1.一维数组中寻找与某个数最近的数
# 一维数组中寻找与某个数最近的数 Z=np.random.uniform(0,1,20) print("随机数组: ",Z) z=0.5 m=Z.flat[np.abs(Z-z).argmin()] m
Out[35]:
0.5166891167930422
2. 找出给定一维数组中非 0 元素的位置索引
Z = np.nonzero([1,0,2,0,1,0,4,0])
Z
(array([0, 2, 4, 6]),)
3.对于给定的 5x5 二维数组,在其内部随机放置 p 个值为 1 的数
p=3 Z=np.zeros((5,5)) z=np.copy(Z) choice=np.random.choice(range(5*5), p, replace=False) print(choice) np.put(Z,choice,1) print(Z) np.put(z,np.random.choice(range(3*3),p,replace=False),1) Z
Out[103]:
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1.]])
4.对于随机的 3x3 二维数组,减去数组每一行的平均值
X=np.random.rand(3,3) print(X) print(X.mean(axis=1,keepdims=True)) print(X.mean(axis=1,keepdims=False)) Y=X-X.mean(axis=1,keepdims=True) Y
Out[106]:
5 获得二维数组点积结果的对角线数组
A=np.random.uniform(0,1,(3,3)) B=np.random.uniform(0,1,(3,3)) print(np.dot(A,B))
[[0.69147934 0.2526067 0.54456377] [1.88744045 1.39425446 1.01802782] [0.80716853 0.21709932 0.68321853]]
/慢方法
np.diag(np.dot(A,B))
[0.69147934 1.39425446 0.68321853]
/快方法
np.sum(A*B.T,axis=1)
[0.69147934 1.39425446 0.68321853]
# 更快的方法
np.einsum("ij, ji->i", A, B)
6.找到随机一维数组中前 p 个最大值
Z=np.random.randint(1,100,100) print(Z) p=5 # 法一 print(np.argsort(Z)) print(np.argsort(Z)[-p:]) z1=Z[np.argsort(Z)[-p:]] print(z1) # 法二 print(np.argsort(Z)) z2=Z[np.argsort(Z)] print(z2) print(z2[-p:])
[34 92 73 81 72 69 84 67 84 54 42 55 67 42 26 59 48 41 42 15 15 75 34 65 56 4 82 85 33 10 51 69 32 59 51 76 13 2 48 55 22 25 44 11 28 62 8 31 47 75 24 91 61 13 52 24 51 96 77 35 20 98 17 33 24 21 64 23 87 70 59 77 46 37 90 67 46 24 81 59 29 31 74 67 68 23 43 12 21 37 94 24 69 32 89 20 76 95 31 66] [37 25 46 29 43 87 36 53 20 19 62 95 60 65 88 40 85 67 64 50 55 91 77 41 14 44 80 47 81 98 32 93 28 63 0 22 59 73 89 17 10 18 13 86 42 72 76 48 38 16 34 56 30 54 9 39 11 24 70 79 33 15 52 45 66 23 99 83 7 75 12 84 92 5 31 69 4 2 82 21 49 96 35 58 71 3 78 26 6 8 27 68 94 74 51 1 90 97 57 61] [ 1 90 97 57 61] [92 94 95 96 98]
--------------------------------------------------------------------------- [37 25 46 29 43 87 36 53 20 19 62 95 60 65 88 40 85 67 64 50 55 91 77 41 14 44 80 47 81 98 32 93 28 63 0 22 59 73 89 17 10 18 13 86 42 72 76 48 38 16 34 56 30 54 9 39 11 24 70 79 33 15 52 45 66 23 99 83 7 75 12 84 92 5 31 69 4 2 82 21 49 96 35 58 71 3 78 26 6 8 27 68 94 74 51 1 90 97 57 61] [ 2 4 8 10 11 12 13 13 15 15 17 20 20 21 21 22 23 23 24 24 24 24 24 25 26 28 29 31 31 31 32 32 33 33 34 34 35 37 37 41 42 42 42 43 44 46 46 47 48 48 51 51 51 52 54 55 55 56 59 59 59 59 61 62 64 65 66 67 67 67 67 68 69 69 69 70 72 73 74 75 75 76 76 77 77 81 81 82 84 84 85 87 89 90 91 92 94 95 96 98] [92 94 95 96 98]
7.对于二维随机数组中各元素,保留其 2 位小数
Z=np.random.random((5,5)) print(Z) np.set_printoptions(precision=2) Z
Out[161]:
array([[0.45, 0. , 0.43, 0.88, 0.67],
[0.8 , 0.54, 0.68, 0.32, 0.22],
[0.58, 0.6 , 0.26, 0.94, 0.99],
[0.12, 0.46, 0.22, 0.64, 0.85],
[0.6 , 0.34, 0.37, 0.44, 0.78]])
4使用科学记数法输出 NumPy 数组
Z = np.random.random([5,5]) print(Z) Z/1e3
Out[88]:
array([[6.47e-06, 9.04e-04, 6.37e-04, 6.83e-04, 4.62e-04],
[6.13e-04, 1.82e-06, 4.02e-04, 8.70e-05, 2.10e-05],
[8.34e-04, 9.52e-05, 7.16e-04, 8.68e-04, 9.34e-05],
[4.93e-04, 1.49e-04, 3.73e-04, 4.32e-04, 2.73e-04],
[4.85e-04, 8.66e-04, 4.04e-04, 3.83e-04, 5.70e-04]])
5.使用 NumPy 找出百分位点(25%,50%,75%)
a=np.arange(15) print(a) np.percentile(a,q=[25,50,75])
Out[165]:
array([ 3.5, 7. , 10.5])
6.找出数组中缺失值的总数及所在位置
# 生成含缺失值的 2 维数组 Z = np.random.rand(10,10) Z[np.random.randint(10, size=5), np.random.randint(10, size=5)] = np.nan Z
array([[0.8 , 0.25, 0.74, 0.05, 0.24, 0.16, 0.63, 0.62, 0.89, 0.85],
[0.61, 0.76, 0.26, 0.3 , 0.82, 0.74, 0.96, 0.64, 0.58, 0.06],
[0.78, 0.38, 0.19, 0.68, 0.75, 0.91, 0.13, 0.24, 0.98, 0.21],
[0.47, 0.12, 0.34, 0.06, 0.46, 0.69, 0.1 , nan, 0.27, 0.92],
[0.83, 0.01, 0.63, 0.15, 0.52, 0.52, 0.02, 0. , 0.74, 0.59],
[0.56, 0.66, 0.15, nan, 0.26, 0.88, 0.15, 0.57, 0.61, 0.35],
[0.33, 0.58, 0.06, 0.94, 0.58, 0.53, 0.97, 0.02, 0.32, nan],
[0.84, 0.71, 0.65, 0.42, 0.44, 0.96, 0.37, 0.65, 0.6 , 0.17],
[0.04, 0.94, 0.92, nan, 0.7 , 0.38, 0.28, 0.45, 0.35, 0.93],
[0.38, 0.69, 0.43, 0.01, 0.67, 0.46, 0.73, 0.99, 0.94, 0.45]]
print("缺失值总数: ", np.isnan(Z).sum()) print("缺失值索引: ", np.where(np.isnan(Z)))
缺失值总数: 4 缺失值索引: (array([3, 5, 6, 8]), array([7, 3, 9, 3]))
=>(3,7)(5,3)(6,9)(8,3)
#从随机数组中删除包含缺失值的行 Z[np.sum(np.isnan(Z),axis=1)==0]
6.统计随机数组中的各元素的数量
Z=np.random.randint(0,10,100).reshape(10,10) print(Z) np.unique(Z,return_counts=True)
Out[22]:
Out[97]:
8.48528137423857
9.求解给出矩阵的逆矩阵并验证
matrix = np.array([[1., 2.], [3., 4.]]) inverse_matrix = np.linalg.inv(matrix) # 验证原矩阵和逆矩阵的点积是否为单位矩阵 assert np.allclose(np.dot(matrix, inverse_matrix), np.eye(2)) inverse_matrix
array([[-2. , 1. ],
[ 1.5, -0.5]])
10-12都是数据标准化处理
10.使用 Z-Score 标准化算法对数据进行标准化处理
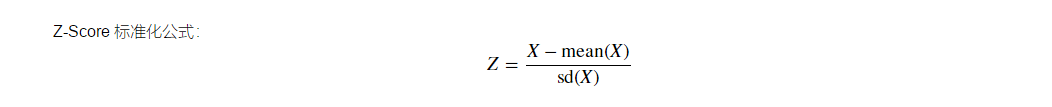
#根据Z-Scor公式定义函数 def zscore(x,axis=None): xmean=x.mean(axis=axis,keepdims=True) xstd=np.std(x,axis=axis,keepdims=True) zscore=(x-xmean)/xstd return zscore #生成随机矩阵 Z=np.random.randint(10,size=(5,5)) print(Z) zscore(Z)
Out[28]:
array([[ 1.35690061, 0.58593435, -1.72696441, 1.35690061, 0.20045123],
[ 0.97141748, -1.34148129, 0.97141748, -0.57051503, 0.58593435],
[-1.34148129, 0.20045123, 0.58593435, -1.72696441, -0.1850319 ],
[ 0.58593435, 0.20045123, 0.20045123, 0.58593435, -2.11244754],
[ 0.58593435, 1.35690061, -0.1850319 , -0.1850319 , -0.95599816]])
11.使用 Min-Max 标准化算法对数据进行标准化处理
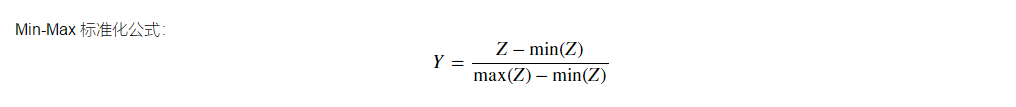
#数据公式熟悉 x=np.array([[1,2],[3,4]]) min=x.min(axis=None,keepdims=True) mean=x.mean(axis=None,keepdims=True) print(min) print(mean) print(x-min)
[[1]]
[[2.5]]
[[0 1] [2 3]]
#定义Min-Max 标准化公式
def min_max(x,axis=None): min=x.min(axis=axis,keepdims=True) max=x.max(axis=axis,keepdims=True) result=(x-min)/(max-min) return result #生成随机数据 Z=np.random.randint(10,size=(5,5)) print(Z) print(Z.min()) #0 print(Z.max()) #9
min_max(Z)
Out[37]:
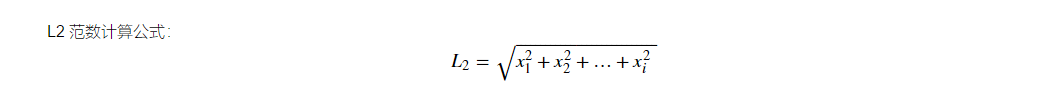
x=np.array([[1,1],
[2,2]])
#axis=1 按列 算行
l2 = np.linalg.norm(x, ord = 2, axis=1, keepdims=True)
print(l2)
#非零处理
l2[l2==0]=1
print(l2)
array([[1.41421356],
[2.82842712]])
array([[1.41421356],
[2.82842712]])
# 根据l2公式定义函数 def l2_normalize(v, axis=-1, order=2): l2 = np.linalg.norm(v, ord = order, axis=axis, keepdims=True) l2[l2==0] = 1 return v/l2 # 生成随机数据 Z = np.random.randint(10, size=(5,5)) print(Z) l2_normalize(Z)
Out[104]: