分别用串行和并行实现了一个NUM次加法的程序,代码如下:
package main
import (
"fmt"
//"runtime" //执行并行段时需要引入该包
"time"
)
const (
NUM = 50//+运算次数
)
type vint struct {
n []int
}
func (v vint) Doadd(p, i, n int, u []int, c chan int) {
for ti := i; ti < n; ti++ {
v.n[p] += u[ti]
time.Sleep(1 * time.Second)
}
c <- 1
return
}
func (v vint) Doall(ncpu int, u []int) (sum int) {
c := make(chan int, ncpu)
var segment int
if NUM%ncpu == 0 {
segment = NUM / ncpu
} else {
segment = NUM / (ncpu - 1)
}
for i := 0; i < ncpu; i++ {
start := i * segment
temp := start + segment
var end int
if temp < NUM {
end = temp
} else {
end = NUM
}
go v.Doadd(i, start, end, u, c)
}
for i := 0; i < ncpu; i++ {
<-c
}
for i := 0; i < ncpu; i++ {
sum += v.n[i]
}
return
}
func main() {
//*并行段
/*ncpu := runtime.NumCPU()
runtime.GOMAXPROCS(ncpu)
u := make([]int, NUM)
for i := 0; i < NUM; i++ {
u[i] = 1
}
v := new(vint)
v.n = make([]int, ncpu)
ts := time.Now().UnixNano()
sum := v.Doall(ncpu, u)
te := time.Now().UnixNano()
fmt.Println((te - ts), sum)*/
//串行段
u := make([]int, NUM)
for i := 0; i < NUM; i++ {
u[i] = 1
}
ts := time.Now().UnixNano()
sum := 0
for i := 0; i < NUM; i++ {
sum += u[i]
time.Sleep(1 * time.Second)
}
te := time.Now().UnixNano()
fmt.Println((te - ts))
return
}
1亿*1000次(1亿次运算,重复1000次)的串行和并行执行的结果如下:
8核并行化时间: 105026.076ms 串行时间: 80704.4503ms
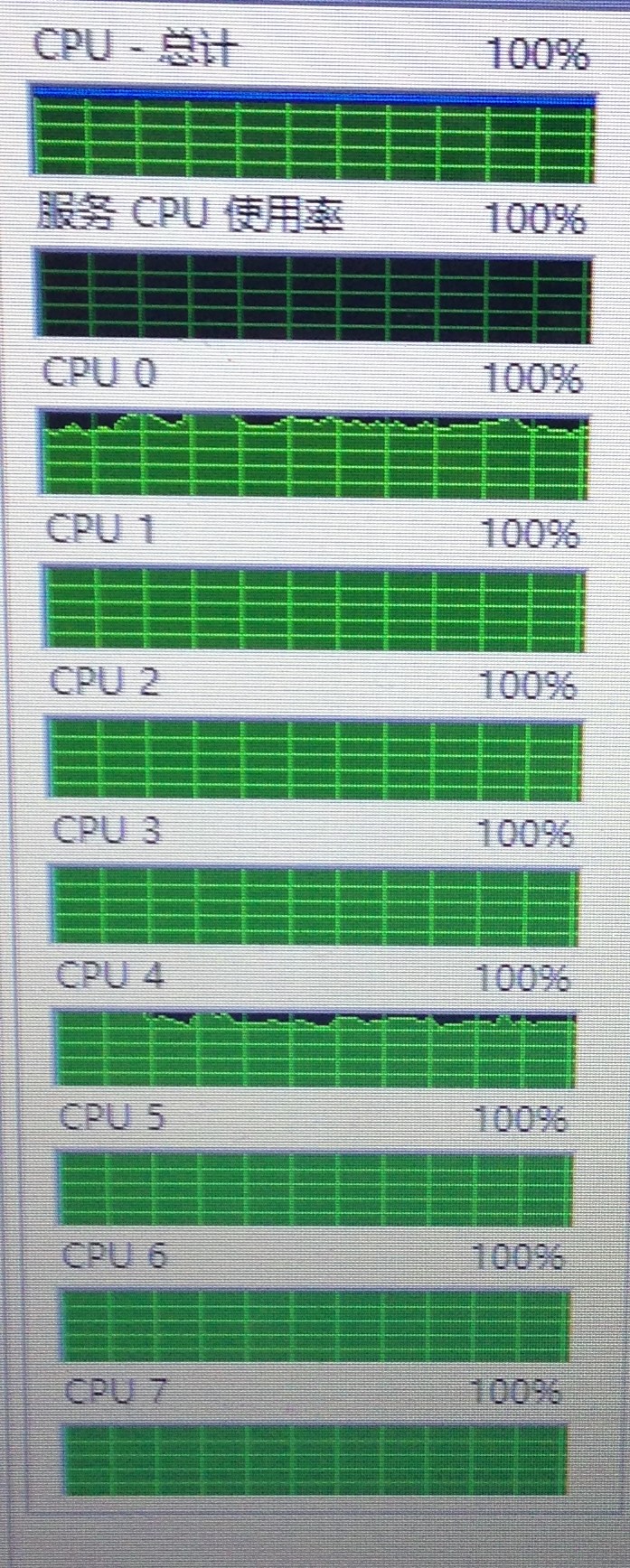

由结果可知,并行化的时间开销反而比串行大。
--------------------------------------------15/11/02更新---------------------------------------------
源自知乎回答,著作权归作者所有。
作者:赵雪松
链接:http://www.zhihu.com/question/37061750/answer/70294889
不请自来,go的并发主要是用来解决网络io等慢设备访问的等待问题的,而内存恰恰不属于这个部分。
作者:赵雪松
链接:http://www.zhihu.com/question/37061750/answer/70294889
不请自来,go的并发主要是用来解决网络io等慢设备访问的等待问题的,而内存恰恰不属于这个部分。
你算自加的这个过程完全是在内存里,并不能体现并发的威力,相反,开了那么多携程并行计算的话反
而会有不必要的调度开销,自然串行更快了。呐呐,我们来改一改,假设你的计算结果或数据是需要通
过网络来传递的,每次计算以后差不多有1秒的延迟(通过time.Sleep(1*time.Second)来模拟)。你再
比较一下试试。
根据以上建议对程序进行修改, 分别做50次“+”运算,结果如下:
串行:50017.7642ms(≈50s)
并行:7001.918ms(≈7s)
并行:7001.918ms(≈7s)
--------------------------------------------------------------------------------------------------------