很多时候在写Python程序的时候都要在头部添加这样一行代码
#coding: utf-8
或者是这样
# -*- coding:utf-8 -*-
等等
这行代码的意思就是设定同一编码格式为utf-8
计算机中存储数据的编码方式多种多样, 常用的有 unicode, utf-8, gbk, 等等
在Windows系统下,文本文件默认保存的格式应该是gbk
在以一种编码格式保存文件时,应该使用相同的编码进行解析此文件, 不然可能会出现乱码情况
今天就是想记录一下我在写Python程序时,在解析字符串字符串时何时使用decode, 何时使用encode
通常从非unicode编码转换为unicode编码使用decode(解码),相反从unicode编码转换为非unicode编码使用encode(编码)
#coding: utf-8 L = ['你好'] print L
输出
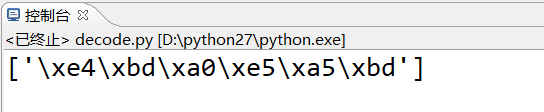
现在是utf-8编码, 一个汉字占3个字节
使用decode进行解码,将 “你好” 的编码转换为unicode
#coding: utf-8 L = ['你好'] print [L[0].decode('utf-8')]
输出

可以看到成功转化为unicode编码, 并且一个汉字占2个字节
那我现在想让utf-8编码的 “你好” 转换为gbk该如何操作呢?
这样试一下
#coding: utf-8 L = ['你好'] print [L[0].encode('gbk')] #错误示例
出现了错误

正确的方式就是先将 utf-8 使用decode转换为 unicode , 在将 unicode 使用encode转换为想要的编码gbk
#coding: utf-8 L = ['你好'] print [L[-1].decode('utf-8').encode('gbk')] # utf-8 -> unicode -> gbk
输出
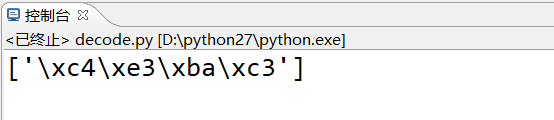
成功转化为gbk编码, 并且一个汉字占2个字节
总结:
(非unicode编码).decode('非unicode') 转换为unicode
(unicode编码).encode('非unicode') 转换为非unicode
如果想要从一种非unicode编码转换为另外一种非unicode编码, 需要借助unicode作为跳板先进行decode, 再进行encode
本节完......