计算机常识
字节
字节是我们常见的计算机中最小存储单元。计算机存储任何的数据,都是以字节的形式存储。8个bit (二进制位)0000-0000表示为1个字节。
8 bit = 1 B 1024 B =1 KB 1024 KB =1 MB 1024 MB =1 GB 1024 GB = 1 TB
二进制:01
十进制:0123456789
16进制:0123456789abcdef
常用DOS命令
按下Windows+R键盘,打开运行窗口,输入cmd回车,进入到DOS的操作窗口。
|
命令 |
操作符号 |
|
盘符切换命令 |
盘符名: |
|
查看当前文件夹 |
dir |
|
进入文件夹命令 |
cd文件夹名 |
|
退出文件夹命令 |
cd.. |
|
退出到磁盘根目录 |
cd |
|
清屏 |
cls |
|
退出 |
exit |
|
进入多级文件夹 |
cd 文件夹1文件夹2文件3 |
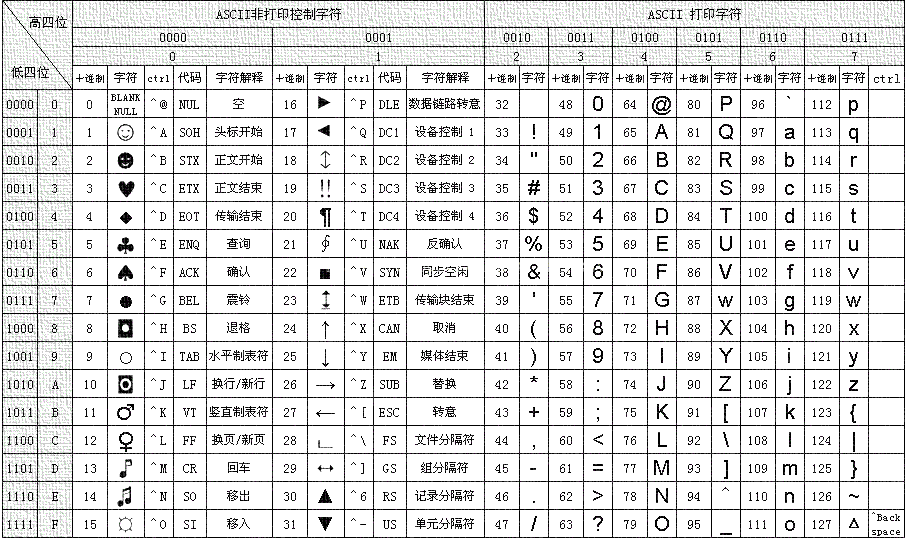
ASCII表
ASCII码表:American Standard Code for Information Interchange,美国信息交换标准代码。
Unicode码表:万国码。也是数字和符号的对照关系,开头0-127部分和ASCII完全一样,但是从128开始包含有更多字符。
Java入门常识
注释
单行注释以//开头换行结束
多行注释以/*开头以*/结束
关键字
1. 完全小写的字母。
2. 在增强版的记事本当中有特殊颜色。
标识符
是指在程序中,我们自己定义内容。比如类的名字、方法的名字和变量的名字等等,都是标识符。
规则:
硬性要求:
标识符可以包含英文字母26个(区分大小写)、0-9数字、$ (美元符号)和_ (下划线)。
标识符不能以数字开头。
标识符不能是关键字。
软性建议:
类名规范:首字母大写,后面每个单词首字母大写(大驼峰式)。
方法名规范:首字母小写,后面每个单词首字母大写(小驼峰式)。
变量名规范:全部小写。
常量
在程序运行期间,固定不变的量。
|
类型 |
含义 |
|
整数常量 |
所有的整数 |
|
小数常量 |
所有的小数 |
|
字符常量 |
单引号引起来,只能写一个字符,必须有内容 |
|
字符串常量 |
双引号引起来,可以写多个字符,也可以不写 |
|
布尔常量 |
只有两个值(true, false) |
|
空常量 |
只有一个值(null) |
变量
程序运行期间,内容可以发生改变的量。
数据类型 变量名称 = 数据值
当打印输出变量名称的时候,显示出来的是变量的内容
右侧数值的范围不能超过左侧数据类型的取值范围
注意:
变量名称:在同一个大括号范围内,变量的名字不可以相同。
变量赋值:定义的变量,不赋值不能使用。
数据类型
|
数据类型 |
关键字 |
内存占用 |
取值范围 |
|
字节型 |
byte |
1个字节 |
-128~127 |
|
短整型 |
short |
2个字节 |
-32768-32767 |
|
整型 |
int (默认) |
4个字节 |
-2的31次方~2的31次方-1 |
|
长整型 |
long |
8个字节 |
-2的63次方~2的63次方-1 |
|
单精度浮点数 |
float |
4个字节 |
1.4013E-45~3.4028E+38 |
|
双精度浮点数 |
double (默认) |
8个字节 |
4.9E-324~1.7977E+308 |
|
字符型 |
char |
2个字节 |
0-65535 |
|
布尔类型 |
boolean |
1个字节 |
true,false |
基本数据类型
整数型 byte short int long
浮点型 float double
字符型 char
布尔型 boolean
引用数据类型
字符串、数组、类、接口、Lambda
注意事项:
1. 字符串不是基本类型,而是引用类型。
2. 浮点型可能只是一个近似值,并非精确的值。
3. 数据范围与字节数不一定相关,例如float数据范围比long更加广泛,但是float是4字节,long是8字节。
4. 浮点数当中默认类型是double。如果一定要使用float类型,需要加上一个后缀F。如果是整数,默认为int类型,如果一定要使用long类型,需要加上一个后缀L。推荐使用大写字母后缀。
数据类型转换
整数,默认就是int类型。浮点数,默认就是double类型
当数据类型不一样时,将会发生数据类型转换。
自动类型转换(隐式)
1. 特点:代码不需要进行特殊处理,自动完成。
2. 规则:数据范围从小到大。
强制类型转换(显式)
1. 特点:代码需要进行特殊的格式处理,不能自动完成。
2. 格式:范围小的类型 范围小的变量名 = (范围小的类型) 原本范围大的数据;
注意事项:
1. 强制类型转换一般不推荐使用,因为有可能发生精度损失、数据溢出。
2. byte/short/char这三种类型都可以发生数学运算。
3. byte/short/char这三种类型在运算的时候,都会被首先提升成为int类型,然后再计算。
4. boolean类型不能发生数据类型转换。
运算符
运算符:进行特定操作的符号。
表达式:用运算符连起来的式子叫做表达式。
四则运算:加:+,减:-,乘:*,除:/,取模(取余数):%
四则运算当中的加号“+”有常见的三种用法:
1. 对于数值来说,那就是加法。
2. 对于字符char类型来说,在计算之前,char会被提升成为int,然后再计算。
3. 对于字符串String(首字母大写,并不是关键字)来说,加号代表字符串连接操作。
注意事项:
对于一个整数的表达式来说,除法用的是整除,整数除以整数,结果仍然是整数。只看商,不看余数。只有对于整数的除法来说,取模运算符才有余数的意义。
一旦运算当中有不同类型的数据,那么结果将会是数据类型范围大的那种。
任何数据类型和字符串进行连接的时候,结果都会变成字符串
自减(加)运算符:--(++)
使用区别:
1. 在单独使用的时候,前++和后++没有任何区别。也就是:++num;和num++;是完全一样的。
2. 在混合的时候,有【重大区别】
A. 如果是【前++】,那么变量【立刻马上+1】,然后拿着结果进行使用。 【先加后用】
B. 如果是【后++】,那么首先使用变量本来的数值,【然后再让变量+1】。 【先用后加】
注意事项:
只有变量才能使用自增、自减运算符。常量不可发生改变,所以不能用。
赋值运算符分为:
基本赋值运算符:就是一个等号“=”,代表将右侧的数据交给左侧的变量。
复合赋值运算符:+=,-=,*=,/=,%=
注意事项:
1. 只有变量才能使用赋值运算符,常量不能进行赋值。
2. 复合赋值运算符其中隐含了一个强制类型转换。
比较运算符:大于: >小于: <大于等于: >=小于等于: <=相等: == 不相等: !=
注意事项:
1. 比较运算符的结果一定是一个boolean值,成立就是true,不成立就是false
2. 如果进行多次判断,不能连着写。
3.数学当中的写法,例如:1 < x <
3,程序当中【不允许】这种写法。
逻辑运算符:
与(并且) && 全都是true,才是true;否则就是false
或(或者) || 至少一个是true,就是true;全都是false,才是false
非(取反) ! 本来是true,变成false;本来是false,变成true
与“&&”,或“||”,具有短路效果:如果根据左边已经可以判断得到最终结果,那么右边的代码将不再执行,从而节省一定的性能。
注意事项:
1. 逻辑运算符只能用于boolean值。
2. 与、或需要左右各自有一个boolean值,但是取反只要有唯一的一个boolean值即可。
3. 与、或两种运算符,如果有多个条件,可以连续写。
两个条件:条件A && 条件B
多个条件:条件A && 条件B
&& 条件C
一元运算符:只需要一个数据就可以进行操作的运算符。
二元运算符:需要两个数据才可以进行操作的运算符。
三元运算符:需要三个数据才可以进行操作的运算符。
格式:
数据类型 变量名称 = 条件判断 ? 表达式A : 表达式B;
流程:
首先判断条件是否成立:
如果成立为true,那么将表达式A的值赋值给左侧的变量;
如果不成立为false,那么将表达式B的值赋值给左侧的变量;
二者选其一。
注意事项:
1. 必须同时保证表达式A和表达式B都符合左侧数据类型的要求。
2. 三元运算符的结果必须被使用。
补充内容:
对于byte/short/char三种类型来说,如果右侧赋值的数值没有超过范围,那么javac编译器将会自动隐含地为我们补上一个(byte)(short)(char)。
1. 如果没有超过左侧的范围,编译器补上强转。
2. 如果右侧超过了左侧范围,那么直接编译器报错。
在给变量进行赋值的时候,如果右侧的表达式当中全都是常量,没有任何变量,那么编译器javac将会直接将若干个常量表达式计算得到结果。例如 short result = 5 + 8; // 等号右边全都是常量,没有任何变量参与运算,编译之后,得到的.class字节码文件当中相当于【直接就是】:short result = 13;右侧的常量结果数值,没有超过左侧范围,所以正确。这称为“编译器的常量优化”。
但是注意:一旦表达式当中有变量参与,那么就不能进行这种优化了。
JShell脚本
启动JShell工具,在DOS命令行直接输入JShell命令。接下来可以编写Java代码,无需写类和方法,直接写方法中的代码即可,同时无需编译和运行,直接回车即可。
小贴士:JShell工具,只适合片段代码的测试,开发更多内容,建议编写在方法中。
Java入门知识
流程控制
判断语句


1 ① 2 if(关系表达式){ 3 语句体; 4 } 5 首先判断关系表达式看其结果是true还是false 6 如果是true就执行语句体 7 如果是false就不执行语句体 8 ② 9 if(关系表达式) { 10 语句体1; 11 }else { 12 语句体2; 13 } 14 首先判断关系表达式看其结果是true还是false 15 如果是true就执行语句体1 16 如果是false就执行语句体2 17 ③ 18 if (判断条件1) { 19 执行语句1; 20 } else if (判断条件2) { 21 执行语句2; 22 } 23 ... 24 }else if (判断条件n) { 25 执行语句n; 26 } else { 27 执行语句n+1; 28 } 29 首先判断关系表达式1看其结果是true还是false 30 如果是true就执行语句体1 31 如果是false就继续判断关系表达式2看其结果是true还是false 32 如果是true就执行语句体2 33 如果是false就继续判断关系表达式…看其结果是true还是false 34 … 35 如果没有任何关系表达式为true,就执行语句体n+1。
选择语句
1 switch(表达式) { 2 case 常量值1: 3 语句体1; 4 break; 5 case 常量值2: 6 语句体2; 7 break; 8 ... 9 default: 10 语句体n+1; 11 break; 12 } 13 首先计算出表达式的值 14 其次,和case依次比较,一旦有对应的值,就会执行相应的语句,在执行的过程中,遇到break就会结束。 15 最后,如果所有的case都和表达式的值不匹配,就会执行default语句体部分,然后程序结束掉。
switch语句使用的注意事项:
1. 多个case后面的数值不可以重复。
2. switch后面小括号当中只能是下列数据类型:
基本数据类型:byte/short/char/int
引用数据类型:String字符串、enum枚举
3. switch语句格式可以很灵活:前后顺序可以颠倒,而且break语句还可以省略。
“匹配哪一个case就从哪一个位置向下执行,直到遇到了break或者整体结束为止。”
循环语句
1 一、for循环 2 for(初始化表达式①; 布尔表达式②; 步进表达式④){ 3 循环体③ 4 } 5 6 执行顺序:①②③④>②③④>②③④…②不满足为止。 7 ①负责完成循环变量初始化 8 ②负责判断是否满足循环条件,不满足则跳出循环 9 ③具体执行的语句 10 ④循环后,循环条件所涉及变量的变化情况 11 12 二、while循环 13 初始化表达式① 14 while(布尔表达式②){ 15 循环体③ 16 步进表达式④ 17 } 18 19 执行顺序:①②③④>②③④>②③④…②不满足为止。 20 ①负责完成循环变量初始化。 21 ②负责判断是否满足循环条件,不满足则跳出循环。 22 ③具体执行的语句。 23 ④循环后,循环变量的变化情况。 24 25 三、do...while循环 26 初始化表达式① 27 do{ 28 循环体③ 29 步进表达式④ 30 }while(布尔表达式②); 31 32 执行顺序:①③④>②③④>②③④…②不满足为止。 33 ①负责完成循环变量初始化。 34 ②负责判断是否满足循环条件,不满足则跳出循环。 35 ③具体执行的语句 36 ④循环后,循环变量的变化情况
循环结构的基本组成部分,一般可以分成四部分:
1. 初始化语句:在循环开始最初执行,而且只做唯一一次。
2. 条件判断:如果成立,则循环继续;如果不成立,则循环退出。
3. 循环体:重复要做的事情内容,若干行语句。
4. 步进语句:每次循环之后都要进行的扫尾工作,每次循环结束之后都要执行一次。
三种循环的区别。
1. 如果条件判断从来没有满足过,那么for循环和while循环将会执行0次,但是do-while循环会执行至少一次。
2. for循环的变量在小括号当中定义,只有循环内部才可以使用。while循环和do-while循环初始化语句本来就在外面,所以出来循环之后还可以继续使用。
关于循环的选择,有一个小建议:
凡是次数确定的场景多用for循环;否则多用while循环。
跳出语句
break关键字的用法有常见的两种:
1. 可以用在switch语句当中,一旦执行,整个switch语句立刻结束。
2. 还可以用在循环语句当中,一旦执行,整个循环语句立刻结束。打断循环。
另一种循环控制语句是continue关键字。
一旦执行,立刻跳过当前次循环剩余内容,马上开始下一次循环。
特殊语句
1 while (true) { 2 循环体 3 }
永远停不下来的循环,叫做死循环。
1 for(初始化表达式①; 循环条件②; 步进表达式⑦) 2 { 3 for(初始化表达式③; 循环条件④; 步进表达式⑥) 4 { 5 执行语句⑤; 6 } 7 } 8 执行顺序:①②③④⑤⑥>④⑤⑥>⑦②③④⑤⑥>④⑤⑥ 9 外循环一次,内循环多次。
所谓嵌套循环,是指一个循环的循环体是另一个循环。
方法
1 修饰符 返回值类型 方法名称(参数类型 参数名称, ...) { 2 方法体 3 return 返回值; 4 } 5 6 修饰符:现阶段的固定写法,public static 7 返回值类型:也就是方法最终产生的数据结果是什么类型 8 方法名称:方法的名字,规则和变量一样,小驼峰 9 参数类型:进入方法的数据是什么类型 10 参数名称:进入方法的数据对应的变量名称 11 12 PS:参数如果有多个,使用逗号进行分隔 13 方法体:方法需要做的事情,若干行代码 14 return:两个作用,第一停止当前方法,第二将后面的返回值还给调用处 15 返回值:也就是方法执行后最终产生的数据结果。 16 17 注意:return后面的“返回值”,必须和方法名称前面的“返回值类型”,保持对应。
方法的三种调用格式。
1. 单独调用:方法名称(参数);
2. 打印调用:System.out.println(方法名称(参数));
3. 赋值调用:数据类型 变量名称 = 方法名称(参数);
注意:返回值类型固定写为void,这种方法只能够单独调用,不能进行打印调用或者赋值调用。
有参数:小括号当中有内容,当一个方法需要一些数据条件,才能完成任务的时候,就是有参数。
无参数:小括号当中留空。一个方法不需要任何数据条件,自己就能独立完成任务,就是无参数。
使用方法的时候,注意事项:
1. 方法应该定义在类当中,但是不能在方法当中再定义方法。不能嵌套。
2. 方法定义的前后顺序无所谓。
3. 方法定义之后不会执行,如果希望执行,一定要调用:单独调用、打印调用、赋值调用。
4. 如果方法有返回值,那么必须写上“return 返回值;”,不能没有。
5. return后面的返回值数据,必须和方法的返回值类型,对应起来。
6. 对于一个void没有返回值的方法,不能写return后面的返回值,只能写return自己。
7. 对于void方法当中最后一行的return可以省略不写。
8. 一个方法当中可以有多个return语句,但是必须保证同时只有一个会被执行到,两个return不能连写。
方法的重载
对于功能类似的方法来说,因为参数列表不一样,却需要记住那么多不同的方法名称,太麻烦。
方法的重载(Overload):多个方法的名称一样,但是参数列表不一样。
好处:只需要记住唯一一个方法名称,就可以实现类似的多个功能。
方法重载与下列因素相关:
1. 参数个数不同
2. 参数类型不同
3. 参数的多类型顺序不同
方法重载与下列因素无关:
1. 与参数的名称无关
2. 与方法的返回值类型无关
数组
生成
数组的概念:是一种容器,可以同时存放多个数据值。
数组的特点:
1. 数组是一种引用数据类型
2. 数组当中的多个数据,类型必须统一
3. 数组的长度在程序运行期间不可改变
数组的初始化:在内存当中创建一个数组,并且向其中赋予一些默认值。
两种常见的初始化方式:
1. 动态初始化(指定长度)
2. 静态初始化(指定内容)
动态初始化数组的格式:
数据类型[] 数组名称 = new 数据类型[数组长度];
解析含义:
左侧数据类型:也就是数组当中保存的数据,全都是统一的什么类型
左侧的中括号:代表我是一个数组
左侧数组名称:给数组取一个名字
右侧的new:代表创建数组的动作
右侧数据类型:必须和左边的数据类型保持一致
右侧中括号的长度:也就是数组当中,到底可以保存多少个数据,是一个int数字
静态初始化基本格式:
标准格式:
数据类型[] 数组名称 = new 数据类型[] { 元素1, 元素2, ...
};
省略格式:
数据类型[] 数组名称 = { 元素1, 元素2, ... };
注意事项:
虽然静态初始化没有直接告诉长度,但是根据大括号里面的元素具体内容,也可以自动推算出来长度。
动态初始化(指定长度):在创建数组的时候,直接指定数组当中的数据元素个数。
静态初始化(指定内容):在创建数组的时候,不直接指定数据个数多少,而是直接将具体的数据内容进行指定。
注意事项:
1. 静态初始化没有直接指定长度,但是仍然会自动推算得到长度。
2. 静态初始化标准格式可以拆分成为两个步骤。
3. 动态初始化也可以拆分成为两个步骤。
4. 静态初始化一旦使用省略格式,就不能拆分成为两个步骤了。
使用建议:
如果不确定数组当中的具体内容,用动态初始化;否则,已经确定了具体的内容,用静态初始化。
调用
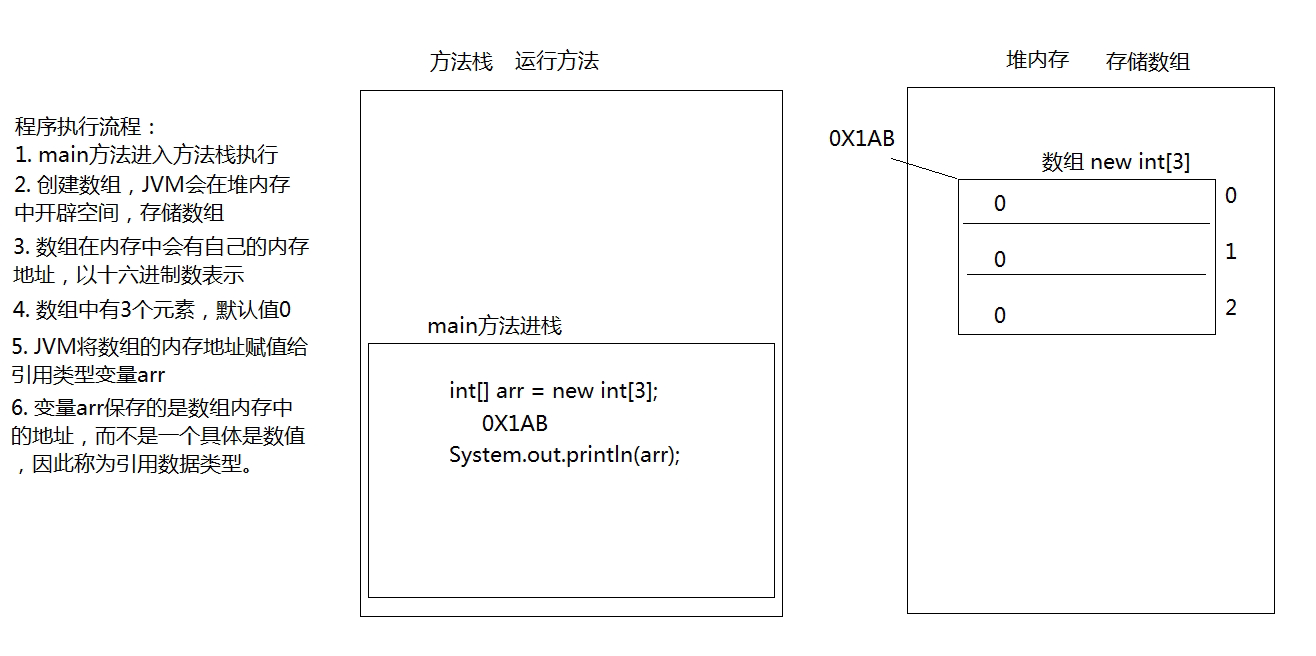
直接打印数组名称,得到的是数组对应的:内存地址哈希值。
访问数组元素的格式:数组名称[索引值]
索引值:就是一个int数字,代表数组当中元素的编号。
注意:索引值从0开始,一直到“数组的长度-1”为止。
使用动态初始化数组的时候,其中的元素将会自动拥有一个默认值。规则如下:
如果是整数类型,那么默认为0;
如果是浮点类型,那么默认为0.0;
如果是字符类型,那么默认为'u0000';
如果是布尔类型,那么默认为false;
如果是引用类型,那么默认为null。
注意事项:
静态初始化其实也有默认值的过程,只不过系统自动马上将默认值替换成为了大括号当中的具体数值。
如果访问数组元素的时候,索引编号并不存在,那么将会发生数组索引越界异常 ArrayIndexOutOfBoundsException。
所有的引用类型变量,都可以赋值为一个null值。但是代表其中什么都没有。
数组必须进行new初始化才能使用其中的元素。
如果只是赋值了一个null,没有进行new创建,那么将会发生:空指针异常 NullPointerException
如何获取数组的长度,格式:
数组名称.length
这将会得到一个int数字,代表数组的长度。
遍历数组,说的就是对数组当中的每一个元素进行逐一、挨个儿处理。默认的处理方式就是打印输出。
数组可以作为方法的参数:
当调用方法的时候,向方法的小括号进行传参,传递进去的其实是数组的地址值。
一个方法可以有0、1、多个参数;但是只能有0或者1个返回值,不能有多个返回值。如果希望一个方法当中产生了多个结果数据进行返回,使用一个数组作为返回值类型即可。
任何数据类型都能作为方法的参数类型,或者返回值类型。数组作为方法的参数,传递进去的其实是数组的地址值。数组作为方法的返回值,返回的其实也是数组的地址值。
为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
| 区域名称 | 作用 |
| 寄存器 | 给CPU使用,和我们开发无关。 |
| 本地方法栈 | JVM在使用操作系统功能的时候使用,和我们开发无关。 |
| 方法区 | 存储可以运行的class文件。 |
| 堆内存 | 存储对象或者数组,new来创建的,都存储在堆内存。 |
| 方法栈 | 方法运行时使用的内存,比如main方法运行,进入方法栈中执行。 |
面向对象
面向过程:当需要实现一个功能的时候,每一个具体的步骤都要亲力亲为,详细处理每一个细节。
面向对象:当需要实现一个功能的时候,不关心具体的步骤,而是找一个已经具有该功能的人,来帮我做事儿。
类:是一组相关属性和行为的集合。可以看成是一类事物的模板,使用事物的属性特征和行为特征来描述该类事物。
现实中,描述一类事物:
属性:就是该事物的状态信息。
行为:就是该事物能够做什么。
对象:是一类事物的具体体现。对象是类的一个实例(对象并不是找个女朋友),必然具备该类事物的属性和行为。
类是对一类事物的描述,是抽象的。对象是一类事物的实例,是具体的。类是对象的模板,对象是类的实体。
成员变量的默认值:
| 数据类型 | 默认值 | |
| 基本类型 | 整数(byte,short,int,long) | 0 |
| 浮点数(float,double) | 0.0 | |
| 字符(char) | 'u0000' | |
| 布尔(boolean) | false | |
| 引用类型 | 数组,类,接口 | null |
通常情况下,一个类并不能直接使用,需要根据类创建一个对象,才能使用。
1. 导包:也就是指出需要使用的类,在什么位置。
import 包名称.类名称;
对于和当前类属于同一个包的情况,可以省略导包语句不写。
2. 创建,格式:
类名称 对象名 = new 类名称();
3. 使用,分为两种情况:
使用成员变量:对象名.成员变量名
使用成员方法:对象名.成员方法名(参数)
(也就是,想用谁,就用对象名点儿谁。)
注意事项:
1.如果成员变量没有进行赋值,那么将会有一个默认值,规则和数组一样。
2.成员变量是直接定义在类当中的,在方法外边。
3. 成员方法不要写static关键字。
局部变量和成员变量
1. 定义的位置不一样
局部变量:在方法的内部
成员变量:在方法的外部,直接写在类当中
2. 作用范围不一样
局部变量:只有方法当中才可以使用,出了方法就不能再用
成员变量:整个类全都可以通用。
3. 默认值不一样
局部变量:没有默认值,如果要想使用,必须手动进行赋值
成员变量:如果没有赋值,会有默认值,规则和数组一样
4. 内存的位置不一样
局部变量:位于栈内存
成员变量:位于堆内存
5. 生命周期不一样
局部变量:随着方法进栈而诞生,随着方法出栈而消失
成员变量:随着对象创建而诞生,随着对象被垃圾回收而消失
面向对象三大特征:封装、继承、多态。
封装性在Java当中的体现:封装就是将一些细节信息隐藏起来,对于外界不可见。
1. 方法就是一种封装
2. 关键字private也是一种封装
问题描述:定义Person的年龄时,无法阻止不合理的数值被设置进来。
解决方案:用private关键字将需要保护的成员变量进行修饰。
一旦使用了private进行修饰,那么本类当中仍然可以随意访问。但是!超出了本类范围之外就不能再直接访问了。
private的含义:
1. private是一个权限修饰符,代表最小权限。
2. 可以修饰成员变量和成员方法。
3. 被private修饰后的成员变量和成员方法,只在本类中才能访问。
间接访问private成员变量,就是定义一对儿Getter/Setter方法,必须叫setXxx或者是getXxx命名规则。
对于Getter来说,不能有参数,返回值类型和成员变量对应;
对于Setter来说,不能有返回值,参数类型和成员变量对应。
对于基本类型当中的boolean值,Getter方法一定要写成isXxx的形式,而setXxx规则不变。
当方法的局部变量和类的成员变量重名的时候,根据“就近原则”,优先使用局部变量。
如果需要访问本类当中的成员变量,需要使用格式:this.成员变量名,“通过谁调用的方法,谁就是this。”
构造方法是专门用来创建对象的方法,当我们通过关键字new来创建对象时,其实就是在调用构造方法。
1 public 类名称(参数类型 参数名称) { 2 方法体 3 }
注意事项:
1. 构造方法的名称必须和所在的类名称完全一样,就连大小写也要一样
2. 构造方法不要写返回值类型,连void都不写
3. 构造方法不能return一个具体的返回值
4. 如果没有编写任何构造方法,那么编译器将会默认赠送一个构造方法,没有参数、方法体什么事情都不做。
5. 一旦编写了至少一个构造方法,那么编译器将不再赠送。
6. 构造方法也是可以进行重载的。重载:方法名称相同,参数列表不同。
一个标准的类通常要拥有下面四个组成部分:
1. 所有的成员变量都要使用private关键字修饰
2. 为每一个成员变量编写一对儿Getter/Setter方法
3. 编写一个无参数的构造方法
4. 编写一个全参数的构造方法
这样标准的类也叫做Java Bean.
常用类介绍(Scanner,Random,Arraylist)
API(Application Programming Interface),应用程序编程接口。Java API是一本程序员的字典 ,是JDK中提供给我们使用的类的说明文档。这些类将底层的代码实现封装了起来,我们不需要关心这些类是如何实现的,只需要学习这些类如何使用即可。所以我们可以通过查询API的方式,来学习Java提供的类,并得知如何使用它们。
引用类型的一般使用步骤:
1. 导包
import 包路径.类名称;
如果需要使用的目标类,和当前类位于同一个包下,则可以省略导包语句不写。
注意:只有java.lang包下的内容不需要导包,其他的包都需要import语句。
2. 创建
类名称 对象名 = new 类名称();
3. 使用
对象名.成员方法名()
Scanner类的功能:可以实现键盘输入数据,到程序当中。
获取键盘输入的一个int数字:int
num = sc.nextInt();
获取键盘输入的一个字符串:String str = sc.next();
匿名对象:就是只有右边的对象,没有左边的名字和赋值运算符。
格式:new 类名称();
注意事项:匿名对象只能使用唯一的一次,下次再用不得不再创建一个新对象。
使用建议:如果确定有一个对象只需要使用唯一的一次,就可以用匿名对象。
Random类用来生成随机数字。使用起来也是三个步骤:
1. 导包
import java.util.Random;
2. 创建
Random r = new Random(); // 小括号当中留空即可
3. 使用
获取一个随机的int数字(范围是int所有范围,有正负两种):int num = r.nextInt()
获取一个随机的int数字(参数代表了范围,左闭右开区间):int num = r.nextInt(3),实际上代表的含义是:[0,3),也就是0~2。
ArrayList:集合的长度是可以随意变化的。
对于ArrayList来说,有一个尖括号<E>代表泛型。
泛型:也就是装在集合当中的所有元素,全都是统一的什么类型。
注意:泛型只能是引用类型,不能是基本类型。
注意事项:
对于ArrayList集合来说,直接打印得到的不是地址值,而是内容。如果内容是空,得到的是空的中括号:[]
ArrayList当中的常用方法有:
public boolean add(E e):向集合当中添加元素,参数的类型和泛型一致。返回值代表添加是否成功。
备注:对于ArrayList集合来说,add添加动作一定是成功的,所以返回值可用可不用。但是对于其他集合(今后学习)来说,add添加动作不一定成功。
public E get(int index):从集合当中获取元素,参数是索引编号,返回值就是对应位置的元素。
public E remove(int index):从集合当中删除元素,参数是索引编号,返回值就是被删除掉的元素。
public int size():获取集合的尺寸长度,返回值是集合中包含的元素个数。
如果希望向集合ArrayList当中存储基本类型数据,必须使用基本类型对应的“包装类”。
基本类型
|
包装类(引用类型,包装类都位于java.lang包下)
|
byte
|
Byte
|
short
|
Short
|
int
|
Integer 【特殊】
|
long
|
Long
|
float
|
Float
|
double
|
Double
|
char
|
Character 【特殊】
|
boolean
|
Boolean
|
从JDK 1.5+开始,支持自动装箱、自动拆箱。
自动装箱:基本类型 --> 包装类型
自动拆箱:包装类型 --> 基本类型
字符串String
java.lang.String类代表字符串。
API当中说:Java 程序中的所有字符串字面值(如
"abc" )都作为此类的实例实现。
其实就是说:程序当中所有的双引号字符串,都是String类的对象。(就算没有new,也照样是。)
字符串的特点:
1. 字符串的内容永不可变。【重点】
2. 正是因为字符串不可改变,所以字符串是可以共享使用的。
3. 字符串效果上相当于是char[]字符数组,但是底层原理是byte[]字节数组。
创建字符串的常见3+1种方式。
三种构造方法:
public String():创建一个空白字符串,不含有任何内容。
public String(char[] array):根据字符数组的内容,来创建对应的字符串。
public String(byte[] array):根据字节数组的内容,来创建对应的字符串。
一种直接创建:
String str = "Hello"; // 右边直接用双引号
注意:直接写上双引号,就是字符串对象。
字符串常量池:程序当中直接写上的双引号字符串,就在字符串常量池中。
对于基本类型来说,==是进行数值的比较。
对于引用类型来说,==是进行【地址值】的比较。
==是进行对象的地址值比较,如果确实需要字符串的内容比较,可以使用两个方法:
public boolean equals(Object obj):参数可以是任何对象,只有参数是一个字符串并且内容相同的才会给true;否则返回false。
注意事项:
1. 任何对象都能用Object进行接收。
2. equals方法具有对称性,也就是a.equals(b)和b.equals(a)效果一样。
3. 如果比较双方一个常量一个变量,推荐把常量字符串写在前面。
推荐:"abc".equals(str) 不推荐:str.equals("abc")
public boolean equalsIgnoreCase(String str):忽略大小写,进行内容比较。
String当中与获取相关的常用方法有:
public int length():获取字符串当中含有的字符个数,拿到字符串长度。
public String concat(String str):将当前字符串和参数字符串拼接成为返回值新的字符串。
public char charAt(int index):获取指定索引位置的单个字符。(索引从0开始。)
public int indexOf(String str):查找参数字符串在本字符串当中首次出现的索引位置,如果没有返回-1值。
字符串的截取方法:
public String substring(int index):截取从参数位置一直到字符串末尾,返回新字符串。
public String substring(int begin, int end):截取从begin开始,一直到end结束,中间的字符串。
备注:[begin,end),包含左边,不包含右边。
分割字符串的方法:
public String[] split(String regex):按照参数的规则,将字符串切分成为若干部分。
注意事项:
split方法的参数其实是一个“正则表达式”。
今天要注意:如果按照英文句点“.”进行切分,必须写"\."(两个反斜杠)
static关键字
如果一个成员变量使用了static关键字,那么这个变量不再属于对象自己,而是属于所在的类。多个对象共享同一份数据。
一旦使用static修饰成员方法,那么这就成为了静态方法。静态方法不属于对象,而是属于类的。
如果没有static关键字,那么必须首先创建对象,然后通过对象才能使用它。
如果有了static关键字,那么不需要创建对象,直接就能通过类名称来使用它。
无论是成员变量,还是成员方法。如果有了static,都推荐使用类名称进行调用。
静态变量:类名称.静态变量
静态方法:类名称.静态方法()
注意事项:
1. 静态不能直接访问非静态。
原因:因为在内存当中是【先】有的静态内容,【后】有的非静态内容。
2. 静态方法当中不能用this。
原因:this代表当前对象,通过谁调用的方法,谁就是当前对象。
静态代码块:
public class 类名称 { static { // 静态代码块的内容 } }
特点:当第一次用到本类时,静态代码块执行唯一的一次。
静态内容总是优先于非静态,所以静态代码块比构造方法先执行。
静态代码块的典型用途:
用来一次性地对静态成员变量进行赋值。
常用数组及数学类方法
数组:
java.util.Arrays是一个与数组相关的工具类,里面提供了大量静态方法,用来实现数组常见的操作。
public static String toString(数组):将参数数组变成字符串(按照默认格式:[元素1, 元素2, 元素3...])
public static void sort(数组):按照默认升序(从小到大)对数组的元素进行排序。
备注:
1. 如果是数值,sort默认按照升序从小到大
2. 如果是字符串,sort默认按照字母升序
3. 如果是自定义的类型,那么这个自定义的类需要有Comparable或者Comparator接口的支持。
数学:
java.util.Math类是数学相关的工具类,里面提供了大量的静态方法,完成与数学运算相关的操作。
public static double abs(double num):获取绝对值。有多种重载。
public static double ceil(double num):向上取整。
public static double floor(double num):向下取整。
public static long round(double num):四舍五入。
Math.PI代表近似的圆周率常量(double)。
继承
继承:就是子类继承父类的属性和行为,使得子类对象具有与父类相同的属性、相同的行为。子类可以直接访问父类中的非私有的属性和行为。
好处
1. 提高代码的复用性。
2. 类与类之间产生了关系,是多态的前提。
在继承的关系中,“子类就是一个父类”。也就是说,子类可以被当做父类看待。
定义父类的格式:(一个普通的类定义)
public class 父类名称 {
// ...
}
定义子类的格式:
public class 子类名称 extends 父类名称 {
// ...
}
在父子类的继承关系当中,如果成员变量重名,则创建子类对象时,访问有两种方式:
直接通过子类对象访问成员变量:
等号左边是谁,就优先用谁,没有则向上找。
间接通过成员方法访问成员变量:
该方法属于谁,就优先用谁,没有则向上找。
局部变量: 直接写成员变量名
本类的成员变量: this.成员变量名
父类的成员变量:
super.成员变量名
在父子类的继承关系当中,创建子类对象,访问成员方法的规则:
创建的对象是谁,就优先用谁,如果没有则向上找。
注意事项:
无论是成员方法还是成员变量,如果没有都是向上找父类,绝对不会向下找子类的。
重写(Override)
概念:在继承关系当中,方法的名称一样,参数列表也一样。
重写(Override):方法的名称一样,参数列表【也一样】。覆盖、覆写。
重载(Overload):方法的名称一样,参数列表【不一样】。
方法的覆盖重写特点:创建的是子类对象,则优先用子类方法。
方法覆盖重写的注意事项:
1. 必须保证父子类之间方法的名称相同,参数列表也相同。
@Override:写在方法前面,用来检测是不是有效的正确覆盖重写。
这个注解就算不写,只要满足要求,也是正确的方法覆盖重写。
2. 子类方法的返回值必须【小于等于】父类方法的返回值范围。
小扩展提示:java.lang.Object类是所有类的公共最高父类(祖宗类),java.lang.String就是Object的子类。
3. 子类方法的权限必须【大于等于】父类方法的权限修饰符。
小扩展提示:public > protected > (default) >
private
备注:(default)不是关键字default,而是什么都不写,留空。
继承关系中,父子类构造方法的访问特点:
1. 子类构造方法当中有一个默认隐含的“super()”调用,所以一定是先调用的父类构造,后执行的子类构造。
2. 子类构造可以通过super关键字来调用父类重载构造。
3. super的父类构造调用,必须是子类构造方法的第一个语句。不能一个子类构造调用多次super构造。
总结:
子类必须调用父类构造方法,不写则赠送super();写了则用写的指定的super调用,super只能有一个,还必须是第一个。
super关键字的用法有三种:
1. 在子类的成员方法中,访问父类的成员变量。
2. 在子类的成员方法中,访问父类的成员方法。
3. 在子类的构造方法中,访问父类的构造方法。
super关键字用来访问父类内容,而this关键字用来访问本类内容。用法也有三种:
1. 在本类的成员方法中,访问本类的成员变量。
2. 在本类的成员方法中,访问本类的另一个成员方法。
3. 在本类的构造方法中,访问本类的另一个构造方法。
在第三种用法当中要注意:
A. this(...)调用也必须是构造方法的第一个语句,唯一一个。
B. super和this两种构造调用,不能同时使用。
抽象类
抽象方法:就是加上abstract关键字,然后去掉大括号,直接分号结束。
抽象类:抽象方法所在的类,必须是抽象类才行。在class之前写上abstract即可。
如何使用抽象类和抽象方法:
1. 不能直接创建new抽象类对象。
2. 必须用一个子类来继承抽象父类。
3. 子类必须覆盖重写抽象父类当中所有的抽象方法。
覆盖重写(实现):子类去掉抽象方法的abstract关键字,然后补上方法体大括号。
4. 创建子类对象进行使用。
一个抽象类不一定含有抽象方法,
只要保证抽象方法所在的类是抽象类,即可。
这样没有抽象方法的抽象类,也不能直接创建对象,在一些特殊场景下有用途。
接口(interface)
接口就是多个类的公共规范。
接口是一种引用数据类型,最重要的内容就是其中的:抽象方法。
public interface 接口名称 { // 接口内容 }
备注:换成了关键字interface之后,编译生成的字节码文件仍然是:.java --> .class。
各版本区别:
在Java 9+版本中,接口的内容可以有:
1. 成员变量其实是常量:
[public] [static] [final] 数据类型 常量名称 = 数据值;
注意:
常量必须进行赋值,而且一旦赋值不能改变。
常量名称完全大写,用下划线进行分隔。
2. 接口中最重要的就是抽象方法:
[public] [abstract] 返回值类型 方法名称(参数列表);
注意:实现类必须覆盖重写接口所有的抽象方法,除非实现类是抽象类。
3. 从Java 8开始,接口里允许定义默认方法:
[public] default 返回值类型 方法名称(参数列表) { 方法体 }
注意:默认方法也可以被覆盖重写
4. 从Java 8开始,接口里允许定义静态方法,格式:
[public] static 返回值类型 方法名称(参数列表) { 方法体 }
注意:应该通过接口名称进行调用,不能通过实现类对象调用接口静态方法
5. 从Java 9开始,接口里允许定义私有方法:
普通私有方法:private 返回值类型 方法名称(参数列表) { 方法体 } 静态私有方法:private static 返回值类型 方法名称(参数列表) { 方法体 }
注意:private的方法只有接口自己才能调用,不能被实现类或别人使用。
接口使用步骤:
1. 接口不能直接使用,必须有一个“实现类”来“实现”该接口。
public class 实现类名称 implements 接口名称 { // ... }
2. 接口的实现类必须覆盖重写(实现)接口中所有的抽象方法。
实现:去掉abstract关键字,加上方法体大括号。
3. 创建实现类的对象,进行使用。
注意事项:
如果实现类并没有覆盖重写接口中所有的抽象方法,那么这个实现类自己就必须是抽象类。
默认方法:
public default 返回值类型 方法名称(参数列表) { 方法体 }
接口的默认方法,可以通过接口实现类对象,直接调用。
接口的默认方法,也可以被接口实现类进行覆盖重写。
备注:接口当中的默认方法,可以解决接口升级的问题。
静态方法:
public static 返回值类型 方法名称(参数列表) { 方法体 }
注意事项:不能通过接口实现类的对象来调用接口当中的静态方法。
正确用法:通过接口名称,直接调用其中的静态方法。
提示:就是将abstract或者default换成static即可,带上方法体。
抽象方法:
public abstract 返回值类型 方法名称(参数列表);
注意事项:
1. 接口当中的抽象方法,修饰符必须是两个固定的关键字:public abstract
2. 这两个关键字修饰符,可以选择性地省略。
3. 方法的三要素,可以随意定义。
常量:
接口当中也可以定义“成员变量”,但是必须使用public static final三个关键字进行修饰。
从效果上看,这其实就是接口的【常量】。
public static final 数据类型 常量名称 = 数据值;
备注:
一旦使用final关键字进行修饰,说明不可改变。
注意事项:
1. 接口当中的常量,可以省略public
static final,注意:不写也照样是这样。
2. 接口当中的常量,必须进行赋值;不能不赋值。
3. 接口中常量的名称,使用完全大写的字母,用下划线进行分隔。(推荐命名规则)
私有方法:
问题描述:
我们需要抽取一个共有方法,用来解决两个默认方法之间重复代码的问题。
但是这个共有方法不应该让实现类使用,应该是私有化的。
解决方案:定义为私有方法。
1. 普通私有方法:用来解决两个默认方法之间重复代码的问题
private 返回值类型 方法名称(参数列表) { 方法体 }
2. 静态私有方法,解决多个静态方法之间重复代码问题
格式:
private static 返回值类型 方法名称(参数列表) { 方法体 }
使用接口的时候,需要注意:
1. 接口是没有静态代码块或者构造方法的。
2. 一个类的直接父类是唯一的,但是一个类可以同时实现多个接口。
public class MyInterfaceImpl implements MyInterfaceA, MyInterfaceB { // 覆盖重写所有抽象方法 }
3. 如果实现类所实现的多个接口当中,存在重复的抽象方法,那么只需要覆盖重写一次即可。
4. 如果实现类没有覆盖重写所有接口当中的所有抽象方法,那么实现类就必须是一个抽象类。
5. 如果实现类所实现的多个接口当中,存在重复的默认方法,那么实现类一定要对冲突的默认方法进行覆盖重写。
6. 一个类如果直接父类当中的方法,和接口当中的默认方法产生了冲突,优先用父类当中的方法。
注意事项:
1. 类与类之间是单继承的。直接父类只有一个。
2. 类与接口之间是多实现的。一个类可以实现多个接口。
3. 接口与接口之间是多继承的。
注意事项:
1. 多个父接口当中的抽象方法如果重复,没关系。
2. 多个父接口当中的默认方法如果重复,那么子接口必须进行默认方法的覆盖重写,【而且带着default关键字】。
多态
代码当中体现多态性,其实就是一句话:父类引用指向子类对象。
父类名称 对象名 = new 子类名称(); 或者: 接口名称 对象名 = new 实现类名称();
访问成员变量的两种方式:
1. 直接通过对象名称访问成员变量:看等号左边是谁,优先用谁,没有则向上找。
2. 间接通过成员方法访问成员变量:看该方法属于谁,优先用谁,没有则向上找。
在多态的代码当中,成员方法的访问规则是:
看new的是谁,就优先用谁,没有则向上找。
口诀:编译看左边,运行看右边。
对比一下:
成员变量:编译看左边,运行还看左边。
成员方法:编译看左边,运行看右边。
向上转型一定是安全的,没有问题的,正确的。但是也有一个弊端:对象一旦向上转型为父类,那么就无法调用子类原本特有的内容。
解决方案:用对象的向下转型【还原】。
实现类 变量名=(实现类)接口
如何才能知道一个父类引用的对象,本来是什么子类?
对象 instanceof 类名称
这将会得到一个boolean值结果,也就是判断前面的对象能不能当做后面类型的实例。
final关键字
final关键字代表最终、不可改变的。
类:被修饰的类,不能被继承。
方法:被修饰的方法,不能被重写。
变量:被修饰的变量,不能被重新赋值。
常见四种用法:
1. 可以用来修饰一个类
2. 可以用来修饰一个方法
3. 还可以用来修饰一个局部变量
4. 还可以用来修饰一个成员变量
当final关键字用来修饰一个方法的时候,这个方法就是最终方法,也就是不能被覆盖重写。
final修饰一个方法格式 注意事项:
对于类、方法来说,abstract关键字和final关键字不能同时使用,因为矛盾。
public final class 类名称 { // ... }
含义:当前这个类不能有任何的子类。
注意:一个类如果是final的,那么其中所有的成员方法都无法进行覆盖重写。
对于成员变量:
如果使用final关键字修饰,那么这个变量也照样是不可变。
1. 由于成员变量具有默认值,所以用了final之后必须手动赋值,不会再给默认值了。
2. 对于final的成员变量,要么使用直接赋值,要么通过构造方法赋值。二者选其一。
3. 必须保证类当中所有重载的构造方法,都最终会对final的成员变量进行赋值。
Java中有四种权限修饰符:
public >
|
protected >
|
(default) >
|
private
|
|
同一个类(我自己) |
YES
|
YES
|
YES
|
|
同一个包(我邻居) |
YES | YES | YES | NO |
不同包子类(我儿子) |
YES | YES | NO | NO |
不同包非子类(陌生人) |
YES | NO | NO | NO |
注意事项:(default)并不是关键字“default”,而是根本不写。
内部类声明及调用:
外部类名称.内部类名称 对象名 = new 外部类名称().new 内部类名称();
如果出现了重名现象,那么格式是:外部类名称.this.外部类成员变量名
局部内部类:
class 外部类 { class 内部类{ } }
如果一个类是定义在一个方法内部的,那么这就是一个局部内部类。
内部类可以直接访问外部类的成员,包括私有成员。
外部类要访问内部类的成员,必须要建立内部类的对象。
内部类仍然是一个独立的类,在编译之后会内部类会被编译成独立的.class文件,但是前面冠以外部类的类名和$符号 。
“局部”:只有当前所属的方法才能使用它,出了这个方法外面就不能用了。
如果希望访问所在方法的局部变量,那么这个局部变量必须是【有效final的】。
备注:从Java 8+开始,只要局部变量事实不变,那么final关键字可以省略。
原因:
1. new出来的对象在堆内存当中。
2. 局部变量是跟着方法走的,在栈内存当中。
3. 方法运行结束之后,立刻出栈,局部变量就会立刻消失。
4. 但是new出来的对象会在堆当中持续存在,直到垃圾回收消失。
修饰符 class 外部类名称 { 修饰符 返回值类型 外部类方法名称(参数列表) { class 局部内部类名称 { // ... } } }
小节一下类的权限修饰符:
public > protected > (default) > private
定义一个类的时候,权限修饰符规则:
1. 外部类:public / (default)
2. 成员内部类:public / protected
/ (default) / private
3. 局部内部类:什么都不能写
匿名内部类:
前提:匿名内部类必须继承一个父类或者实现一个父接口。
如果接口的实现类(或者是父类的子类)只需要使用唯一的一次,
那么这种情况下就可以省略掉该类的定义,而改为使用【匿名内部类】。
接口名称 对象名 = new 接口名称() { // 覆盖重写所有抽象方法 };
对格式“new 接口名称() {...}”进行解析:
1. new代表创建对象的动作
2. 接口名称就是匿名内部类需要实现哪个接口
3. {...}这才是匿名内部类的内容
另外还要注意几点问题:
1. 匿名内部类,在【创建对象】的时候,只能使用唯一一次。
如果希望多次创建对象,而且类的内容一样的话,那么就需要使用单独定义的实现类了。
2. 匿名对象,在【调用方法】的时候,只能调用唯一一次。
如果希望同一个对象,调用多次方法,那么必须给对象起个名字。
3. 匿名内部类是省略了【实现类/子类名称】,但是匿名对象是省略了【对象名称】
强调:匿名内部类和匿名对象不是一回事
引用类型用法总结:
类作为成员变量时,对它进行赋值的操作,实际上,是赋给它该类的一个对象。
我们使用一个接口,作为成员变量,以便随时更换技能,这样的设计更为灵活,增强了程序的扩展性。
接口作为成员变量时,对它进行赋值的操作,实际上,是赋给它该接口的一个子类对象。
接口作为参数时,传递它的子类对象。
接口作为返回值类型时,返回它的子类对象。