这篇博文详细分析了前馈神经网络的内容,它对应的函数,优化过程等等。
在上一篇博文中已经完整讲述了 SVM 的思想和原理。讲到了想用一个高度非线性的曲线作为拟合曲线。比如这个曲线可以是:
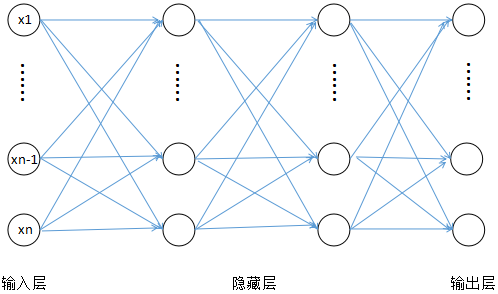
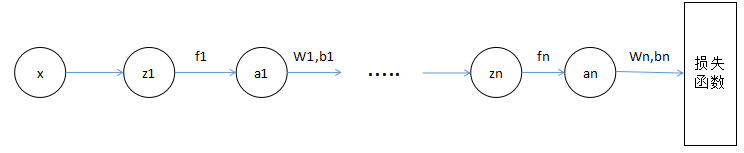
[g(x)=w_3(f_2(w_2(f_1(w_1x_1+b_1))+b2))+b3
]
这个函数的 (x), (b) 是向量,(w) 是矩阵,最后得到的结果是向量。(f_1) 和 (f_2) 是 sigmoid 函数或者阶跃函数等非线性函数。这里就只复合三层,其实可以一直复合下去。它用一个图表示就是下面的神经网络:
- 优化的时候计算性能要求很高。所以这个算法在发明的时候并没有特别火,现在随着计算机性能的提高,才有了商业价值。
- 梯度消失。这个是指层数太多的时候,最后几层的参数会调的比较好,所以在反向传播的时候残差会越来越小,以至于前面几层的参数很难调好。所以结果还不如用浅层的。
- 参数过多,很容易陷入局部最优解。
针对这些问题,有很多特殊的神经网络,这些网络的层数可以很深,还有各种特殊的结构。这个就是深度学习。比较常见的有循环神经网络(RNN)、卷积神经网络(CNN)、自编码器等。这些网络结构各有各的优点和用处,但是基本流程和优化方法还是跟神经网络差不多,这里就不赘述了。这个系列到这里就结束了~,自编码器、CNN 之类的以后结合 tensorflow 再写吧。
参考链接:
如需转载,请注明出处.
出处:http://www.cnblogs.com/xinchen1111/p/8793570.html