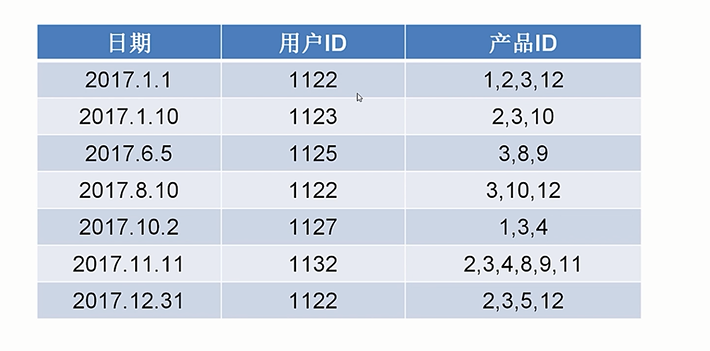
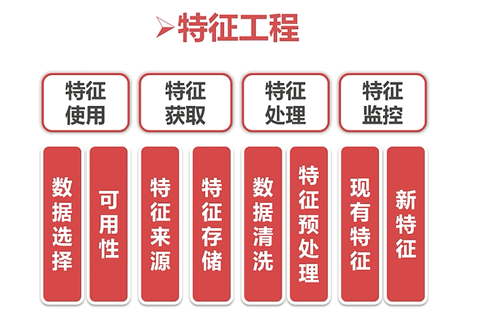
特征工程
 ,
, 
 ,
, 
异常值(空值)处理
空值、重复值、四分位数上下1.5倍到3倍边界范围以外、业务实际情况下不允许出现的值
集中值:均值,中位数,众数等
 ,
,  ,
,

 ,
, 
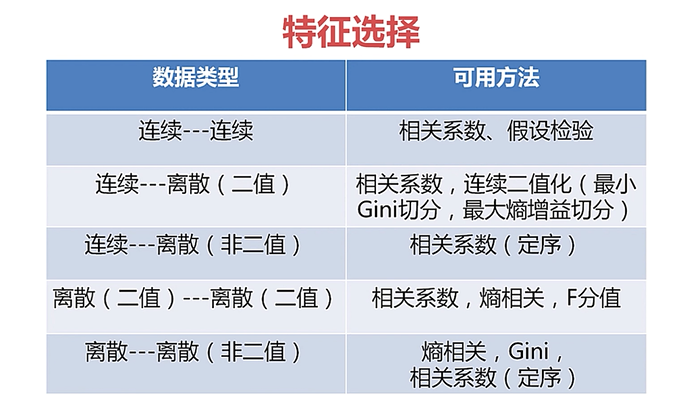
特征选择:
 ,
, 
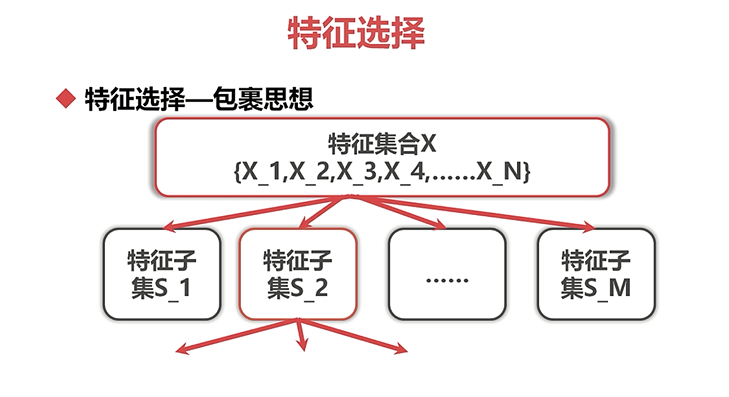 ,
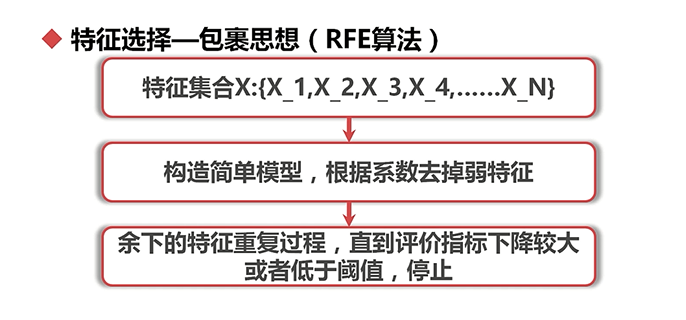
, 
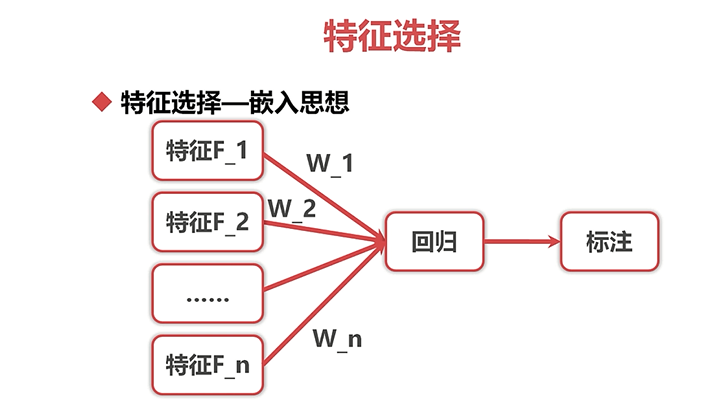
特征变换:

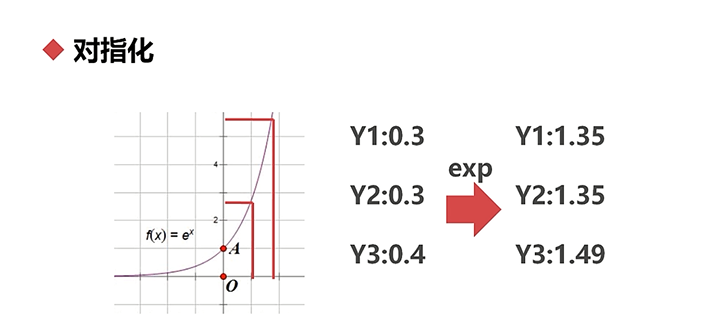
对指化:将数据进行对数化和指数化的过程
指数化:将一个数进行指数变换的过程,指数的底数一般取自然底数e
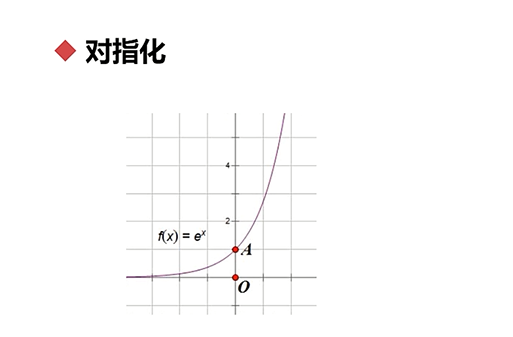 ,
, 
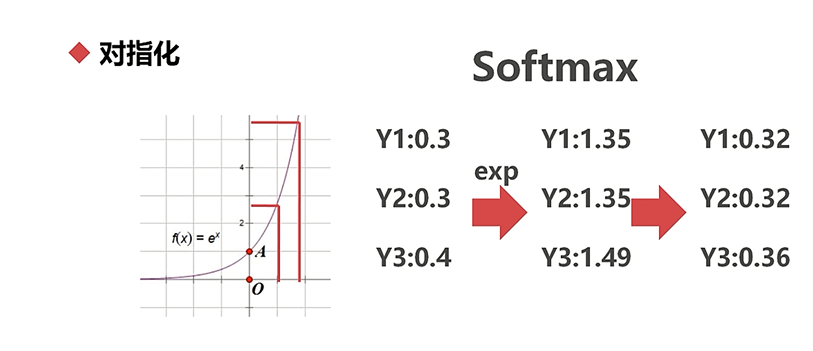
对数化:取自然底数e
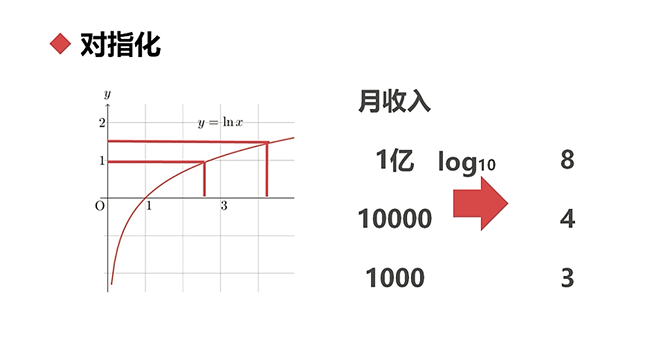 ,
, 
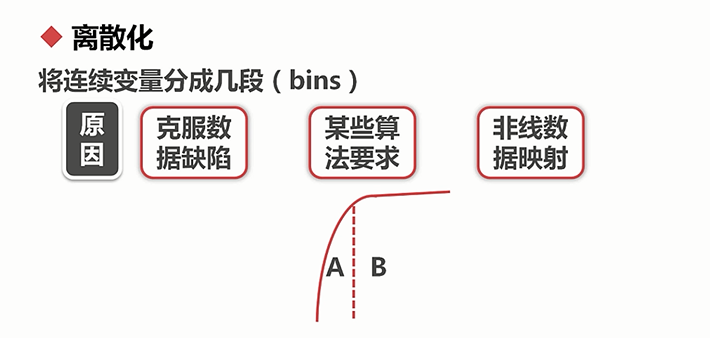
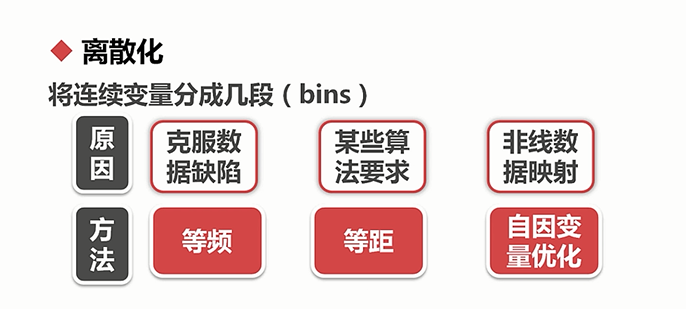
离散化:
将连续变量分成几段(bins)
原因:
1.客服数据缺陷:连续数据有很多信息,但其中也可能存在一些意想不到的噪声
2.某些算法要求:朴素贝叶斯需要属性是离散的数据
3.非线性数据映射:比如某些数据的分布可能会有明显的拐点,连续数值在不同的区间内可能代表着不同的含义,因此在不同区间可能比连续数值本身更能代表数据的特性
 ,
,
数据分箱计数:(在进行分箱前一定要进行排序)
方法一:等频分箱计数(等深分箱)

方法二:等距分箱计数(等宽分箱)

自因变量优化方法:根据自变量,因变量的有序分布,找到拐点等特殊变化点进行离散化
归一化:一种数据变换方法,即最小化,最大化的一种特殊形式,将数据的范围缩放到指定的范围内
所谓的归一化,就是将数据转换至0到1 的范围(最小值是0,最大值是1)

优点:一方面可以观察单个数据相对于整体数据的比列,另一方面,如果遇到数据不同量纲的特征,可以方便的建立起这些数据特征之间进行合适的距离度量方法
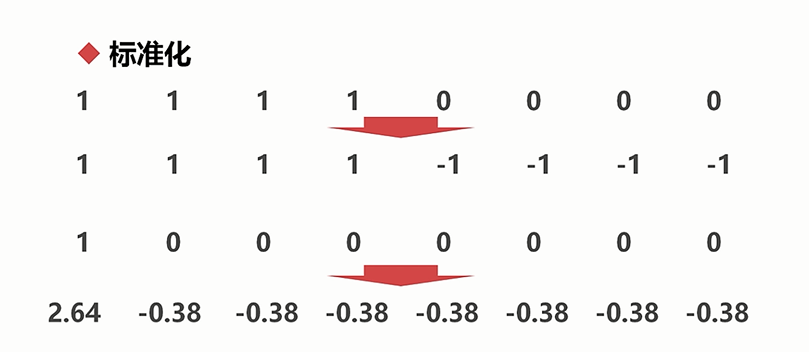
标准化:将数据缩放到均值为0,标准差为1的尺度上

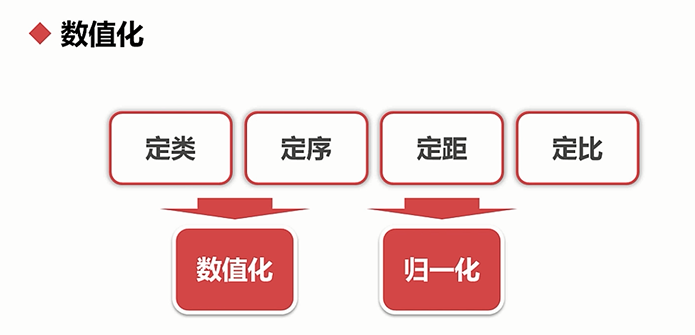
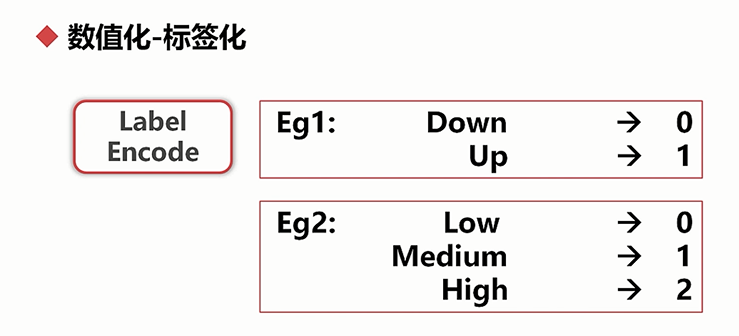
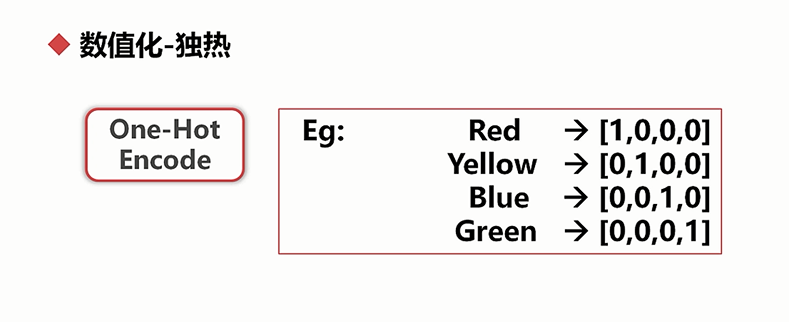
数值化:把非数值数据转换成数值数据的过程
 ,
, 
正规化(规范化):将个一向量的长度正规到单位一
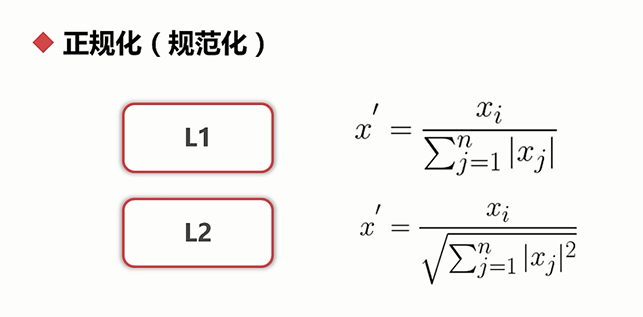
L2距离:欧氏距离


 ,
,
注:不管是一般的线性PCA变换,或奇异值分解等,都没有考虑到标注,而是让特征与特征之间的相关性强弱来决定降维后的分布形态,是一种无监督的降维方法,而LDA是使用到标注的降维方法。

注:不要理解成了 这个隐含狄利克雷分布!!!在文本分析领域,这个分布主要是应用在自然语言处理中主题模型的建立。
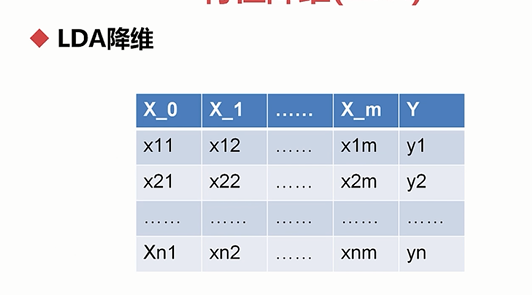
说明:m个特征,Y是其标注,以二分类为例的话,这里的Y就取0或者1,同时,这个特征矩阵有n行,对应于n个对象,

然后根据行进行切分,可以分成两个子矩阵,一个子矩阵的标注都是0,而另外一个子矩阵的标注都是1 。

然后根据这两个子矩阵进行线性变换,所谓的线性变换,就是在这个子矩阵前乘以一个参数矩阵w,注意:标注Y并不参与到计算中
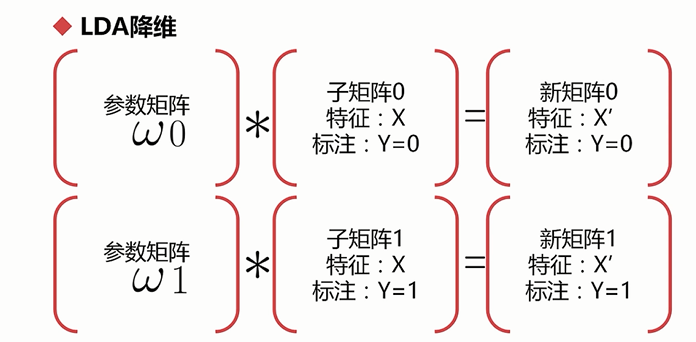
先衡量不同标注间的距离,直观意义上就是将两个矩阵进行直接相减。希望它们之间的距离尽可能大
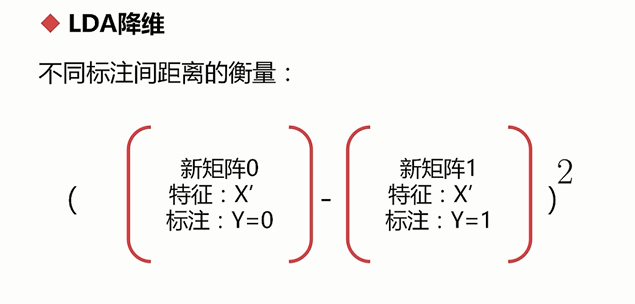
再衡量同一个标注之间距离的大小,希望它们尽可能小
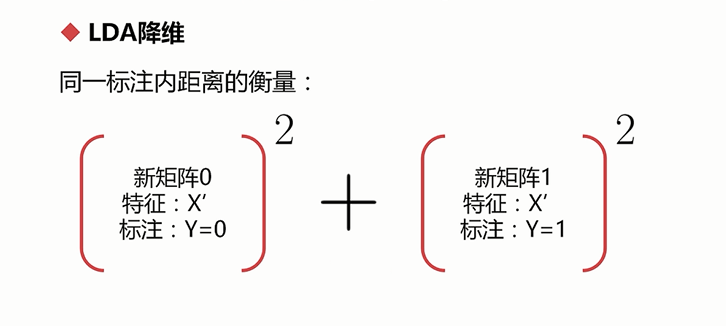
最大化一个函数:
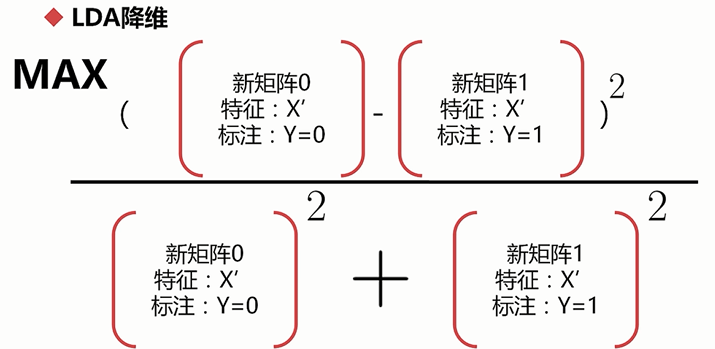

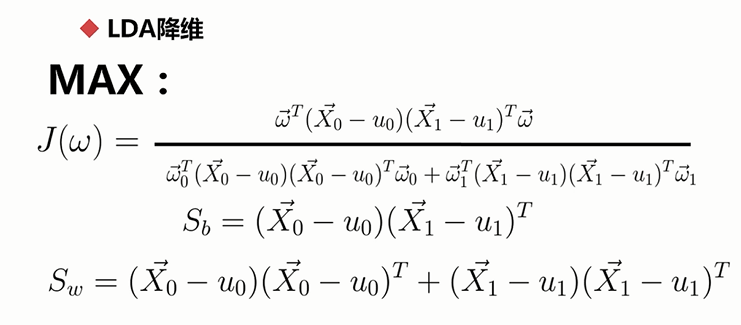


特征衍生:对现有的特征进行某些组合生成新的具有含义的特征。