在上一篇文章中说明了kafka-python的API使用的理论概念,这篇文章来说明API的实际使用。
在官方文档详细列出了kafka-python的API接口https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html
对于生成者我们着重于介绍一个send方法,其余的方法提到的时候会说明,在官方文档中有许多可配置参数可以查看,也可以查看上一篇博文中的参数。
#send方法的详细说明,send用于向主题发送信息
send(topic, value=None, key=None, headers=None, partition=None, timestamp_ms=None)
topic (str) – topic where the message will be published,指定向哪个主题发送消息。
value (optional) – message value. Must be type bytes, or be serializable to bytes via configured value_serializer. If value is None, key is required and message acts as a ‘delete’.
#value为要发送的消息值,必须为bytes类型,如果这个值为空,则必须有对应的key值,并且空值被标记为删除。可以通过配置value_serializer参数序列化为字节类型。
key (optional) – a key to associate with the message. Can be used to determine which partition to send the message to. If partition is None (and producer’s partitioner config is left as default),
then messages with the same key will be delivered to the same partition (but if key is None, partition is chosen randomly). Must be
type bytes, or be serializable to bytes via configured key_serializer.
#key与value对应的键值,必须为bytes类型。kafka根据key值确定消息发往哪个分区(如果分区被指定则发往指定的分区),具有相同key的消息被发往同一个分区,如果key
#为NONE则随机选择分区,可以使用key_serializer参数序列化为字节类型。
headers (optional) – a list of header key value pairs. List items are tuples of str key and bytes value.
#键值对的列表头部,列表项是str(key)和bytes(value)。
timestamp_ms (int, optional) – epoch milliseconds (from Jan 1 1970 UTC) to use as the message timestamp. Defaults to current time.
#时间戳
消息发送成功,返回的是RecordMetadata的对象;否则的话引发KafkaTimeoutError异常
在进行实际测试前,先创建一个topics,这里我们利用控制台创建:
[root@test3 bin]# ./kafka-topics.sh --zookeeper=10.0.102.204:2181,10.0.102.214:2181 --create --topic kafkatest --replication-factor 3 --partitions 3 Created topic "kafkatest". [root@test3 bin]# ./kafka-topics.sh --zookeeper=10.0.102.204:2181,10.0.102.214:2181 --list --topic kafkatest kafkatest [root@test3 bin]# ./kafka-topics.sh --zookeeper=10.0.102.204:2181,10.0.102.214:2181 --describe --topic kafkatest Topic:kafkatest PartitionCount:3 ReplicationFactor:3 Configs: Topic: kafkatest Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Topic: kafkatest Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 Topic: kafkatest Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3 [root@test3 bin]#
#主题有3个分区,3个复制系数,主题名为kafkatest.
一个简易的生产者demo如下:(摘自:https://blog.csdn.net/luanpeng825485697/article/details/81036028)
from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers=["10.0.102.214:9092"]) i = 20 while True: i += 1 msg = "producer1+%d" % i print(msg) producer.send('kafkatest', key=bytes(str(i), value=msg.encode('utf-8')) time.sleep(1) producer.close()
#就是一个简易的while循环,不停的向kafka发送消息,一定要注意send发送的key和value的值均为bytes类型。
一个消费者的demo接收上面生产者发送的数据。
from kafka import KafkaConsumer consumer = KafkaConsumer("kafkatest", bootstrap_servers=["10.0.102.204:9092"], auto_offset_reset='latest') for msg in consumer: key = msg.key.decode(encoding="utf-8") #因为接收到的数据时bytes类型,因此需要解码 value = msg.value.decode(encoding="utf-8") print("%s-%d-%d key=%s value=%s" % (msg.topic, msg.partition, msg.offset, key, value))
#这是一个阻塞的过程,当生产者有消息传来的时候,就会读取消息,若是没有消息就会阻塞等待
#auto_offset_reset参数表示重置偏移量,有两个取值,latest表示读取消息队列中最新的消息,另一个取值earliest表示读取最早的消息。
执行上面的两个demo,得到的结果如下:
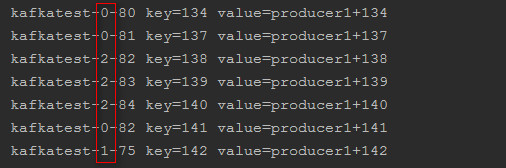
消费者群组
在上一篇博文中,说明了消费者群组与消费者的概念,这里我们来定义一个消费者群组。
一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息。每个消费者接收主题一部分分区的消息
创建一个消费者群组如下:
from kafka import KafkaConsumer import time
#消费者群组中有一个group_id参数, consumer = KafkaConsumer("kafkatest", group_id="test1", bootstrap_servers=["10.0.102.204:9092"], auto_offset_reset='latest') for msg in consumer: key = msg.key.decode(encoding="utf-8") value = msg.value.decode(encoding="utf-8") print("%s-%d-%d key=%s value=%s" % (msg.topic, msg.partition, msg.offset, key, value))
消费者群组中的消费者总是消费订阅主题的部分数据。
在pycharm中把上面的代码复制一份,这样在一个test1群组中就有了两个消费者,同时执行。
分析: kafkatest主题有3个分区,3个分区会被分配给test1群组中的两个消费者,在上面一篇博文中提到,默认的分配策略时range。也就是说一个消费者可能由2个分区,另一个消费者只有一个分区;执行结果如下:
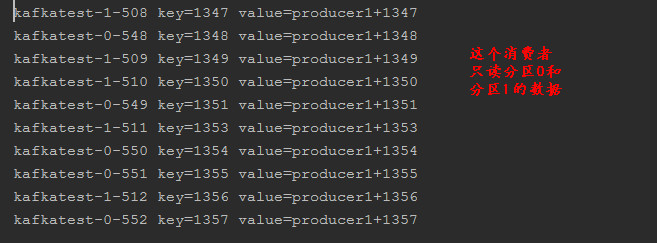
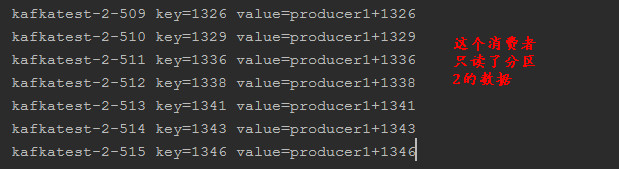
下面会通过实例来说明几个消费者的方法的使用
kafka-python的API官方文档介绍的很清楚,可以查看:https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html
>>> from kafka import KafkaConsumer >>> consumer = KafkaConsumer("kafkatest", group_id="test1", bootstrap_servers=["10.0.102.204:9092"])
>>> consumer.topics() #获取主主题列表,返回的是一个set集合 {'kafkatest', 'lianxi', 'science'} >>> consumer.partitions_for_topic("kafkatest") #获取主题的分区信息 {0, 1, 2} >>> consumer.subscription() #获取当前消费者订阅的主题 {'kafkatest'}
>>> consumer.position((0,)) #得到下一个记录的偏移量
TypeError: partition must be a TopicPartition namedtuple
#需要注意的是position方法需要传入的是一个kafka-python自带的一种数据结构TopicPartition,这种数据结构的定义如下,在使用的时候需要导入
TopicPartition = namedtuple("TopicPartition", ["topic", "partition"])
>>> consumer.position(TopicPartition(topic='kafkatest', partition=1))
17580
下面说明poll()方法的用法:
poll(timeout_ms=0, max_records=None)方法: 从指定的主题/分区中获取数据 Records are fetched and returned in batches by topic-partition. On each poll, consumer will try to use the last consumed offset as the starting offset and fetch sequentially. The last consumed offset can be manually set through seek() or automatically set as the last committed offset for the subscribed list of partitions. #通过主题-分区分批获取和返回记录,在每一个轮询中,消费者将会使用最后消费的偏移量作为开始然后顺序fetch数据。最后消费的偏移量可以使用seek()手动设置,或者自动设置为订阅
#的分区列表的最后提交的偏移量。 Incompatible with iterator interface – use one or the other, not both. 与迭代器的接口是对立的。 timeout_ms (int, optional) – Milliseconds spent waiting in poll if data is not available in the buffer. If 0, returns immediately with any
records that are available currently in the buffer, else returns empty. Must not be negative. Default: 0 max_records (int, optional) – The maximum number of records returned in a single call to poll(). Default: Inherit value from max_poll_records.
默认从max_poll_records继承值。
#一个简答的实例从kafka拉取数据
from kafka import KafkaConsumer import time consumer = KafkaConsumer("kafkatest", bootstrap_servers=['10.0.102.204:9092']) while True: msg = consumer.poll(timeout_ms=5) print(msg) time.sleep(2)
#执行结果如下,返回的是一个字典,consumerRecord对象包含着消息的一些元数据信息
{TopicPartition(topic='kafkatest', partition=2): [ConsumerRecord(topic='kafkatest', partition=2, offset=21929, timestamp=1545978879892, timestamp_type=0, key=b'138', value=b'producer1+138', checksum=-660348132, serialized_key_size=3, serialized_value_size=13)]}
{TopicPartition(topic='kafkatest', partition=0): [ConsumerRecord(topic='kafkatest', partition=0, offset=22064, timestamp=1545978882893, timestamp_type=0, key=b'141', value=b'producer1+141', checksum=-1803506349, serialized_key_size=3, serialized_value_size=13)], TopicPartition(topic='kafkatest', partition=2): [ConsumerRecord(topic='kafkatest', partition=2, offset=21930, timestamp=1545978880892, timestamp_type=0, key=b'139', value=b'producer1+139', checksum=-1863433503, serialized_key_size=3, serialized_value_size=13), ConsumerRecord(topic='kafkatest', partition=2, offset=21931, timestamp=1545978881893, timestamp_type=0, key=b'140', value=b'producer1+140', checksum=-280146643, serialized_key_size=3, serialized_value_size=13)]}
{TopicPartition(topic='kafkatest', partition=2): [ConsumerRecord(topic='kafkatest', partition=2, offset=21932, timestamp=1545978884894, timestamp_type=0, key=b'143', value=b'producer1+143', checksum=1459018748, serialized_key_size=3, serialized_value_size=13)]}
{TopicPartition(topic='kafkatest', partition=1): [ConsumerRecord(topic='kafkatest', partition=1, offset=22046, timestamp=1545978883894, timestamp_type=0, key=b'142', value=b'producer1+142', checksum=-2023137030, serialized_key_size=3, serialized_value_size=13)], TopicPartition(topic='kafkatest', partition=0): [ConsumerRecord(topic='kafkatest', partition=0, offset=22065, timestamp=1545978885894, timestamp_type=0, key=b'144', value=b'producer1+144', checksum=1999922748, serialized_key_size=3, serialized_value_size=13)]}
seek()方法的用法:
seek(partition, offset) Manually specify the fetch offset for a TopicPartition. #手动指定拉取主题的偏移量 Overrides the fetch offsets that the consumer will use on the next poll(). If this API is invoked for the same partition more than once,
the latest offset will be used on the next poll(). #覆盖下一个消费者使用poll()拉取的偏移量。如果这个API对同一个分区执行了多次,那么最后一个次的结果将会被使用。 Note: You may lose data if this API is arbitrarily used in the middle of consumption to reset the fetch offsets. #如果在消费过程中任意使用此API以重置提取偏移,则可能会丢失数据。
#实例如下
>>> consumer.position(TopicPartition(topic="kafkatest",partition=1))
22103
#使用seek()设置偏移量
>>> consumer.seek(partition=TopicPartition("kafkatest",1),offset=22222)
#需要说明的是seek函数有一个partition参数,但是这个参数必须是TopicPartition类型的。
>>> consumer.position(TopicPartition(topic="kafkatest",partition=1))
22222
与seek相关的还有两个方法:
seek_to_beginning(*partitions) #寻找分区最早可用的偏移量 seek_to_end(*partitions) #寻找分区最近可用的偏移量
>>> consumer.seek_to_beginning(TopicPartition("kafkatest",1))
>>> consumer.seek_to_end(TopicPartition("kafkatest",1))
#注意这两个方法的参数都是TopicPartition类型。
subscribe()方法,给当前消费者订阅主题。
Subscribe to a list of topics, or a topic regex pattern. #订阅一个主体列表,或者主题的正则表达式 Partitions will be dynamically assigned via a group coordinator. Topic subscriptions are not incremental: this list will replace the current assignment (if there is one). #分区将会通过分区协调器自动分配。主题订阅不是增量的,这个列表将会替换已经存在的主题。 This method is incompatible with assign(). #这个方法与assign()方法是不兼容的。 #说明一下listener参数:监听回调,该回调将在每次重新平衡操作之前和之后调用。 作为组管理的一部分,消费者将跟踪属于特定组的使用者列表,并在以下事件之一触发时触发重新平衡操作:
任何订阅主题的分区数都会发生变化 主题已创建或删除 消费者组织的现有成员死亡 将新成员添加到使用者组 触发任何这些事件时,将首先调用提供的侦听器以指示已撤消使用者的分配,然后在收到新分配时再次调用。请注意,此侦听器将立即覆盖先前对subscribe的调用中设置的任何侦听器。
但是,可以保证通过此接口撤消/分配的分区来自此呼叫中订阅的主题。
>>> consumer.subscription() #当前消费者订阅的主题 {'lianxi'} >>> consumer.subscribe(("kafkatest","lianxi")) #订阅主题,会覆盖之前的主题 >>> consumer.subscription() #可以看到已经覆盖 {'lianxi', 'kafkatest'}
unsubscribe() :取消订阅所有主题并清除所有已分配的分区。
assign(partitions):
Manually assign a list of TopicPartitions to this consumer.
#手动将TopicPartitions指定给此消费者。
#这个函数和subscribe函数不能同时使用
>>> consumer.assign(TopicPartition("kafkatest",1))
assignment():
Get the TopicPartitions currently assigned to this consumer.
如果分区是使用assign()直接分配的,那么这将只返回先前分配的相同分区。如果使用subscribe()订阅了主题,那么这将给出当前分配给使用者的主题分区集(如果分配尚未发生,
或者分区正在重新分配的过程中,则可能是None)
beginning_offsets(partitions)
Get the first offset for the given partitions. #得到给定分区的第一个偏移量 This method does not change the current consumer position of the partitions. #这个方法不会改变当前消费者的偏移量 This method may block indefinitely if the partition does not exist. #这个方法可能会阻塞,如果给定的分区没有出现。
partitions参数仍然是TopicPartition类型。
>>> consumer.beginning_offsets(TopicPartition("kafkatest",1))
#这个方法在kafka-python-1.3.1中没有
close(autocommit=True)
Close the consumer, waiting indefinitely for any needed cleanup. #关闭消费者,阻塞等待所需要的清理。 Keyword Arguments: autocommit (bool) – If auto-commit is configured for this consumer, this optional flag causes the consumer to attempt to commit any
pending consumed offsets prior to close. Default: True
#如果为此使用者配置了自动提交,则此可选标志会导致使用者在关闭之前尝试提交任何待处理的消耗偏移量。默认值:True
commit(offsets=None)
Commit offsets to kafka, blocking until success or error. #提交偏移量到kafka,阻塞直到成功或者出错 这只向Kafka提交偏移量。使用此API提交的偏移量将在每次重新平衡之后的第一次取出时以及在启动时使用。因此,如果需要在Kafka以外的任何地方存储偏移,则不应该使用此API。
为了避免在重新启动使用者时重新处理读取的最后一条消息,提交的偏移量应该是应用程序应该使用的下一条消息,即:last_offset+1
Parameters: offsets (dict, optional) – {TopicPartition: OffsetAndMetadata} dict to commit with the configured group_id. Defaults to
currently consumed offsets for all subscribed partitions.
commit_async(offsets=None, callback=None)
Commit offsets to kafka asynchronously, optionally firing callback.
#异步提交,可选择的触发回调,其余的和上面的commit一样。
committed(partition)
Get the last committed offset for the given partition. This offset will be used as the position for the consumer in the event of a failure. 如果有问题的分区未分配给此使用者,或者使用者尚未初始化其已提交偏移量缓存,则此调用可能会阻止执行远程调用。
>>> consumer.committed(TopicPartition("kafkatest",1))
22103
pase, pased和resume
pase:暂停当前正在进行的请求。需要使用resume恢复
pased:获取使用pase暂停时的分区信息
resume: 从pase状态恢复。
除了pased之外,其余两个方法的参数均为TopicPartation类型
kafka-python除了有消费者和生成者之外,还有一个客户端,下面我们来说明客户端API。
客户端API
客户端API的官方文档为: https://kafka-python.readthedocs.io/en/master/apidoc/KafkaClient.html
简单说明怎么使用客户端API创建主题。
>>> from kafka.client import KafkaClient >>> kc = KafkaClient(bootstrap_servers="10.0.102.204:9092") >>> kc.config #配置还是蛮多的 {'bootstrap_servers': '10.0.102.204:9092', 'client_id': 'kafka-python-1.3.1', 'request_timeout_ms': 40000, 'reconnect_backoff_ms': 50, 'max_in_flight_requests_per_connection': 5, 'receive_buffer_bytes': None, 'send_buffer_bytes': None, 'socket_options': [(6, 1, 1)], 'retry_backoff_ms': 100, 'metadata_max_age_ms': 300000, 'security_protocol': 'PLAINTEXT', 'ssl_context': None, 'ssl_check_hostname': True, 'ssl_cafile': None, 'ssl_certfile': None, 'ssl_keyfile': None, 'ssl_password': None, 'ssl_crlfile': None, 'api_version': (0, 10), 'api_version_auto_timeout_ms': 2000, 'selector': <class 'selectors.SelectSelector'>, 'metrics': None, 'metric_group_prefix': '', 'sasl_mechanism': None, 'sasl_plain_username': None, 'sasl_plain_password': None}
#这些参数的具体意思可以查看上面的官方文档。
>>> kc.add_topic("clent-1") #添加主题
<kafka.future.Future object at 0x0000000003A92320>
kafka-python还提供了其余两个API,broker连接API和集群连接API