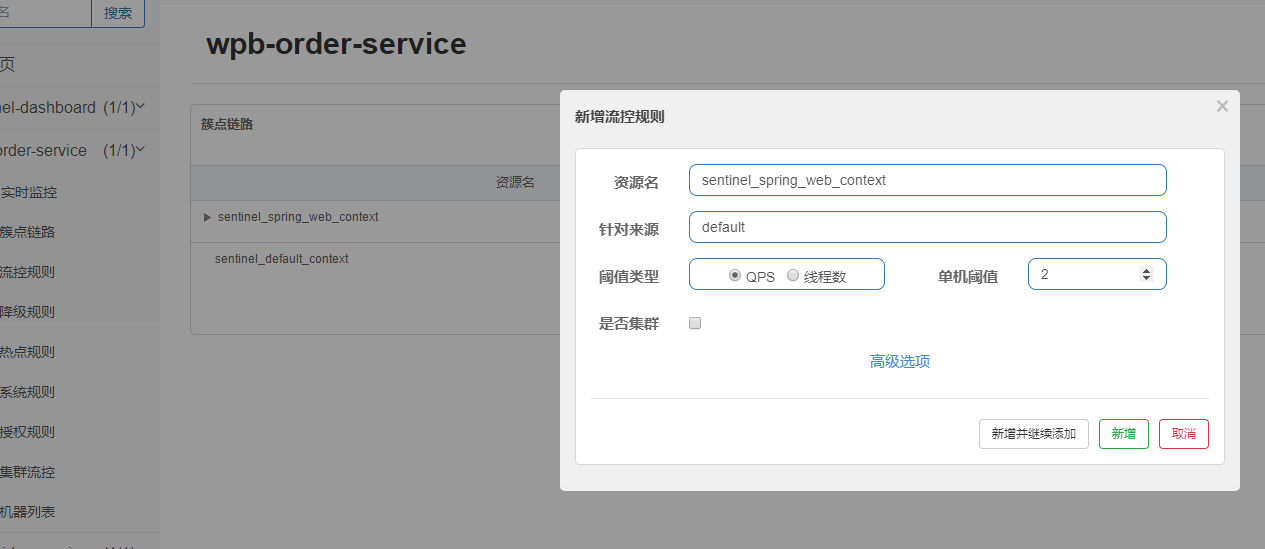
在浏览器进行访问尝试,刷新点的太快就
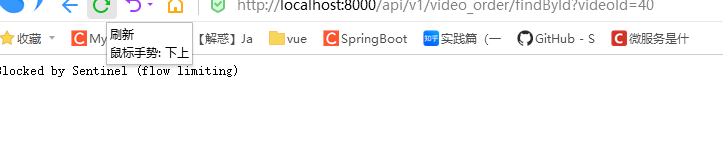
流控规则默认是基于内存的,重启的话就没有了
自己想测试的话,可以TimeUnit.SECONDS.sleep(3);来模拟线程睡眠
流量控制的效果
- 直接拒绝:默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝
- Warm Up:冷启动/预热,如果系统在此之前长期处于空闲的状态,我们希望处理请求的数量是缓步的增多,经过预期的时间以后,到达系统处理请求个数的最大值.刚开始的时候,很多配置还没有被加载进来,一开始的QPS饱和值比较小
- 匀速排队:严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法,主要用于处理间隔性突发的流量,如消息队列,想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求,匀速排队等待策略是 Leaky Bucket 算法结合虚拟队列等待机制实现的。匀速排队模式暂时不支持 QPS > 1000 的场景
熔断和降级
基本思想就是对于调用的链路中不稳定的服务进行熔断降级,暂时切断该服务,避免整体系统的崩溃
熔断降级的策略
慢调用比例(响应时间): 选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用
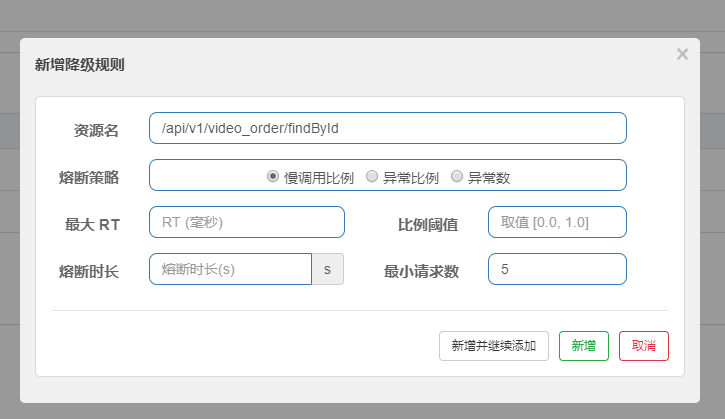
- 比例阈值:修改后不生效-目前已经反馈给官方那边的bug,就是超过最大RT的请求数目的比例
- 熔断时长:超过时间后会尝试恢复
- 最小请求数:熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断
- 最大RT: 即超过多长时间会算是一个坏请求
异常比例:当单位统计时长内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断
- 比例阈值
- 熔断时长:超过时间后会尝试恢复
- 最小请求数:熔断触发的最小请求数,请求数小于该值时,即使异常比率超出阈值也不会熔断
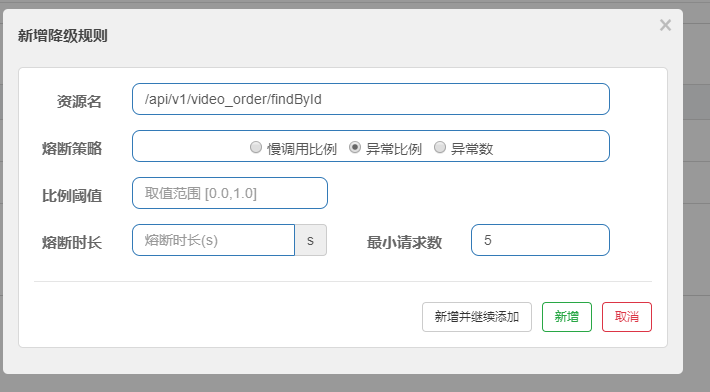
异常数:当单位统计时长内的异常数目超过阈值之后会自动进行熔断
异常数:
- 熔断时长:超过时间后会尝试恢复
- 最小请求数:熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断

熔断的状态
- 熔断关闭(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
- 熔断开启(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法
- 半熔断(Half-Open)
所谓半熔断就是尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率
- 熔断恢复:
经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态)尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。
如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断状态

异常处理

这样处理不太友好,需要自己定义异常处理,也是熔断时候的降级处理