1.安装open-vm-tools
sudo apt-get install open-vm-tools


2.安装openjdk
sudo apt-get install openjdk-8-jdk

3.安装配置ssh
apt-get install openssh-server
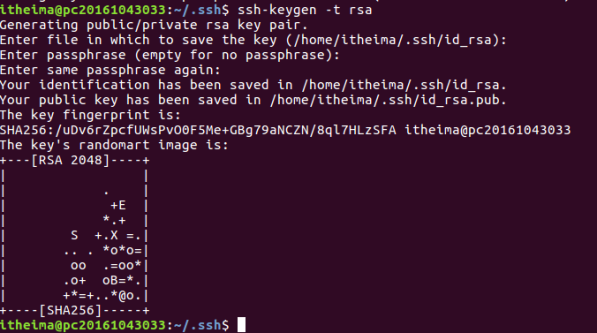
4.在进行了初次登陆后,会在当前家目录用户下有一个.ssh文件夹,进入该文件夹下:cd .ssh
ssh-keygen -t rsa
一路回车c

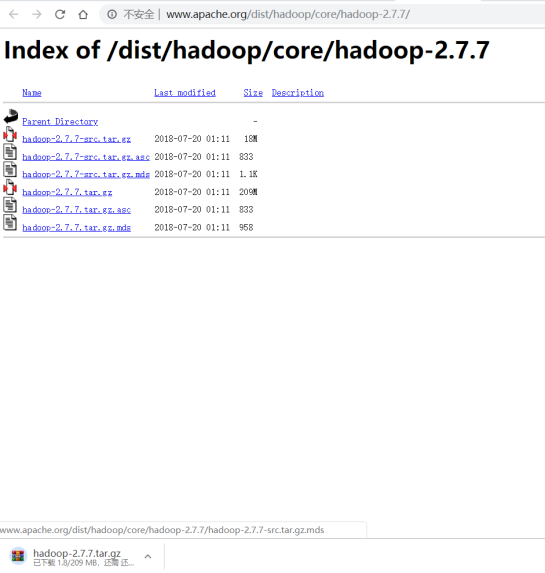
5.下载hadoop2.7.7 解压缩并改名为hadoop目录,放到/usr/local下(注意权限)
sudo mv ~/hadoop-2.7.7 /usr/local/hadoop


![]()
6.修改目录所有者 /usr/local/下的hadoop文件夹
sudo chown -R 当前用户名 /usr/local/hadoop
![]()
7.设置环境变量
(1)进入 sudo gedit ~/.bashrc
#~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
#打包hadoop程序需要的环境变量
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
#让环境变量生效
source ~/.bashrc
(2) 进入 /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
(3) 进入 /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(4) 进入 /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
(5) 进入 /usr/local/hadoop/etc/hadoop/mapred-site.xml(mapred-site.xml.template重命名)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6) 进入 /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

8.格式化hdfs文件系统
hdfs namenode -format

9.启动hadoop
start-all.sh 或start-dfs.sh start-yarn.sh

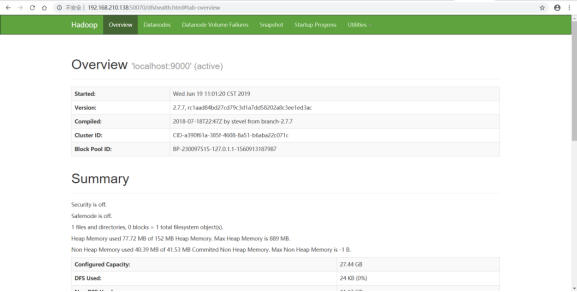
10.浏览器搜索