一、定义
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
二、原理
爬虫是 模拟用户在浏览器或者App应用上的操作,把操作的过程、实现自动化的程序
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入https://www.baidu.com
简单来说这段过程发生了以下四个步骤:
查找域名对应的IP地址。
浏览器首先访问的是DNS(Domain Name System,域名系统),dns的主要工作就是把域名转换成相应的IP地址
向IP对应的服务器发送请求。
服务器响应请求,发回网页内容。
浏览器显示网页内容。
浏览器工作原理网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
三、使用模块
1.Requests库基础知识
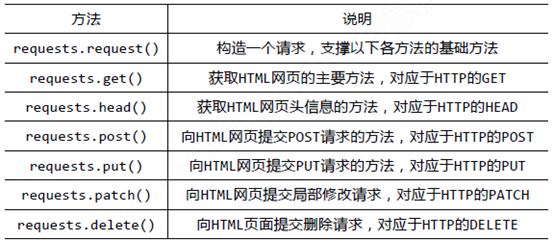
Requests库的get()方法


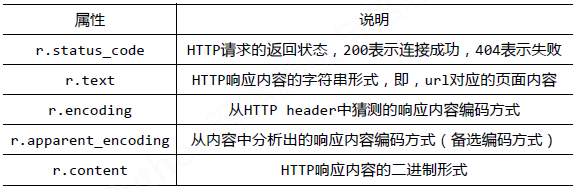
Requests库的Response对象:
Response对象包含服务器返回的所有信息,也包含请求的Request信息。
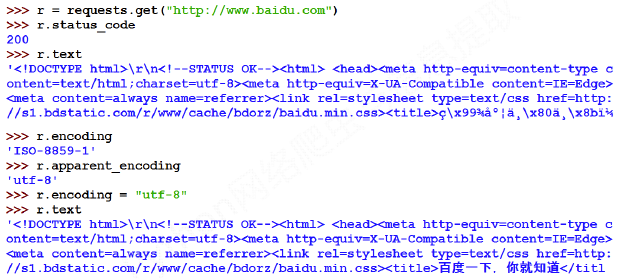
运行截图如下所示:
2、Requests库实例
(1)京东商品的爬取--普通爬取框架
import requests url = "https://item.jd.com/2967929.html" try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000]) except: print("爬取失败!")
(2)亚马逊商品的爬取--通过修改headers字段,模拟浏览器向网站发起请求
import requests url="https://www.amazon.cn/gp/product/B01M8L5Z3Y" try: kv = {'user-agent':'Mozilla/5.0'} r=requests.get(url,headers=kv) r.raise_for_status() r.encoding=r.apparent_encoding print(r.status_code) print(r.text[:1000]) except: print("爬取失败")
(3)百度/360搜索关键词提交--修改params参数提交关键词
百度的关键词接口:http://www.baidu.com/s?wd=keyword
360的关键词接口:http://www.so.com/s?q=keyword
import requests url="http://www.baidu.com/s" try: kv={'wd':'Python'} r=requests.get(url,params=kv) print(r.request.url) r.raise_for_status() print(len(r.text)) print(r.text[500:5000]) except: print("爬取失败")
(4)网络图片的爬取和存储--结合os库和文件操作的使用
import requests import os url="http://tc.sinaimg.cn/maxwidth.800/tc.service.weibo.com/p3_pstatp_com/6da229b421faf86ca9ba406190b6f06e.jpg" root="D://pics//" path=root + url.split('/')[-1] try: if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r = requests.get(url) with open(path, 'wb') as f: f.write(r.content) f.close() print("文件保存成功") else: print("文件已存在") except: print("爬取失败")