安装对应的包:pandas、xlsrd、openpyxl
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests pandas
pip install xlrd==1.2.0
pip install openpyxl
1. 读取
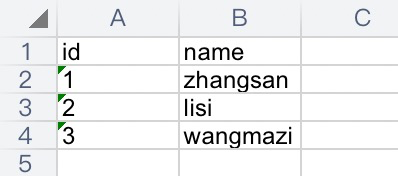
例如:原始表格如下:
方法一(较简洁,推荐使用):
import pandas as pd # 导入pandas包 file = './abc1.csv' # 读取文件 1.io:excel文件路径 2.sheet_name:sheet页签名字 3.header:略过表头(默认0:第一行,None:不略过)
# 这种方法对于xlsx、xls、csv格式的文件,均可读取
data = pd.read_excel(io=file, sheet_name='Sheet1', header=0) print(len(data)) # 数据行的行数(不包括表头) print(data.values) # 表中数据(不包括表头) for val in data.values: # 逐行打印数据 print(val) print(data.head()) # 打印包括表头在内的所有数据
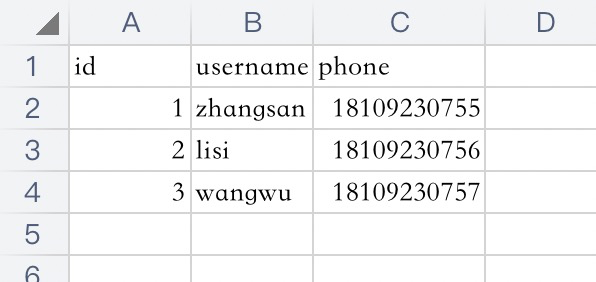
打印结果如下:

方法二:
import xlrd # 导入xlrd包 # 这种方法对xlsx、xls、csv均适用 file1 = '/Users/zhangyang/PycharmProjects/untitled/abc1.xlsx' workbook = xlrd.open_workbook(filename=file1) # 打开工作表 booksheet = workbook.sheet_by_index(0) # 获取sheet页(通过索引,0:第一个) booksheet1 = workbook.sheet_by_name('Sheet1') # 获取sheet页(通过sheet页名称) print(booksheet1.nrows) # nrows获取总行数(包括表头),nclos获取总列数 for i in range(booksheet1.nrows): print(booksheet1.row_values(i)) # 打印整行 for i in range(booksheet1.nrows): print(booksheet1.row_values(i, 1, 2)) # 打印每行中的某几列 print(booksheet1.cell_value(1, 2)) # 打印某个单元格
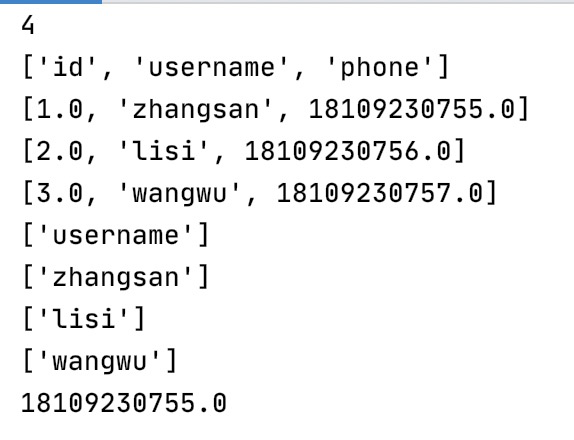
打印结果如下:
2. 写入
方法一(仅支持xls、xlsx,不支持csv):
import numpy as np import pandas as pd data1 = np.random.randint(0, 101, size=[5, 3]) # 数据:1-888之间,5行3列的列表 colum = ['语文', '数学', '英语'] # 列标题 index = ['a', 'b', 'c', 'd', 'e'] # 行标题 df1 = pd.DataFrame(data=data1, columns=colum, index=index) # 创建pandas数据框架,传入数据、列标题、行标题 df1.to_excel('./salary.xls', # excel文件名 sheet_name='salary11', # sheet页名字 header=True, # 是否展示列标题 index=True) # 是否展示行标题
结果如下:
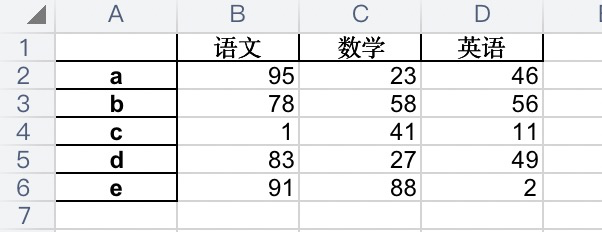
ps1:如果不展示行列标题:
import numpy as np import pandas as pd data1 = np.random.randint(0, 101, size=[5, 3]) # 数据:1-888之间,5行3列的列表 colum = ['语文', '数学', '英语'] # 列标题 index = ['a', 'b', 'c', 'd', 'e'] # 行标题 df1 = pd.DataFrame(data=data1, columns=colum, index=index) # 创建pandas数据框架,传入数据、列标题、行标题 df1.to_excel('./score.xls', # excel文件名 sheet_name='score1', # sheet页名字 header=False, # 是否展示列标题 index=False) # 是否展示行标题
结果如下:
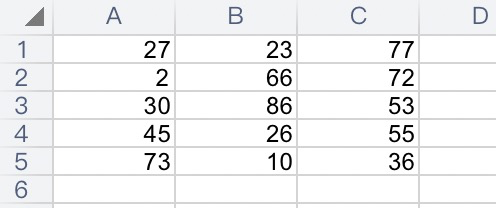
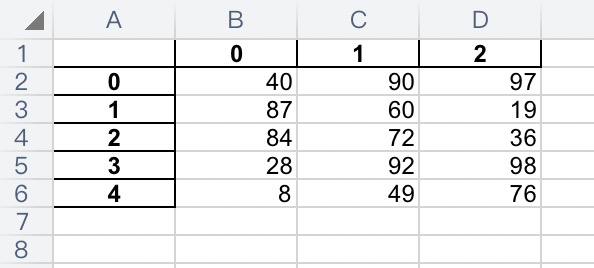
ps2:如果未传入行列标题,但又想展示,会使用默认值0123:
import numpy as np import pandas as pd data1 = np.random.randint(0, 101, size=[5, 3]) # 数据:1-888之间,5行3列的列表 colum = ['语文', '数学', '英语'] # 列标题 index = ['a', 'b', 'c', 'd', 'e'] # 行标题 df1 = pd.DataFrame(data=data1) # 创建pandas数据框架,传入数据、列标题、行标题 df1.to_excel('./score.xls', # excel文件名 sheet_name='score1', # sheet页名字 header=True, # 是否展示列标题 index=True) # 是否展示行标题
结果如下:
ps3:如果一次写入多个sheet页
import pandas as pd data1 = np.random.randint(0, 101, size=[5, 3]) # 数据1 colum1 = ['语文', '数学', '英语'] # 列标题1 data2 = np.random.randint(0, 101, size=[8, 2]) # 数据2 colum2 = ['化学', '物理'] # 列标题2 df1 = pd.DataFrame(data=data1, columns=colum1) df2 = pd.DataFrame(data=data2, columns=colum2) with pd.ExcelWriter('./score.xls') as writer: df1.to_excel(writer, sheet_name='sheet101', header=True, index=False), # 写入sheet1 df2.to_excel(writer, sheet_name='sheet102', header=True, index=False) # 写入sheet2
结果如下:


方法二:
代码如下(对应读取中的方法二):
import xlwt # 导入包 file1 = '/Users/zhangyang/PycharmProjects/untitled/abc2.csv' header = ['id', 'name'] content = [['1', 'zhangsan'], ['2', 'lisi'], ['3', 'wangmazi']] # 该方法对xlsx、xls、csv均适用 workbook = xlwt.Workbook(encoding='utf-8') # 1. 创建一个workboot对象(工作表) booksheet = workbook.add_sheet('sheet1', cell_overwrite_ok=True) # 2. 添加sheet页 row = 0 for col in range(len(header)): booksheet.write(row, col, header[col]) # 3. 写单元格(列头) for line in content: row += 1 for col in range(len(line)): booksheet.write(row, col, line[col]) # 3. 写单元格(内容) workbook.save(file1) # 4. 保存文件
写入结果如下: