一 python介绍
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
(龟叔:2005年加入谷歌至2012年,2013年加入Dropbox直到现在,依然掌握着Python发展的核心方向,被称为仁慈的独裁者)。
目前Python主要应用领域:
- 云计算: 云计算最火的语言, 典型应用OpenStack
- WEB开发: 众多优秀的WEB框架,众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。。。, 典型WEB框架有Django
- 科学运算、人工智能: 典型库NumPy, SciPy, Matplotlib, Enthought librarys,pandas
- 系统运维: 运维人员必备语言
- 金融:量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
- 图形GUI: PyQT, WxPython,TkInter
2 python是一门解释型 弱类型的编程语言.
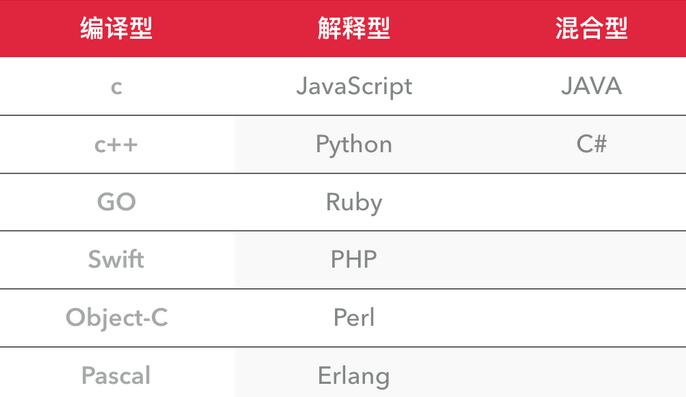
2.1 编译型与解释型。
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
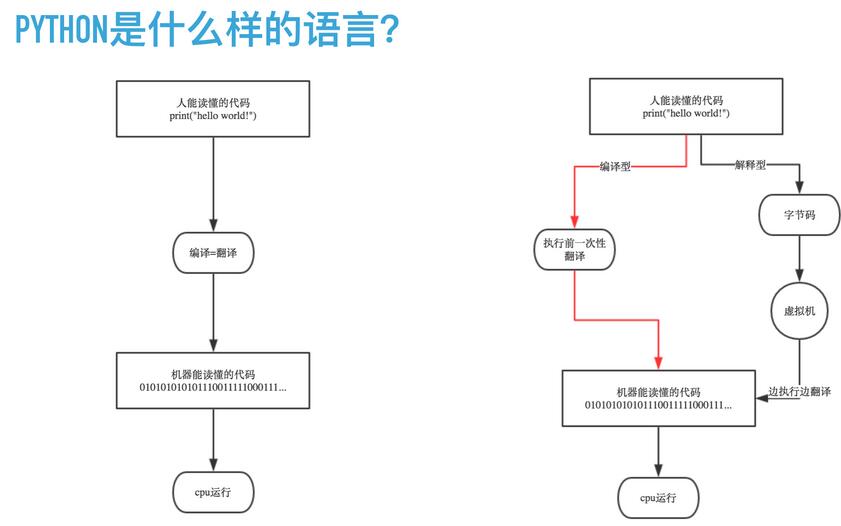
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
2.2动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
2.3强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。
3 python的种类
CPython
当我们从Python官方网站下载并安装好Python 3.6后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
小结:
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
4 单行注释和多行注释
当行注释:# 被注释内容,'注释内容' , “注释内容”
多行注释:'''被注释内容''',或者"""被注释内容"""
5 变量
变量是什么? 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
5.1、声明变量
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 name = "zhh"
上述代码声明了一个变量,变量名为: name,变量name的值为:"zhh"
变量的作用:昵称,其代指内存里某个地址中保存的内容
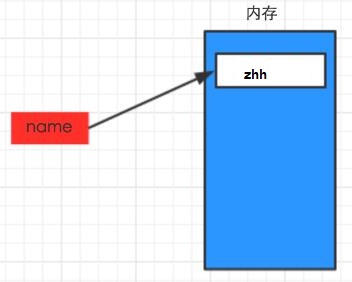
变量的命名规范
1 变量由字母,数字,下划线搭配组合而成
2 不可以用数字开头,更不能是全数字
3 不能是python的关键字,这些符号和字母已经被python占用,不可以更改
如:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
4 不要用中文
5 名字要有意义
6 不要太长
7 区分大小写
推荐大家使用驼峰体或者下划线命名
驼峰体:除首字母外的其他每个单词首字母大写
下划线:每个单词直接用下划线分开
推荐定义方式 驼峰体或下划线


#驼峰体 AgeOfZhh = 20 NumberOfStudents = 80 #下划线 age_of_students = 56 number_of_students = 80
2. 变量的数据类型:
①.int 整数:+,-,*,/,%(计算余数),//(整除)
②.str 字符串:',"",''',"""括起来的内容(注意:引号使用同一种在一个字符串中.)
字符串可以进行+,*.
'+'表示字符串之间的拼接 '*'表示相乘,字符串的内容的倍数.
③.bool 布尔值.只有真或者假,True和False.
3. 变量的赋值
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 name1 = "zhh" 5 name2 = "zhangqiang"
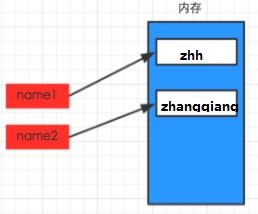
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 name1 = "zhh" 5 name2 = name1
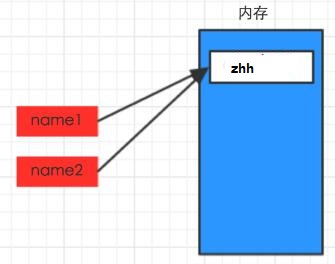
定义变量不好的方式举例
- 变量名为中文、拼音
- 变量名过长
- 变量名词不达意
6用户程序交互
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 # 将用户输入的内容赋值给 name 变量 5 name = input("请输入用户名:") 6 7 # 打印输入的内容 8 print(name)
将字符串转化成整数:str => int =>int(str) 例如
#让用户输入a,让用户输入b,计算机计算a+b的结果 a = input("请输入a:") #input收到的内容为str b = input("请输入b:") #将字符串转变成整数 int(字符串) c = int(a) + int(b) print(c)
字符串拼接
字符串可以进行"相加"和"相乘"运算。就是字符串的拼接 和字符串重复
>>> name 'zhh' >>> age '22' >>> >>> name + age #相加其实就是简单拼接 'zhh22' >>> >>> name * 5 #相乘其实就是复制自己多少次,再拼接在一起 'zhhzhhzhhzhhzhhzhh'
7 流程控制语句 if
1.语法一:
if 条件: #引号是将条件和结果分开
结果1. #四个空格,或者一个tab键,告诉程序满足这个条件
结果2
如果条件是真(True)执行结果1,然后结果2,如果条件假(False)直接结果2
2.语法二:
if 条件:
结果1
else:
结果2
代码3
print("咣咣咣,谁呀") gender = input("请问是男是女?") if gender == '男': print("请找隔壁") else: print("进来吧")
== 表示判断 = 表示赋值
3.语法三:
if 条件1:
结果1
elif条件2:
结果2
........
else:
结果n
例如
month = input("请输入一个月份") if month == '一月': print("吃香蕉") elif month == '二月': print("吃苹果") elif month == '三月': print("吃蛋糕") elif month =='四月': print("吃葡萄") .......... else: print("爱吃嘛吃嘛")
4.语句四--嵌套
if 条件1:
结果1
if 条件2:
结果2
else:
结果3
else:
结果4
print("咣咣咣, 谁呀? ") gender = input("请问, 你是男的还是女的?") if gender == '男': # pass # pass 过. 表示语法的完整性 print("男的去隔壁.") else: # 不是男的 age = input("今年贵庚了?") if int(age) > 48: # input接收的是字符串. 48是int. 这两个数据类型是不能比较的 print("大妈, 您找谁?, 可能在隔壁") else: print("我家的瓜, 特别甜.")
8 格式化输出
name = input("请输入名字:") age = input("请输入年龄:") job = input("请输入你的工作:") hobby = input("请输入你的爱好:") s = '''------------ info of %s ----------- Name : %s Age : %s job : %s Hobbie: %s ------------- end -----------------''' % (name, name, age, job, hobby)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
9 基本运算符
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
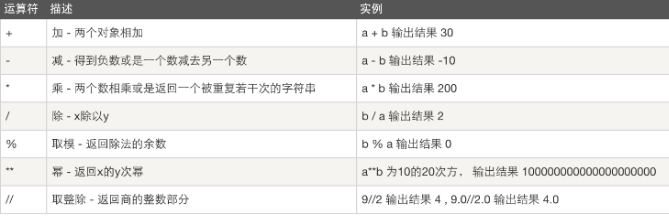
算数运算
以下假设变量:a=10,b=20
比较运算
以下假设变量:a=10,b=20

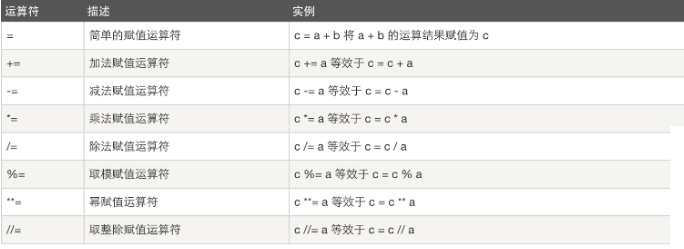
赋值运算
以下假设变量:a=10,b=20
逻辑运算

针对逻辑运算的进一步研究:
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
例题:
判断下列逻辑语句的True,False。
1 1,3>4 or 4<3 and 1==1 2 2,1 < 2 and 3 < 4 or 1>2 3 3,2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 4 4,1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8 5 5,1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 6 6,not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2 , x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。
注: 只记住 x or y 即可,and 跟or相反
10 流程控制之while 循环
10.1. 循环
while 条件:
代码块(循环体)
else:
当上面的条件为假. 才会执行
执行顺序:
判断条件是否为真. 如果真. 执行循环体. 然后再次判断条件....直到循环条件为假. 程序退出
1 count = 1 2 while count <= 5: 3 print(count) 4 count = count + 1 5 6 7 8 结果: 9 2 10 4
10.2,循环中止语句
如果在循环的过程中,因为某些原因,你不想继续循环了,怎么把它中止掉呢?这就用到break 或 continue 语句
- break用于完全结束一个循环,跳出循环体执行循环后面的语句
- continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
1 while True: 2 content = input("请输入一句话,(输入q结束):") 3 if content == 'q': 4 break 5 print(content) 6 7 8 9 10 结果: 11 请输入一句话,(输入q结束):是的 12 是的 13 请输入一句话,(输入q结束):呵呵 14 呵呵 15 请输入一句话,(输入q结束):q 16 17 Process finished with exit code 0
例子:continue
while True: content = input("输入一句话,(输入q结束):") if content == 'q': continue print(content) 结果: 输入一句话,(输入q结束):13 输入一句话,(输入q结束):13 输入一句话,(输入q结束):55 输入一句话,(输入q结束):q 输入一句话,(输入q结束):
当想排除某个内容是也可以用continue.
count = 1 while count <= 10: if count == 5: count += 1 continue # 用来排除一些内容 print(count) count += 1 结果: 2 4 7 9 Process finished with exit code 0
3.while........else......语句
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
但是,当中间有break时,会直接退出while...else...语句(while..else..属于一个整体)
count = 1 while count <= 5: count = count + 1 print(count) else: print("结束了") 结果: 3 5 结束了
count = 1 while count <= 7: count = count + 1 if count == 4: break print(count) else: print("结束了,撒花") print("完蛋了") 结果: 3 完蛋了 Process finished with exit code 0
11 内容编码
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
1. ascii. 最早的编码. 至今还在使用. 8位一个字节(字符)
2. GBK. 国标码. 16位2个字节.
3. unicode. 万国码. 32位4个字节
4. UTF-8. 可变长度的unicode.
英文: 8位. 1个字节
欧洲文字:16位. 2个字节
汉字. 24位. 3个字节
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python # -*- coding: utf-8 -*-