余弦相似
先从句子开始,例如:
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
这俩句子是不是很像,那怎么定义这两句话的相似度呢
step 1: 分词
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
step 2:列出所有词
我,喜欢,看,电视,电影,不,也。
step 3:计算词频
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
step 4: 写出词频向量
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
到这里,问题就变成了如何计算这两个向量的相似程度。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
由:
我们有
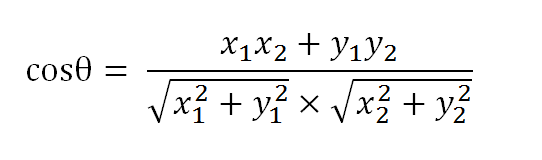
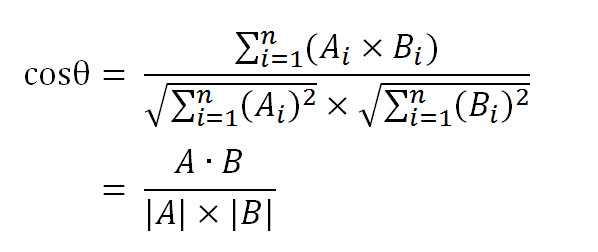
使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。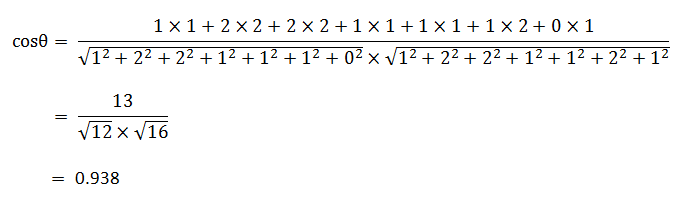
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
注记:
請教一下, 如果兩個向量長度不同怎麼處理呢?
不同的补0呗
简单的补0比较粗糙,在实际操作中通常用余弦定理的前提会是取n个最具代表行的词,例如20词/篇文章,这样以来向量长度就相等了。
要是在A句子中,“也”字之前加个“但”,向量偏差不大,可是句子偏差较大。其实根本问题是:为什么得到词频数列表后,问题就成了计算向量?
举例来说:如果要比较线段的长短,那么我们只需要1个维度(长)就可以;如果是比较平面图形,那么我们需要2个维度(长,宽);同理,比较立方体,那么就需要3个维度(长,宽,高)。
每个句子都可以被视为词的组成。因此,要比较句子,就必须先分解每个句子,统计出其中包含的词语(即维度)和词语出现的频率(即维度的值)。然后综合所有的词语,构建一个统一的n维坐标系,才能进行句子的比较。(如果某个句子不包含某个词语,那么它在这个词语维度上的值计为0)。
写的浅显易懂,不过这类技术在实际中很不实用,因为计算太慢。余弦只是一种距离公式,应用太窄了,还有编辑距离,欧氏距离等等
在实际中,相似度计算,一般是进行1对n的近似搜索,这个n是千亿级别的。
而用余弦作逐一比对是不可能的,所以常用的法则是对每个文档都要形成能用于比对的近似指纹,而这种指纹具有检索性能。
这个算法,貌似没有考虑到词的顺序,
比如
“我喜欢看电影” 和 “电影喜欢看我”
按照词频来统计的话,可能会完全相同,
不存在长度不一致问题,即使真的不一致,可进行补全处理,较少的向量补全0
这里是词袋模型,不考虑词之间的顺序
有个问题,用IF-IDF计算时,前提是分词分好的,可分词也是个问题。。。
jieba分词够用了,可以试试
中文并不像英文是以词为单位的,中文的词频统计是怎样实现的呢?
分词
如果已经有了一个词库(字典),那么这个算法应该就可以简单的实现了。假如没有词库,如何自动构造一个词库,比如“的”似乎不能作为一个有意义的词,但“的士”又是一个词。能否自动的识别汉语中的词,加入到词库中。静态的词库存在这样一个问题,因为不断会有新的词汇出现,这个词库很快就会跟不上形势了,而且单纯靠人工识别和处理新的词汇,显然不太可行。
写得很好,学习了!有个疑问,如果是很短的文本,例如微博,使用TF-IDF貌似就不适用了啊。比方说关于嫦娥三号登月的热门微博,有成千上万的人讨论这个话题,那么“嫦娥三号 登月”在每一篇出现的次数很少,即TF很小,与普通的词差别不大;而包含这个话题的帖子却很多,因为大家都在讨论这个话题,那么IDF就会很小,这样一来,没办法将本来重要的词提取出来了。请问博主有什么看法吗?
最近刚学自然语言处理。这种词可能是一些新出现的词语(比如人名),在语料库中没有现成的。而另一方面,分词算法如果足够好是能够识别出这些没有在语料库中出现的新词汇的,所以计算IDF时会遇到语料库中没有的词汇